Organizations depend heavily on data for predicting trends, planning for future requirements, making business decisions, understanding consumers, and predicting the market. However, to execute these tasks, it is necessary to get fast access to enterprise data in a single location. This is where Data Ingestion comes in handy. It refers to the extraction of information from disparate sources so that you can uncover actionable insights hidden within your data and use them for your unique business case to propel growth.
This article talks about the different salient aspects of Data Ingestion in detail such as its types, benefits, importance, working, challenges, key tools to look out for, and so much more.
Table of Contents
What is Data Ingestion?
Data Ingestion is defined as the process of absorbing data from a vast multitude of sources and transferring it to a target site where it can be analyzed and deposited. Generally speaking, the destinations can either be a document store, database, Data Warehouse, Data Mart, etc. You can also choose from different source options such as Web Data Extraction, spreadsheets, Web Scraping, SaaS data, and in-house apps.
Enterprise data can usually be stored in multiple formats and sources. For instance, sales data is stored in Salesforce.com, Relational Database Management Systems stores product information, etc. Since this data originated from various locations, it needs to be spruced and converted into a format that can be easily analyzed for decision-making with the help of an easy-to-use Data Ingestion tool like Hevo Data. Otherwise, you would be left with puzzle pieces that cannot be collated together.
Data Ingestion Architecture & Patterns
To effectively and efficiently ingest data from your various sources into a target system, you can use a data ingestion framework. It is a set of processes that allows you to consistently and reliably get data into the target system, regardless of the complexity or volume of the data sources. A basic well-defined data ingestion architecture includes the following data layers:
- Data Ingestion Layer: Responsible for extracting data from multiple sources into your data pipeline.
- Data Collection Layer: This handles the collection and storage of data in a temporary staging area.
- Data Processing Layer: Consisting of functions such as data transformation logic and quality checks, this layer prepares the data for storage.
- Data Storage Layer: Takes care of storing data in repositories such as databases, data warehouses, and data lakes.
- Data Query Layer: Offering SQL Interfaces and BI tools, this layer provides you access to the stored data for querying and analysis.
- Data Visualisation: This layer allows you to make reports and dashboards to present the data in a meaningful and understandable way to users.
Parameters of Data Ingestion
To effectively implement a data pipeline, you have to fine-tune your data ingestion architecture. You can do that by going through the following parameters of data ingestion:
- Data Volume: The amount of data being ingested. This could be measured in terms of the size of the data, the number of records or rows, or the rate at which data is ingested.
- Data Frequency: It is the frequency at which you need fresh or updated data. You can either do the near-real-time replication or go for the batch mode processing, where data is first stored in batches and then moved into the pipelines.
- Data Velocity: It refers to the rate at which data is generated, transmitted, and processed.
- Data Format: The format in which the data is stored or transmitted. This could be a structured format, such as CSV or JSON, or an unstructured format, such as text or binary data.
What are the Types of Data Ingestion?
It can be executed in various ways, such as in real-time, batches, or a combination of both (also known as lambda architecture) based on the unique business requirements of the user. This section will be taking a closer look at the different types of Data Ingestion to help you get started with them.
Batch-based Data Ingestion
When this process takes place in batches, the data is moved at recurrently scheduled intervals. This approach comes in handy when tackling repeatable processes. For example, reports that need to be generated daily.
Real-time/Streaming Data Ingestion
Data Ingestion executed in real-time is also referred to as Streaming data among the developers. Real-time ingestion plays a pivotal role when the data collected is very time-sensitive. Data is processed, extracted, and stored as soon as it is generated for real-time decision-making. For instance, data acquired from a power grid needs to be continuously monitored to ensure a steady flow of power.
Lambda-based Data Ingestion Architecture
The Lambda architecture balances the advantage of the aforementioned methods by leveraging Batch Processing to offer broad views of batch data. On top of this, Lambda architecture uses real-time processing to offer views of time-sensitive information as well.
Hevo Data, a Fully-managed Data Pipeline platform, can help you automate, simplify & enrich your data replication process in a few clicks. With Hevo’s wide variety of connectors and blazing-fast Data Pipelines, you can extract & load data from 100+ Data Sources straight into your Data Warehouse or any Databases. To further streamline and prepare your data for analysis, you can process and enrich raw granular data using Hevo’s robust & built-in Transformation Layer without writing a single line of code!
GET STARTED WITH HEVO FOR FREE
Hevo is the fastest, easiest, and most reliable data replication platform that will save your engineering bandwidth and time multifold. Try our 14-day full access free trial today to experience an entirely automated hassle-free Data Replication!
Good Ingestion tools should be scalable, secure, and should support multiple data sources, and above all, should be very easy to use with a minimal learning curve.
Here are a couple of Data Ingestion tools that you need to look out for in 2022 as some of the best in the market:
Sign up here for a 14-Day Free Trial!
What are the Benefits of Data Ingestion?
Here are a few key advantages of using Data Ingestion for your business use case:
- Data Ingestion helps a business gain a better understanding of its audience’s needs and behavior to stay competitive which is why ample research needs to be done when looking up companies that offer Data Ingestion services.
- Data Ingestion also enables a company to make better decisions, create superior products, and deliver improved customer service.
- Data Ingestion automates some of the tasks that previously had to be manually executed by engineers, whose time can now be dedicated to other more pressing tasks.
- Engineers can also use Data Ingestion to ensure that their software tools and apps move data quickly and provide users with a superior experience.
Real-World Industry & Architectural Use Cases of Data Ingestion
Data Ingestion is being widely used in organizations worldwide as a critical part of their data pipelines, namely:
- Big Data Analytics: Ingesting large volumes of data from multiple sources is a common requirement in big data analytics, where data is processed using distributed systems such as Hadoop or Spark.
- Internet of Things (IoT): Data ingestion is often used in IoT systems to collect and process data from a large number of connected devices.
- E-commerce: E-commerce companies may use data ingestion to import data from various sources, including website analytics, customer transactions, and product catalogs.
- Fraud detection: Data ingestion is often used in fraud detection systems to import and process data from multiple sources, such as transactions, customer behavior, and third-party data feeds.
- Personalization: Data ingestion can be used to import data from various sources, such as website analytics, customer interactions, and social media data, to provide personalized recommendations or experiences to users.
- Supply Chain Management: Data ingestion is often used in supply chain management to import and process data from various sources, such as supplier data, inventory data, and logistics data.
Data Ingestion vs Data Integration
Data Ingestion originated as a small part of Data Integration, a more complex process needed to make data consumable in new systems before loading it. Data Integration usually needs advanced specifications from source to schema to transformation to destination.
When comparing data ingestion vs data integration, Data Ingestion allows only a few light transformations, such as masking Personally Identifiable Information (PII), but most of the work depends on the end-use and takes place after landing the data.
Challenges Companies Face while Ingesting Data
Maintaining and setting up a Data Ingestion pipeline might be much simpler than before, but it still comes with its fair share of data ingestion challenges:
- Scalability: When dealing with Data Ingestion on a large scale, it can be a little difficult to ensure data consistency and make sure that the data conforms to the structure and format that the destination application needs. Large-scale Data Ingestion could also suffer from performance challenges.
- Data Quality: Maintaining data completeness and data quality during Data Ingestion is a significant challenge. Checking data quality needs to be a part of the Data Ingestion process to allow useful and accurate analytics.
- Risk to Data Security: Security is one of the biggest challenges that you might face when moving data from one point to another. This is because data can often be staged in various phases throughout the ingestion process. This can make it challenging to fulfill compliance standards during the Data Ingestion process.
- Unreliability: Incorrectly ingesting data might lead to unreliable connectivity. This can end up disrupting communication and cause loss of data.
- Data Integration: It might be a little difficult to integrate data from various third-party sources into the same Data Pipeline, which is why you need a comprehensive Data Ingestion tool that allows you to do just that.
To tackle all the aforementioned challenges to ensure seamless Data Ingestion for your unique business use case, you can give Hevo Data a try. Here’s how Hevo Data sizes up:
- Scalability: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- High Data Quality: Hevo ensures the highest quality of data in the process of migrating data from a designated source to a destination of your choice.
- Robust Data Security: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner.
- Reliability: The Hevo platform can be set up in just a few minutes and requires minimal maintenance. Hevo’s robust infrastructure ensures reliable data transfer with zero data loss.
- Comprehensive Data Integration: Hevo supports 100+ Integrations from sources to SaaS platforms, files, databases, and analytics. It supports various destinations including Amazon Redshift, Firebolt, Snowflake Data Warehouses; Databricks, Amazon S3 Data Lakes, SQL Server, TokuDB, and DynamoDB databases to name a few.
Best Data Ingestion Tools: 5 Must-see Options
Here are the 5 best Data Ingestion tools you need to watch out for in 2022:
- Hevo Data
- Apache Nifi
- Apache Flume
- Elastic Logstash
- Wavefront
1. Hevo Data
 Image Source
Image Source
Hevo Data, a No-code Data Pipeline helps to transfer data from 100+ sources to a Data Warehouse/Destination of your choice. Hevo is fully managed and completely automates the process of not only loading data from your desired source but also enriching the data and transforming it into an analysis-ready form without even having to write a single line of code. Its fault-tolerant architecture ensures that the data is handled in a secure, consistent manner with zero data loss.
It provides a consistent & reliable solution to manage data in real-time and always have analysis-ready data in your desired destination. It allows you to focus on the key business needs and perform insightful analysis.
Get Started with Hevo for Free
Here are a few key features of Hevo Data:
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Minimal Learning: Hevo, with its simple and interactive UI, is extremely simple for new customers to work on and perform operations.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
- Live Monitoring: Hevo allows you to monitor the data flow and check where your data is at a particular point in time.
2. Apache Nifi
 Image Source
Image Source
Apache Nifi is considered one of the best Data Ingestion tools that offer an easy-to-use, reliable, and powerful system to distribute and process information. Apache Nifi supports scalable and robust directed graphs of data transformation, routing, and system mediation logic. Here are a few key features of Apache Nifi:
- The seamless experience between control, design, monitoring, and feedback.
- Apache Nifi can track data flow from the beginning to the end.
- Apache Nifi is considered very secure because of SSH, SSL, encrypted content, and HTTPS.
3. Apache Flume
 Image Source
Image Source
Apache Flume is a reliable, distributed, and available service for efficiently aggregating, collecting, and moving large amounts of data. It has a flexible and straightforward architecture based on streaming data flows. Apache Flume is fault-tolerant and robust with tunable reliability mechanisms along with many failovers and recovery mechanisms.
It leverages a simple, extensible Big Data Security model that allows for an online analytic application and Data Ingestion process flow. Here are a few key features of Apache Flume:
- Buffer storage platform from transient spikes when the rate of incoming data exceeds the rate at which the data can be written to the destination.
- You can ingest the streaming data from multiple sources into Hadoop for analysis and storage.
- For new Data Ingestion streams, you can look to scale it horizontally as needed.
4. Elastic Logstash
 Image Source
Image Source
Elastic Logstash is an open-source Data Ingestion tool, a server-side data processing pipeline that ingests data from various sources, simultaneously transforms it, and then sends it to your “stash”, i.e. ElasticSearch. Here are a few key features of Elastic Logstash:
- Multiple AWS services can be carried out in a streaming, continuous fashion.
- Elastic Logstash can easily ingest from your logs, web applications, metrics, and data stores.
- It can ingest data from all the different types of sources in all shapes and sizes.
5. Wavefront
 Image Source
Image Source
Wavefront is a high-performance, cloud-hosted streaming analytics service that can be used for storing, ingesting, visualizing, and monitoring all forms of metric data. The platform is impressive for its ability to scale to very high Data Ingestion rates and query loads, hitting millions of data points per second.
Here are a few key functions of Wavefront:
- Wavefront allows users to collect data from over 200 services and sources, including DevOps tools, Big Data services, Cloud Service providers, and much more.
- Wavefront also allows users to look at data in custom dashboards, get alerts on problem values, and execute functions such as forecasting and anomaly detection.
There are multiple data ingestion tools available in the market, but which one is the optimal choice for your business? You can simplify this process by going through the following pointers:
- Clearly formulate your business goals and objectives for your data ingestion process, including the data sources, data formats, and data volumes you need to handle.
- Go for a data ingestion tool that has a more beginner-friendly interface and an in-built data cleansing system that can be easily operated by business users, thereby reducing dependency on the technical team.
- The tool should meet your data security requirements with data governance and safety protocols in place.
- Choose a tool that can integrate with your existing systems and infrastructure. This will make it easier to incorporate data ingestion into your existing workflows and processes.
- Try out a few different tools to see which one works best for your needs. Many tools offer free trial versions that you can use to test their features and capabilities.
Best Practices for Data Ingestion: 5 Must-know Strategies
Here are the best practices for Data Ingestion to ensure your pipeline runs smoothly:
- Automate the Process: As the data continues to grow in both complexity and volume, you can no longer depend on manual techniques to curate such a huge amount of data. Therefore, you can consider automating the entire process to increase productivity, save time, and reduce manual efforts. For instance, if you wish to extract data from a delimited file stored in a folder, transfer and cleanse it into the SQL Server. This process needs to be repeated every time a new file is dropped in the folder. By leveraging a Data Ingestion tool you can automate the process by using event-based triggers that can help optimize the entire ingestion cycle.
- Anticipate Difficulties: The prerequisite of analyzing data is transforming it into a useable form. As the data volume increases, this part of their job becomes more difficult. Therefore, anticipating difficulties and planning accordingly is essential to its successful completion. The first step of developing a data strategy would be to outline the challenges associated with your specific use case difficulties and take them into stride. For example, identify the source systems at your disposal and make sure you know how to extract data from these sources. You can also acquire external expertise or leverage a code-free Data Integration tool to help with the process.
- Enable Self-service Data Ingestion: Your business might require various new data sources to be ingested weekly. And if your company functions on a centralized level, it might run into trouble in performing every request. Therefore, automating the process or opting for self-service Data Ingestion can empower business users to handle the process with minimal intervention from the IT team.
- Choose the Right Data Format: Data Ingestion tools need to provide a suitable data serialization format. Generally, data comes in the variable format, so converting them into a single format will offer an easier view to relate or understand the data.
- Latency: Fresh data guarantees more agile business decision-making. Extracting data from databases and APIs in real-time can be quite difficult. Various target data sources including large object-stores like Amazon S3 and analytics databases like Amazon Athena Redshift can be optimized for receiving data in chunks as opposed to a stream.
Data Ingestion FAQs
Batch vs Streaming Data Ingestion: What is the Difference?
Business constraints and requirements inform the structure of a particular project’s Data Ingestion layer. The correct ingestion model supports an optimal data strategy, and businesses typically select the model that’s apt for each data source considering the timeliness with which they’ll need analytical access to the data:
- Real-time Processing is also known as Stream Processing does not involve the grouping of data. Data is manipulated, sourced, and loaded as soon as it’s generated or recognized by the Data Ingestion layer. This kind of ingestion is considered more expensive since it requires systems to constantly monitor sources and accept new information. However, it might be appropriate for analytics that needs continually refreshed data.
- The most common kind of Ingestion process is Batch Processing. Here, the ingestion layer regularly collates and groups source data and moves it to the destination systems. Groups may be processed based on any logical ordering, the activation of specific conditions, or a simple schedule. When having near-real-time data isn’t important, Batch Processing is typically used because it is generally more affordable and easier to implement compared to Stream Processing.
- It is also worth noting that a couple of streaming platforms like Apache Spark Streaming leverage Batch Processing. Here the ingested groups are simply smaller or are prepared at shorter intervals, but still not processed individually. This type of processing is called micro batching and is considered by some to be another distinct category of Data Ingestion.
Why do you need a Data Ingestion Layer?
Here are a few reasons why a Data Ingestion Layer might be integral to the smooth functioning of your Data Pipeline:
- Uniformity: A high-quality process can easily turn different types of data into unified data that is easy to read and execute statistics and manipulations on.
- Availability: The data can be availed by all the users with the help of a Data Ingestion layer: developers, BI analysts, sales teams, and anyone else in the company.
- Saves Time and Money: A Data Ingestion process saves valuable time for the engineers trying to collate data they need and develop it efficiently instead.
How Does Data Ingestion Work?
Data Ingestion extracts data from the source where it was generated or originally stored and loads data into a staging area or destination. A simple Data Ingestion pipeline might apply one or more light transformations that would filter or enrich the data before writing to a set of destinations, a message queue, or a data store. More complex transformations such as aggregates, joins, and sorts for specific applications, analytics, and reporting systems can be performed with supplementary pipelines.
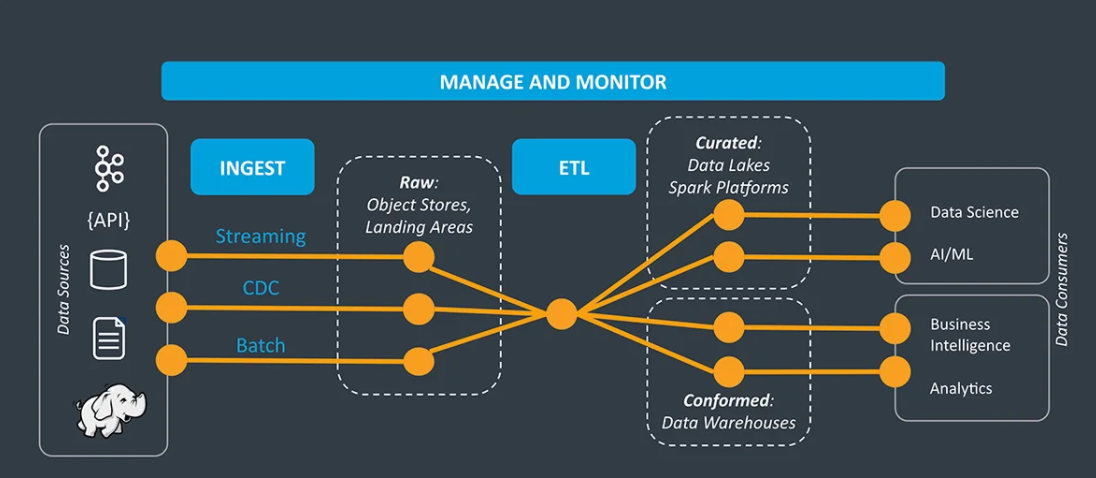 Image Source
Image Source
Data Ingestion vs ETL: What Sets them Apart?
Data Ingestion tools might bear resemblance to ETL tools in terms of functionality, but there are a few pivotal differences that set them apart. Data Ingestion is primarily concerned with extracting data from the source and loading it into the target site. ETL, on the other hand, is a type of Data Ingestion process that consists of not only the extraction and transfer of data but also the transformation of that data before it gets delivered to the target.
Conclusion
This article talks in detail about the different pivotal aspects of Data Ingestion such as types, challenges, process, purpose, key tools, importance, and benefits to name a few.
Extracting complex data from a diverse set of data sources to carry out an insightful analysis can be a challenging task and this is where Hevo saves the day! Hevo Data, a No-code Data Pipeline can seamlessly transfer data from a vast sea of 150+ sources to a Data Warehouse, or a Destination of your choice. It is a reliable, completely automated, and secure service that doesn’t require you to write any code!
Visit our Website to Explore Hevo
Hevo can effortlessly automate data ingestion for you. Hevo, with its strong integration with 150+ sources (Including 40+ Free Sources), allows you to not only export & load data but also transform & enrich your data & make it analysis-ready in a jiffy. Want to take Hevo for a ride? Sign Up for a 14-day free trial and simplify your Data Integration process. Do check out the pricing details to understand which plan fulfills all your business needs.
Amit is a Content Marketing Manager at Hevo Data. He enjoys writing about SaaS products and modern data platforms, having authored over 200 articles on these subjects.