

AWS Kinesis is a set of managed services that allows you to collect and process streaming data in real time. Big Data is fueled by streaming data processing platforms. Streaming data can be collected from website click-throughs, marketing, and financial information, social media feeds, Internet of Things sensors, and operations logs.
In this article, you will gain information about AWS Kinesis. You will also gain a holistic understanding of streaming data, different components of Kinesis, streams, shard, and record, and the usage of Kinesis PutRecord Command.
Read along to find out in-depth information about the AWS Kinesis PutRecord command.
Table of Contents
What is Streaming Data?
The phrase “streaming data” refers to data generated in real-time by multiple data sources sending data records in real-time (in a stream). Data streaming is continuous and therefore the data sent in streams is called unbounded data instead of batch (or batch-processed) data.
Some of the different kinds of data that can be sent in streams are as follows:
- Data generated by customers’ mobile devices or web applications.
- The activity of customers on e-commerce sites.
- The activity of in-game players.
- Facebook and Twitter feed.
- Financial market data in real-time.
- Geospatial feeds of location information.
- Telemetry data is collected from connected devices.
A streaming dataset can be handled one record at a time, sequentially and progressively, or in huge batches aggregated across a sliding time window.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s No-Code Automated Data Pipeline empowers you with a fully-managed solution for all your data collection, processing, and loading needs.
Hevo’s native integration with AWS S3 and AWS Elasticsearch empowers you to transform and load data straight to a Data Warehouse such as Redshift, Snowflake, BigQuery & more!
Our platform has the following in store for you:
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Transformations: Hevo provides preload transformations to make your incoming data from AWS S3 and AWS Elasticsearch fit for the chosen destination. You can also use drag and drop transformations like Date and Control Functions, JSON, and Event Manipulation to name a few.
- Scalable Infrastructure: Hevo has in-built integrations for 150+ sources (with 60+ free sources) that can help you scale your data infrastructure as required.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
What is AWS Kinesis?

Kinesis is a service provided by Amazon Web Services that collects, processes, and analyses streaming data. By leveraging Kinesis, you can get timely insights into your data, whether they’re scheduled or event-based, and take action based on those insights, just like with all the other services.
AWS Kinesis offers four specialized services categorized roughly by types and stages of streaming data processing. Those are as follows:
- Kinesis Data Streams (KDS)
- Kinesis Data Firehose (KDF)
- Kinesis Data Analytics (KDA)
- Kinesis Video Sreams (KVS)
1) Kinesis Data Streams (KDS)
With Kinesis Data Streams, a variety of streaming data sources can be captured in real-time. Data is written to the Kinesis Data Stream by producer applications and then read by consumer applications for various types of processing.
2) Kinesis Data Firehose (KDF)
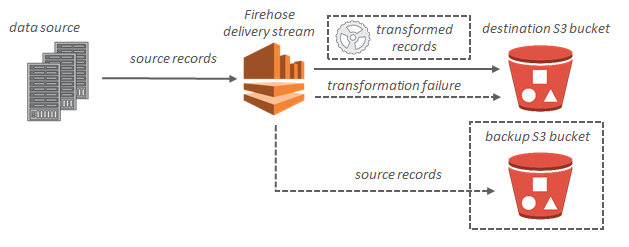
Kinesis Data Firehose eliminates the need to write applications and manage resources. The data producers submit the data to Kinesis Data Firehose, and the data is automatically delivered to the destination. Additionally, Kinesis Data Firehose can also be configured to transform the data before sending it.
3) Kinesis Data Analytics (KDA)
Streaming data can be processed and analyzed with Kinesis Data Analytics. The Apache Flink framework provides useful operators for querying streaming data, including the map, filter, aggregate, window, etc., which makes it possible to run applications efficiently and with flexible scalability.
4) Kinesis Video Streams (KVS)
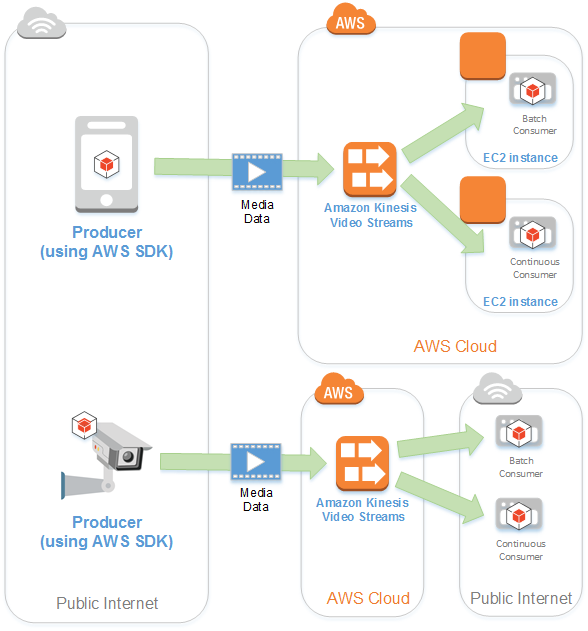
The Kinesis Video Streams service allows you to stream live video to the AWS Cloud from video and audio-capturing devices or build applications for online video analysis or real-time video processing.
Understanding Streams, Shards, and Records
Kinesis Data Streams (KDS) is designed so that you can set up a data stream and build producer applications that push data to it and consumer applications that read and process that data.
There are many data carriers in Kinesis Data Streams called shards. However, there is a fixed amount of capacity according to each shard. The number of shards in a data stream determines a stream’s data capacity. The sum of all the capacities of the shards makes up the data stream’s total capacity.
A shard of data is called a record. A shard consists of several data records. Kinesis Data Stream assigns a sequence number to each data record.
AWS Kinesis PutRecord Command
In order to write a single record i.e., a data record into an Amazon Kinesis data stream, the Kinesis PutRecord command is used. Kinesis PutRecord command enables real-time ingestion and subsequent processing of business records as they arrive one at a time. The maximum number of records that a shard can support is 1,000 records per second, which implies that a maximum of one megabyte per second can be written to the data.
The stream name must be specified, a partition key must be specified, and the data blob itself must be specified along with the Kinesis PutRecord command. You can define a data blob as information of any type, for example, a segment from a log file, geographic or location data about a location, website clickstreams about a website, etc.
Using partition keys, Kinesis Data Streams distributes data between shards. Data Streams uses the partition keys associated with each data record to partition data records into shards. In Kinesis Data Streams, the partition key specifies which shard each data record belongs to.
A partition key can be a string up to 256 characters long, which is a Unicode set of characters. For partition keys, MD5 is used to map them to 128-bit integer values, and for data records, MD5 is used to map them to shards using hash key ranges. In order to determine the shard, you can use the ExplicitHashKey parameter to explicitly specify a hash value instead of calculating the partition key. The PutRecord function returns the shard ID and the sequence number of the placed data record.
The different points to be considered while using AWS Kinesis PutRecord Command is as follows:
1) Request Syntax
{
"Data": blob,
"ExplicitHashKey": "string",
"PartitionKey": "string",
"SequenceNumberForOrdering": "string",
"StreamName": "string"
}
2) Request Parameters
The request takes JSON data in the following format.
- Kinesis PutRecord Command: Data
- Kinesis PutRecord Command: ExplicitHashKey
- Kinesis PutRecord Command: PartitionKey
- Kinesis PutRecord Command: SequenceNumberForOrdering
- Kinesis PutRecord Command: StreamName
A) Data
When serializing the data blob, base64-encoding is performed, resulting in a base64-coded record. The size of the data blob (the payload before base64 encoding) must not exceed the maximum record size (1 MiB) when added to the partition key size.
- Type: Binary data object encoded in Base64
- Length Constraints: The minimum length is 0 while the maximum length is 1048576.
- Required: Yes
B) ExplicitHashKey
A hash value is used to override the partition key hash to determine which shard a data record belongs to.
- Type: String
- Pattern: 0|([1-9]d{0,38})
- Required: No
C) PartitionKey
Data records are assigned PartitionKeys based on which shard they belong to. Each partition key can contain up to 256 characters in Unicode. Streams are mapped to specific shards using a hash function generated by Amazon Kinesis Data Streams using the partition key.
Partition keys are mapped to 128-bit integer values using the MD5 hash function, and associated data records are mapped to shards using the MD5 hash function. In practice, all information with the same partition key maps to the same shard within the stream as a result of this hashing mechanism.
- Type: String
- Length Constraints: The Minimum length is 1. The maximum length is 256.
- Required: Yes
D) SequenceNumberForOrdering
A strict increasing sequence number will be guaranteed for puts from the same client and partition key. This lets you set the SequenceNumberForOrdering of record n to the sequence number for record n-1 (as returned when record n-1 is inserted). In the absence of this parameter, records are sorted by arrival time.
- Type: String
- Pattern: 0|([1-9]d{0,128})
- Required: No
E) StreamName
This is the name of the stream where the data record should go.
- Type: String
- Length Constraints: Minimum length of 1. The maximum length of 128.
- Pattern: [a-zA-Z0-9_.-]+
- Required: Yes
3) Response Syntax
{
"EncryptionType": "string",
"SequenceNumber": "string",
"ShardId": "string"
}
4) Response Elements
Upon successful completion of the action, the service returns an HTTP 200 response.
JSON data is returned from the service in the following format.
- Kinesis PutRecord Command: EncryptionType
- Kinesis PutRecord Command: SequenceNumber
- Kinesis PutRecord Command: ShardID
1) EncryptionType
A record’s encryption type. A record’s encryption type can be one of the following:
- ‘NONE’: Do not encrypt the stream records.
- AWS KMS: Encrypt the records in the stream on the server side using a customer-managed AWS KMS key.
- Type: String
- Valid Values: NONE | KMS
2) SequenceNumber
The sequence number for the data record that was put into the database. Every record in the stream has the same sequence number. Each record in a stream is assigned a sequence number.
- Type: String
- Pattern: 0|([1-9]d{0,128})
3) ShardId
This is the shard ID for the shard containing the data record.
- Type: String
- Pattern: shardId-[0-9]{12}
Examples
Adding data to a stream
Adding data to the stream using JSON is demonstrated in the following example.
Sample Request
POST / HTTP/1.1
Host: kinesis.<region>.<domain>
Content-Length: <PayloadSizeBytes>
User-Agent: <UserAgentString>
Content-Type: application/x-amz-json-1.1
Authorization: <AuthParams>
Connection: Keep-Alive
X-Amz-Date: <Date>
X-Amz-Target: Kinesis_20131202.PutRecord
{
"StreamName": "exampleStreamName",
"Data": "XzxkYXRhPl8x",
"PartitionKey": "partitionKey"
}
Sample Response
HTTP/1.1 200 OK
x-amzn-RequestId: <RequestId>
Content-Type: application/x-amz-json-1.1
Content-Length: <PayloadSizeBytes>
Date: <Date>
{
"SequenceNumber": "21269319989653637946712965403778482177",
"ShardId": "shardId-000000000001"
}Conclusion
In this article, you have learned about AWS Kinesis PutRecord Command. This article also provided information on AWS Kinesis, its components and streaming data.
Hevo Data, a No-code Data Pipeline provides you with a consistent and reliable solution to manage data transfer between a variety of sources and a wide variety of Desired Destinations with a few clicks.
Hevo Data with its strong integration with 150+ Data Sources (including 60+ Free Sources) allows you to not only export data from your desired data sources & load it to the destination of your choice but also transform & enrich your data to make it analysis-ready. Hevo also allows integrating data from non-native sources using Hevo’s in-built REST API & Webhooks Connector. You can then focus on your key business needs and perform insightful analysis using BI tools. Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
FAQs
1. Is data encryption supported in PutRecord?
Yes, AWS Kinesis supports server-side encryption, which means that the data gets sent across the stream both securely and privately.
2. How do you retry a failed PutRecord request?
AWS SDKs automatically retry failed requests, but you can easily implement your own retry logic based on your needs.
3. Can PutRecord handle large data sizes?
The PutRecord command accepts data records of size up to 1 MB, but bigger records may need partitioning or batching.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





