
 Upcoming webinar on
“Snowflake Summit 2026: Everything You Need to Know About CoCo and Beyond”
|
Jul 23, 2026
|
Register Here
Upcoming webinar on
“Snowflake Summit 2026: Everything You Need to Know About CoCo and Beyond”
|
Jul 23, 2026
|
Register Here
Upcoming webinar on
“Snowflake Summit 2026: Everything You Need to Know About CoCo and Beyond”
|
Jul 23, 2026
|
Register Here
Upcoming webinar on
“Snowflake Summit 2026: Everything You Need to Know About CoCo and Beyond”
|
Jul 23, 2026
|
Register Here
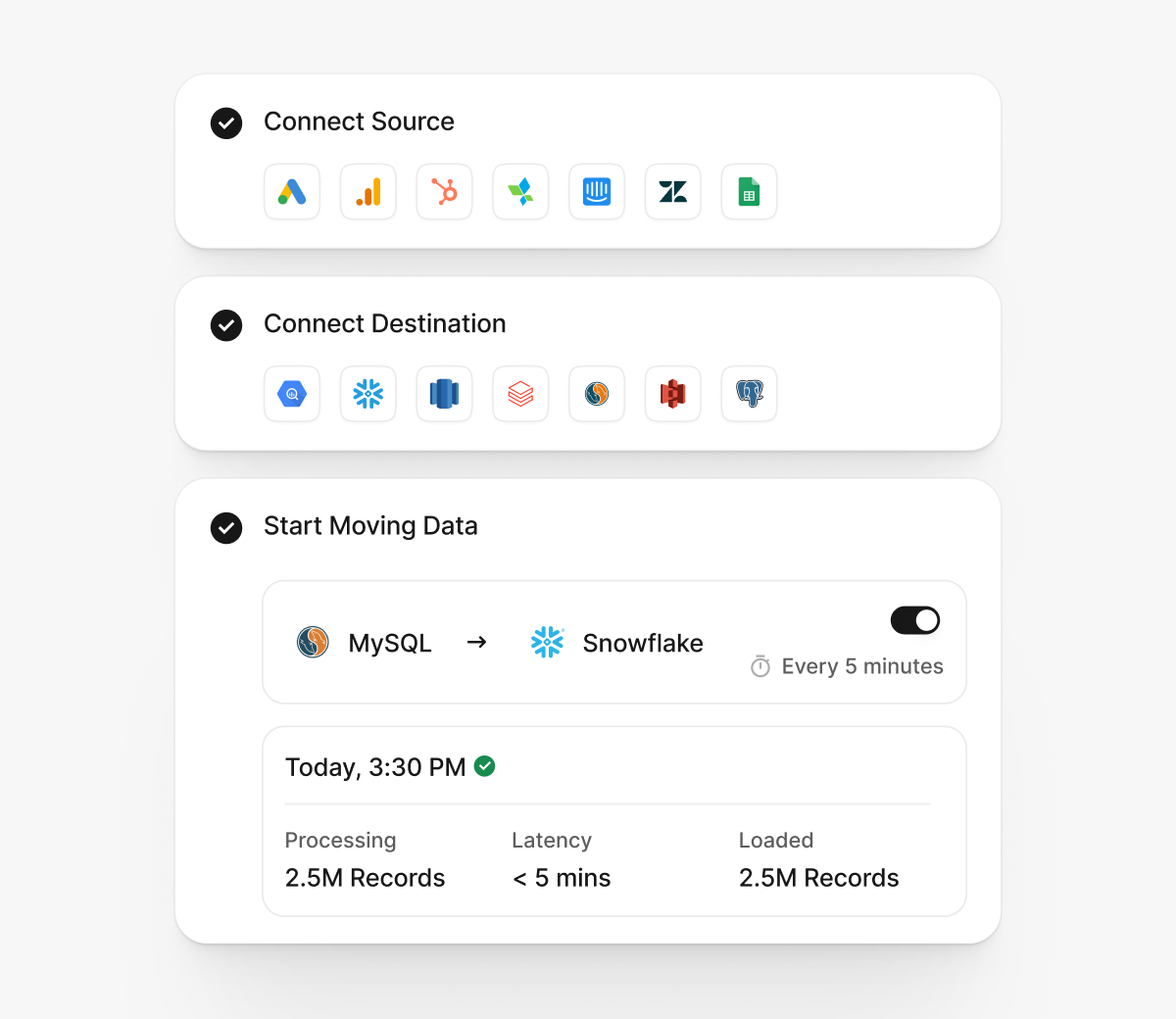
Simple to start, reliable to scale, and transparent to trust - built for effortless, predictable data movement.

Configure pipelines effortlessly with a clean interface that keeps your data flowing smoothly and reliably.
Isolated pipelines with auto-retries and fail-safes prevent cascading failures.
Scale with usage-based pricing. No hidden fees or surprise bills.
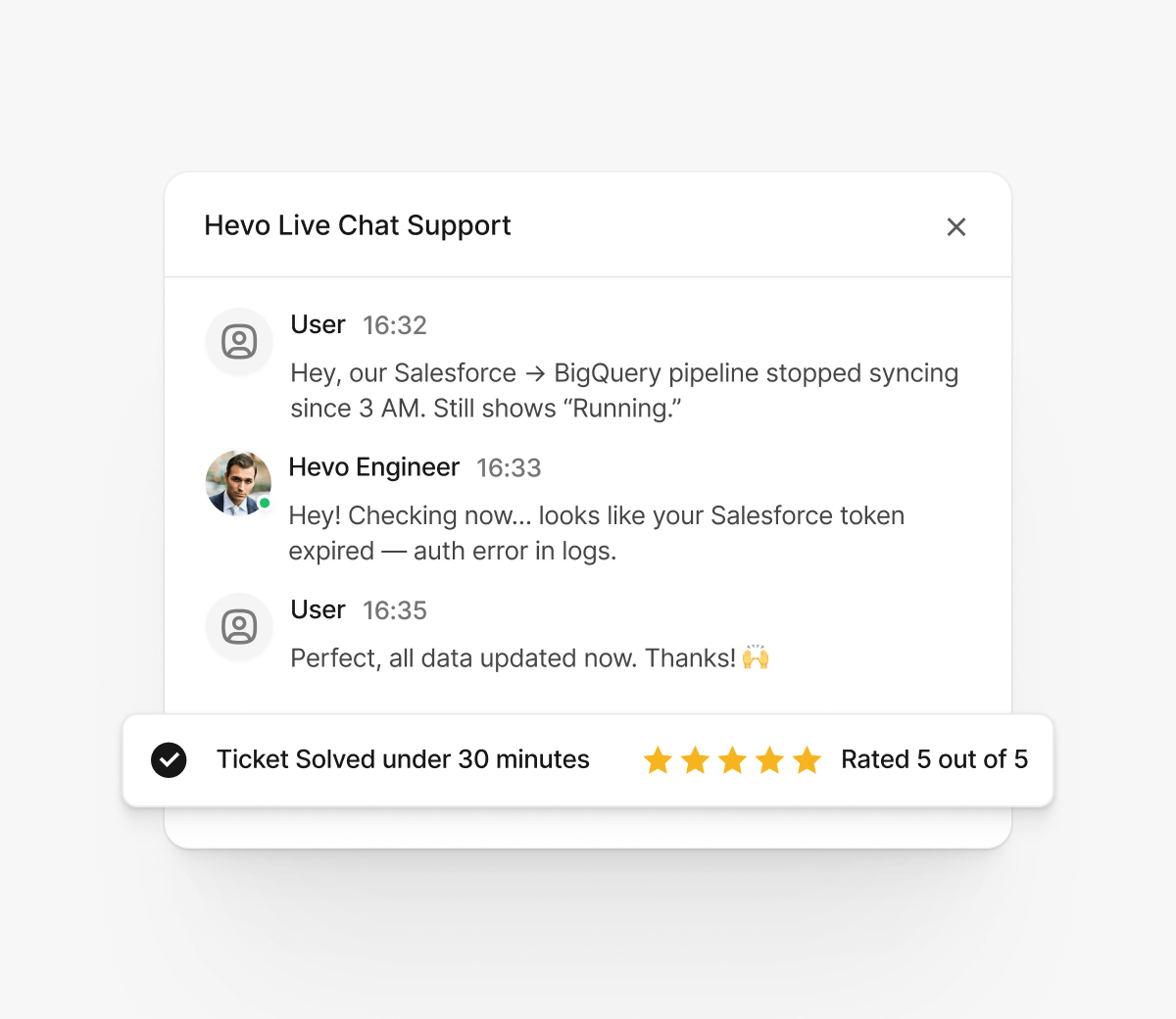
Get dedicated support from real engineers who understand your data infrastructure challenges.
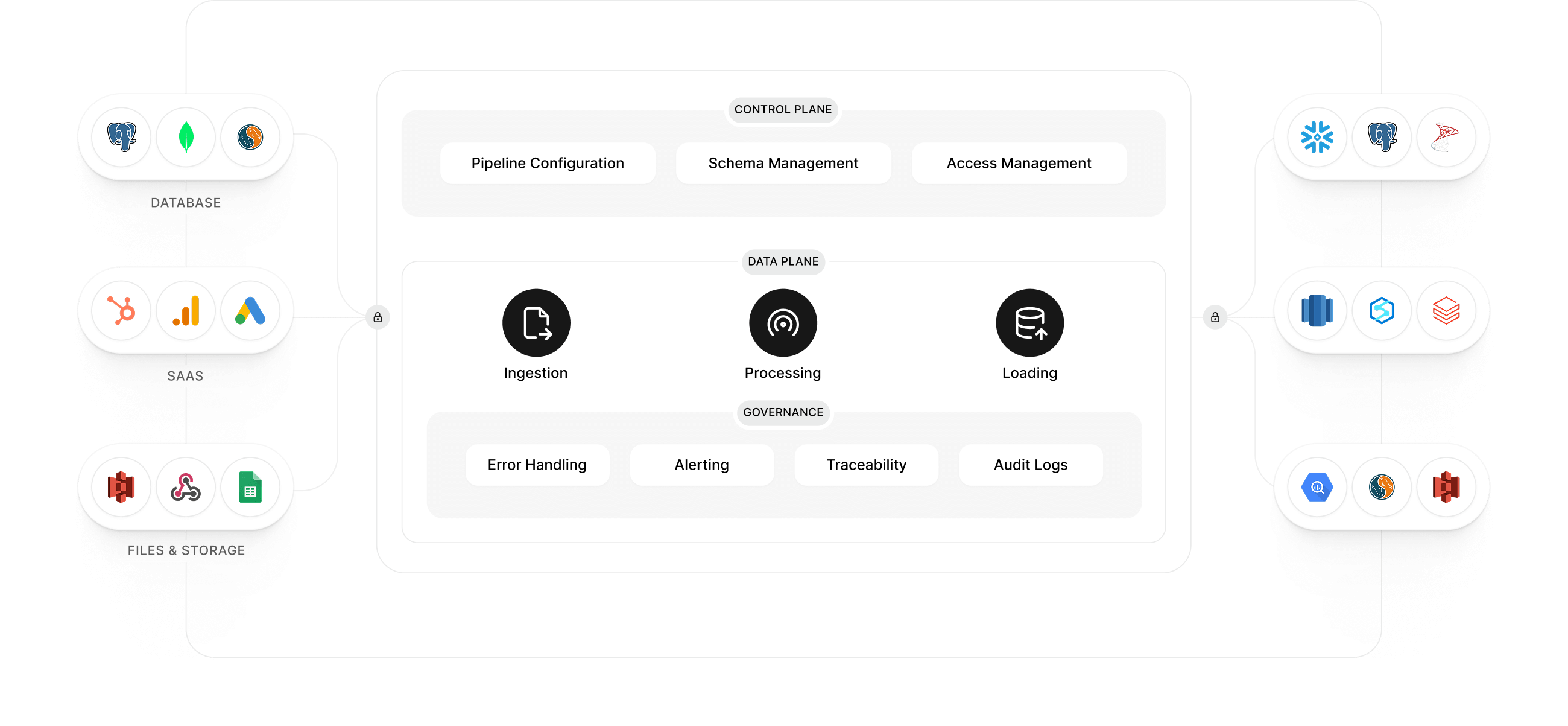
Scale effortlessly with low-latency pipelines that keep your data fresh and consistent.
Log-based CDC ensures accurate, near real-time replication with zero data loss.
Ingest from databases, SaaS tools, files, or REST APIs with 150+ ready connectors.
Built for high availability, which prevents downtime through resilient design.
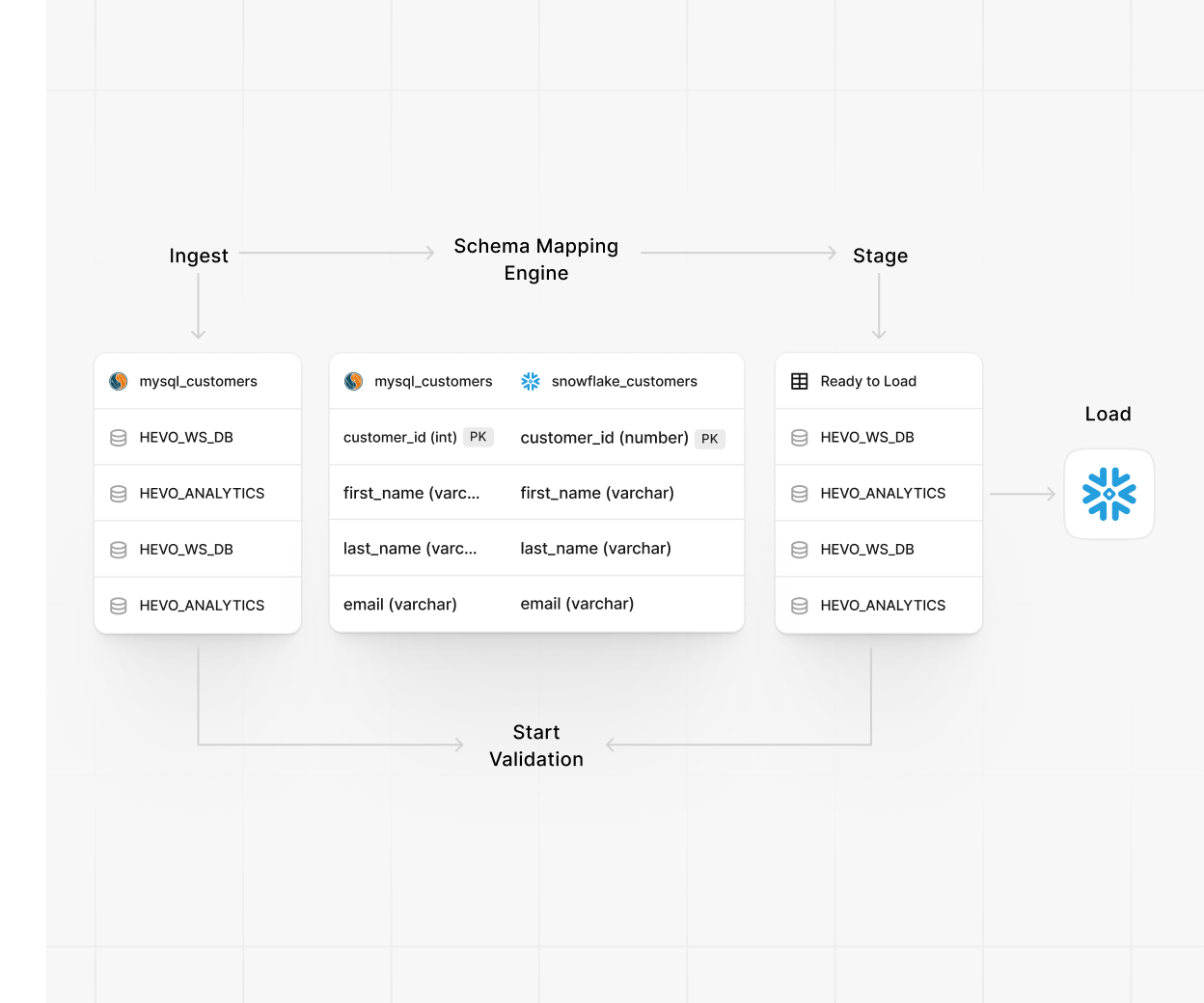
Automatically detects schema drift and updates mappings without downtime.
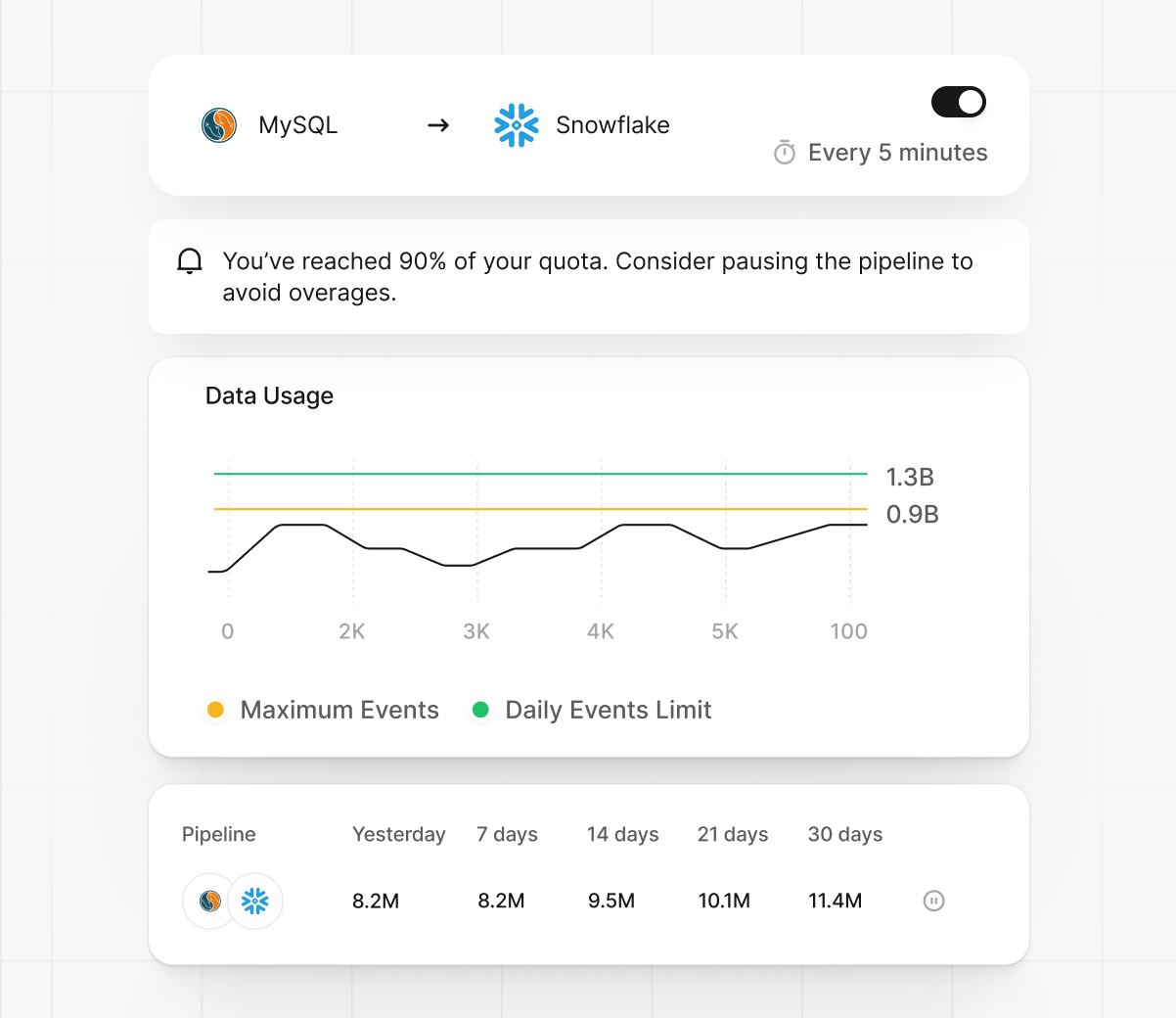
Monitor latency, throughput, and activity logs in real time with unified, live operational dashboards.
Connect to 150+ sources like SaaS tools, databases, or APIs - Hevo handles setup, auth, and schema automatically.
ExploreLoad clean, ready-to-query data into any major warehouse or lake.
ExploreChoose dbt, SQL models or Hevo transformers - all managed within Hevo’s fault-tolerant pipelines.
Dedicated VPCs, regional residency, and complete audit trails for enterprise-grade governance.
Learn MoreSSH, SSL, RBAC - secure from ingestion to delivery.











