

Unlock the full potential of your AWS RDS MSSQL data by integrating it seamlessly with Redshift. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
The need to handle data and generate insights has become one of the primary considerations for companies.
- Corporations typically store their on-premise data in a database designed for day-to-day transactional operations. Consequently, integrating data from a database into a data warehouse is a crucial step for any organization.
- Amazon RDS is a database management web service that helps organizations manage data efficiently.
- If businesses integrate this data with a data warehouse like Amazon Redshift, they can generate critical insights. This article will explore various methods to integrate AWS RDS MSSQL to Redshift.
Table of Contents
Why Integrate AWS RDS MSSQL to Redshift?
- AWS RDS MSSQL and Amazon Redshift enable data storage in a cloud environment. So why should you consider moving data from AWS RDS MSSQL to Redshift?
- The key advantage of integrating these two platforms is that Amazon Redshift provides features to handle big data and perform quick analytics.
- Although both platforms enable you to scale your data quickly, Redshift can process petabyte-scale databases.
- This feature allows corporations to benefit from the Redshift environment by performing complex queries over their data.
An Overview of Amazon RDS for SQL Server
- Amazon Relational Database Service for SQL Server is a renowned database management web service.
- It enables you to create, manage, and scale an SQL Server relational database on the AWS ecosystem.
- It is a cost-effective solution for managing your database administration tasks in the cloud.
- Amazon RDS for SQL Server provides multiple features, including high availability, scalability, easy data migration, and more.
- It can help you store your data and retrieve insights in a secure environment.
Methods to Connect AWS RDS MSSQL to Redshift
Method 1: Using Hevo Data to Transfer AWS RDS MSSQL Data to Redshift
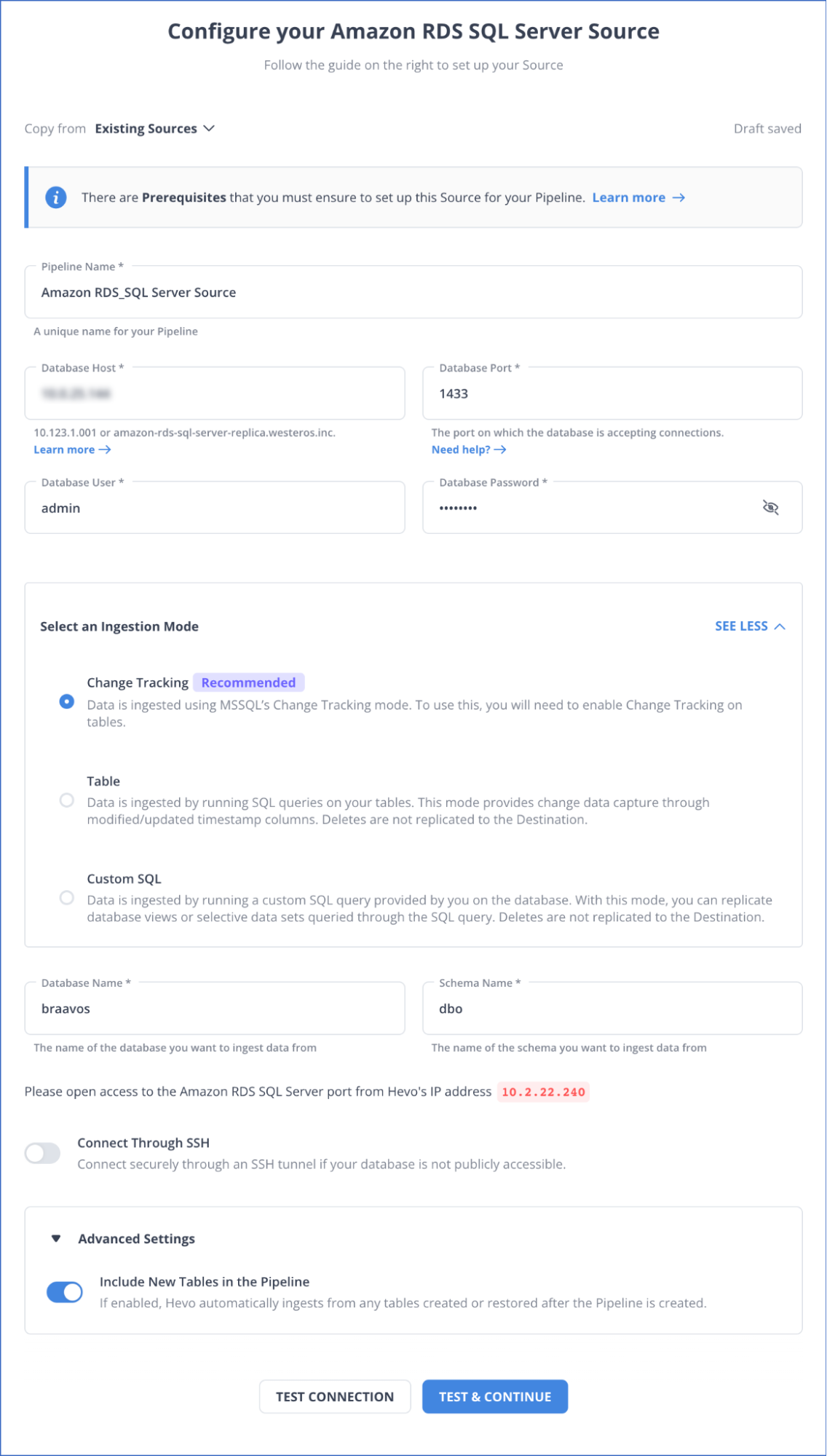
1. Configuring AWS RDS SQL Server as a Source
- Step 1 – Select PIPELINES from the Navigation Bar, and click on + CREATE in the Pipelines List View.
- Step 2 – Select Amazon RDS SQL Server on the Select Source Type page.
- Step 3 – Mention the necessary fields on the Configure your Amazon RDS SQL Server Source page.
Before getting into the steps, you must ensure that the prerequisite conditions are satisfied:
Prerequisites
- The MS SQL Server version that you use must be 2008 or higher.
- If the Pipeline mode is Table or Change Tracking, and the Query mode is Change Tracking:
- Enable Change Tracking and grant CHANGE TRACKING and ALTER DATABASE permissions to the database user.
- Whitelist Hevo’s IP Addresses and grant SELECT and VIEW CHANGING TRACKING privileges to the database user.
- To create a pipeline, you must be a Team Administrator, Pipeline Administrator, or Team Collaborator in Hevo.
- Finally, click on TEST CONNECTION and select TEST & CONTINUE.
- Configure the Object and Query Mode Settings depending on your ingestion mode.
2.Configuring Amazon Redshift as a Destination
- Step 1 -In the Navigation Bar, select DESTINATIONS.
- Step 2 -Click on + CREATE from the Destinations List View.
- Step 3 – Select Amazon Redshift on the Add Destination page.
- Step 4 – Specify the mandatory fields on the Configure your Amazon Redshift Destination page.
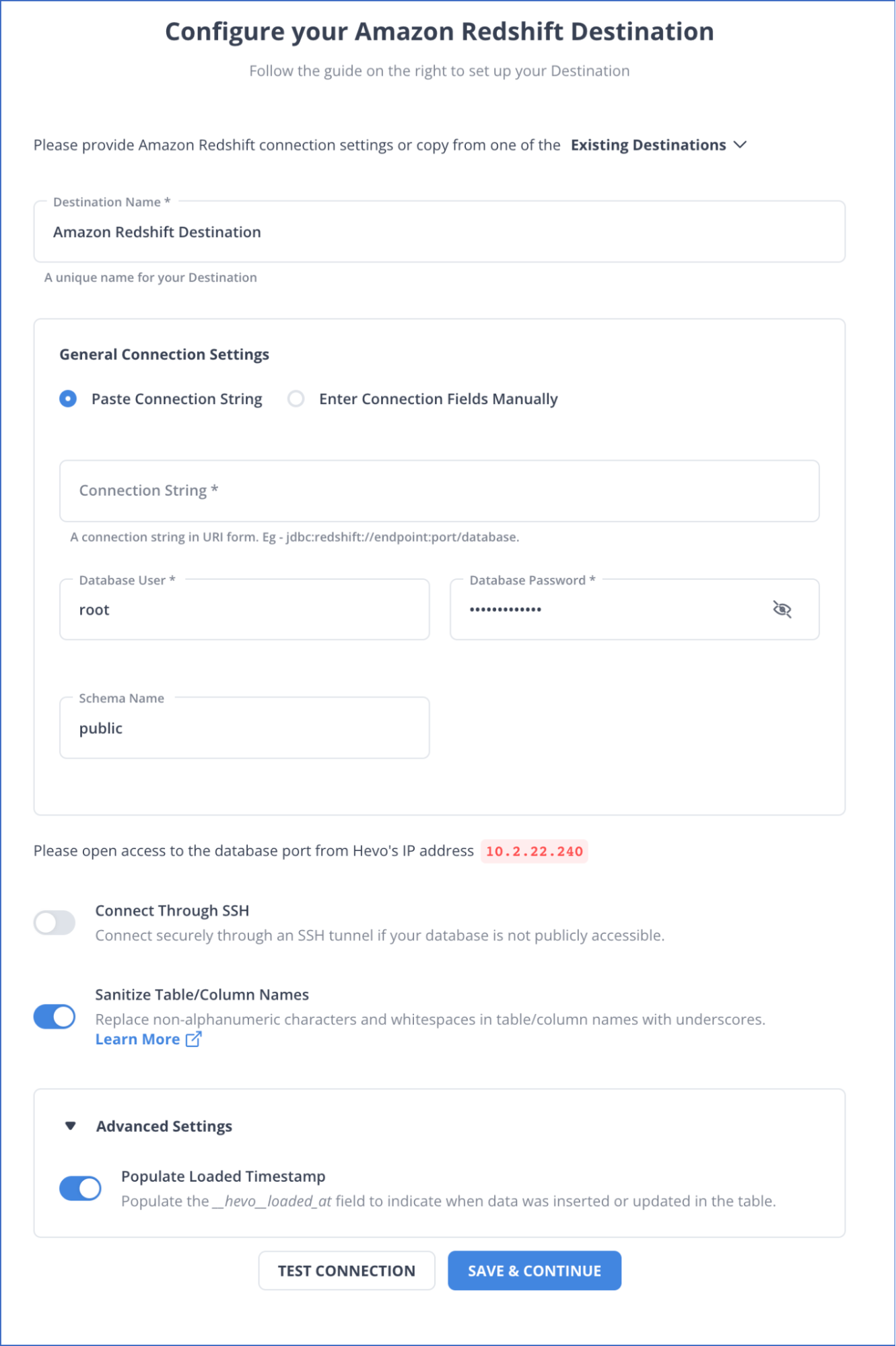
- Click on TEST CONNECTION, and select SAVE & CONTINUE.
SIGN UP HERE FOR A 14-DAY FREE TRIAL
Method 2: Moving the Data from AWS RDS MSSQL to Redshift Using Amazon Migration Service
Moving Data from AWS RDS SQL Server to Amazon S3
Prerequisites
- You must choose Policies from the navigation bar on the IAM Management Console.
- You must create a new policy and use the Visual editor tab to follow the steps given below.
- For Service, enter S3 and select S3 service.
- For Actions, choose the following: ListAllMyBuckets, ListBucket, GetBucketACL, GetBucketLocation, GetObject, PutObject, ListMultipartUploadParts, AbortMultipartUpload.
- The available Resources option will depend on the Actions you select. For the bucket, add the Amazon Resource Name (ARN) of the desired bucket. For object, you can:
- To grant access to all the files in the bucket, choose “Any.”
- You can also specify ARNs to access specific files or folders.
- Follow the instructions in the console to complete the procedure.
After creating the IAM policy, you must create an IAM role that uses this policy. You can follow the steps given below to do so:
- Choose Roles from the navigation pane on the IAM Management Console.
- Select the following on the console after creating a new IAM role:
- AWS service
- RDS
- RDS: Add Role to Database
Select Next: Permissions at the bottom.
- For Attach permission policies, enter the name of the IAM policy and choose the policy from the list.
- Finally, you can follow the instructions given on the console to complete this process.
After satisfying all the prerequisites, follow the steps below to move data from AWS RDS MSSQL to Amazon S3.
- Open the Amazon RDS console by signing in to the AWS Management Console.
- Select the RDS for the SQL Server DB instance.
- Under the Manage IAM roles section on the Connectivity & security tab, select the IAM role to add for Add IAM roles to this instance.
- Select S3_INTEGRATION for Features.
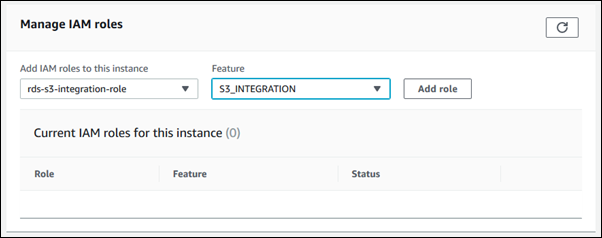
- Select Add role.
Following these steps, you can quickly move your AWS RDS SQL Server instance data to Amazon S3. Read AWS RDS SQL Server to Amazon S3 Official Documentation to learn more.
Loading Data from Amazon S3 to Redshift
Prerequisites
- You must have an AWS account to run an Amazon Redshift cluster and to create a bucket in Amazon S3.
- You must have the required AWS credentials (IAM role) to load data from Amazon S3.
- You must have an SQL client such as Amazon Redshift console query editor.
After satisfying the requirements, you can follow the steps below to load data from Amazon S3 to Redshift.
- You must create a cluster if you do not have one and create tables.
- After creating the tables, you need to run the COPY commands.
- Finally, you must vacuum and analyze the database and clean up your resources.
Following these steps, you can move your data from Amazon S3 to Redshift. To learn more about the steps involved, read Loading data from Amazon S3. You can also refer to Hevo Data Amazon S3 to Redshift to complete this process using Hevo.
Use Cases of Connecting AWS RDS MSSQL to Redshift
- Moving your data from AWS RDS MSSQL to Redshift enables SSL security measures for transit data. Additionally, it allows hardware-accelerated AES-256 encryption for data at rest with minimum parameter adjustments.
- You can leverage the powers of Redshift ML to create, train, predict, and deploy models using SQL.
- Moving data from AWS RDS MSSQL to Redshift can be beneficial since Redshift stores the data in a columnar format, which is better for data analysis.
Conclusion
- In this article, you reviewed two of the most widely used methods showcasing the best practices for migrating AWS RDS MSSQL data to Redshift.
- Although both methods efficiently transfer data from AWS RDS MSSQL to Redshift, the second data migration method has limitations.
Interested in integrating data from some other database to Amazon Redshift? Here are a few of the top picks:
Frequently Asked Questions (FAQs)
Q. Is Redshift capable of working as a traditional Relational Database Management System (RDBMS)?
Yes, Redshift builds upon PostgreSQL, but it optimizes for Online Analytical Processing (OLAP) tasks. Therefore, it can serve as a traditional Relational Database Management System (RDBMS) and a robust data warehouse solution.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





