

AWS Data Pipeline is a web service that lets you process and moves data at regular intervals between AWS computing and storage services, as well as on-premises data sources. It enables you to develop fault-tolerant, repeatable, and highly available complex data processing workloads.
This article will give you a comprehensive guide to and you will get to know about the architecture and key features of the AWS Data Pipeline.
You will also explore the features, pricing, advantages, limitations, and many more in further sections. Let’s get started.
Table of Contents
What Is AWS Data Pipeline?

AWS Data Pipeline is a web service provided by Amazon Web Services (AWS) that helps you reliably process and move data between different AWS compute and storage services and on-premises data sources at specified intervals. It provides various advantages, such as complex data workflows that can be scheduled and executed in a fully managed environment.
Key Features of AWS Data Pipeline
- Data Movement and Transformation: This service automates the movement and transformation of data across different AWS services, such as Amazon S3, Amazon RDS, Amazon DynamoDB, and more.
- Scheduling: Allows you to define when your data pipeline tasks should run and the execution order, ensuring that data is processed and moved in a timely manner.
- Fault Tolerance: It automatically retries failed tasks and sends notifications when they fail, providing reliability in data processing workflows.
Benefits of AWS Data Pipeline
- Automated Data Workflows: Streamline and automate data pipeline movement and processing between AWS services and on-premises sources, reducing manual intervention.
- Scalability: It efficiently handles large-scale data processing tasks, scaling up as needed to meet the demands of your data workflows.
- Reliability: It provides built-in fault tolerance and automatic retries, ensuring that data tasks are completed successfully even in case of failures.
- Cost-Effective: You only pay for the resources used, making it a cost-effective solution for managing and processing data across different environments.
What Hevo Offers: Hevo simplifies and accelerates your data integration process with its intuitive, no-code platform, ensuring real-time data transfer and seamless connectivity.
Key Benefits:
- Real-Time Data Integration: Instantly move data across platforms with minimal latency.
- No-Code Platform: Set up and manage your data pipelines without any coding required.
- Comprehensive Data Quality: Ensure accurate, consistent data with built-in quality checks and transformations.
Explore why Postman chose Hevo over other data pipelines for easy data ingestion pipeline creation and robust Role-Based Access Control (RBAC).
Get Started with Hevo for FreeWhat Are the Core Concepts and Architectures of AWS Data Pipeline?
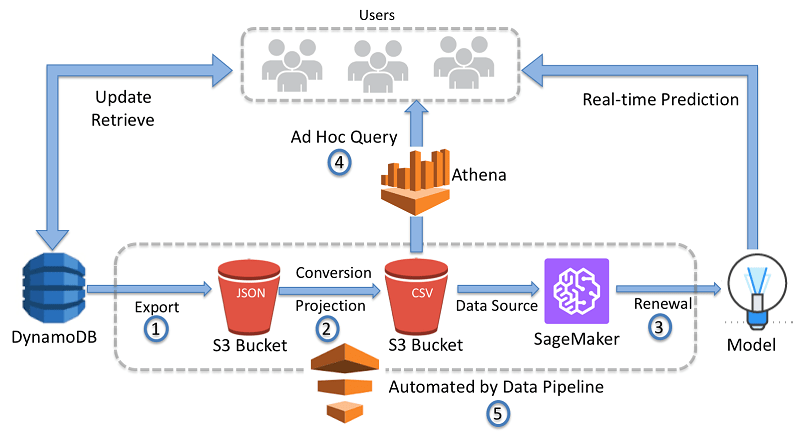
Conceptually, the AWS pipeline is organized into a pipeline definition that consists of the following components.
- Task runners: Task runners are installed in the computing machines that will process the extraction, transformation, and load activities. Task runners are responsible for executing these processes as per the schedule defined in the pipeline definition. You can also learn about different types of data pipelines here.
- Data nodes: Data nodes represent the type of data and the location from which it can be accessed by the pipelines. This includes both input and output data elements.
- Activities: Activities represent the actual work that is being performed on the data. The data pipeline supports multiple activities that can be chosen according to the workloads. Typical activities are listed below.
- CopyActivitiy: Used when data needs to be copied from one data node to another.
- EmrActivity: Activity for starting and running an EMR cluster.
- HiveActivity: Runs a hive query.
- HiveCopyActivity: Runs a pig script in the AWS EMR cluster.
- RedshiftCopyActivity: Runs a copy operation to the Redshift table.
- ShellCommandActivity: For executing a Linux shell command or a script.
- SQLActivity: Runs an SQL command on supported databases. The data pipeline supports JDBC databases, AWS RDS databases, and Redshift.
- Preconditions: These are pipeline components with conditional statements which must be true for the next pipeline activity to start. These are used for chaining pipeline activities based on custom logic.
- Resources: Resources for an AWS Data pipeline are usually an EMR or an EC2 instance.
- Actions: Data pipelines can be configured to execute certain actions when specific conditions meet or certain events occur. These are typically notifications or termination requests.
What Are the Pros and Cons of AWS Data Pipeline?
AWS Data pipeline unleashes the full power of an ETL platform in the form of a web service with a very comprehensive control panel. That said, it is not without its cons. The below section details the pros and cons of the service from an ETL developer’s point of view.
Pros
- Simple to use control panel with predefined templates for most AWS databases.
- Ability to spawn clusters and resources only when needed.
- Ability to schedule jobs only on specific time periods.
- Full security suite protecting data while in motion and rest. AWS’s access control mechanism allows fine-grained control over who can use what.
- Fault-tolerant data architecture – Relieves users of all the activities related to system stability and recovery
Cons
- The data pipeline is designed for AWS services or, in other words, AWS world and hence integrates well with all the AWS components. AWS is not the right option if you need to bring data from different third-party services.
- Working with data pipelines and on-premise resources can be overwhelming, with multiple installations and configurations to be managed on the compute resources.
- The data pipeline’s way of representing preconditions and branching logic can seem complex to a beginner, and to be honest, there are other tools out there that help to accomplish complex chains more easily. An example is a framework like Airflow.
What are the Top Alternatives to AWS Data Pipeline?
1) Hevo

As mentioned above, the AWS pipeline is not without its cons and can make easier jobs seem complex if there are components outside the AWS universe. In such cases, your needs may be better served by a fully managed data integration platform like Hevo.
2) AWS Glue
AWS Glue is a fully-managed Extract, Transform, and Load (ETL) service that makes it easy and cost-effective to categorize your data, clean, enrich, and move it between reliably disparate data stores and data streams. AWS Glue is a tool in the big data tools category of a technology stack.
3)Apache Airflow

Apache Airflow is a workflow engine that makes it easy to plan and run complex data pipelines. This ensures that each job in the data pipeline runs in the correct order and each job gets the resources it needs. It provides an amazing user interface to monitor and troubleshoot problems.
4) Apache NiFi
Apache NiFi is open-source software for automating and managing the flow of data between source and destination. A robust and reliable system for data processing and distribution. Provides a web user interface for creating, monitoring, and managing data flows. You have a dataflow process that you can easily customize and modify to change data at runtime.
What Is the Pricing of AWS Data Pipeline?
The data pipeline is priced in terms of activities and preconditions that are configured in the console and their frequency of executions. AWS classifies the frequency of executions as low in the case of activities that are executed up to once per day.
All activities that are executed more than once per day are high-frequency activities. The low-frequency one on AWS is charged at $.6 per month and the one on on-premise systems is charged at $1.5 per month. High-frequency activities start at $1 per month and go up to $2.5 per month for on-premise systems.
All the resources used in the pipeline activity like EC2 instances, EMR clusters, Redshift databases, etc are charged at the normal rates and come above the pipeline pricing. Above mentioned charges are only for the pipeline features.
How to Work With AWS Data Pipelines?
Working with the AWS pipeline is all about pipeline definitions. Let us look into setting up a simple AWS pipeline for copying data from RDS to Redshift.
You need to have an AWS account before you can proceed with working the AWS pipeline. This can be done based on predefined templates from AWS, saving us quite a lot of configuration effort.
- From the AWS console, go to the data pipeline and select ‘Create new pipeline’. This will take you to the pipeline configuration screen.
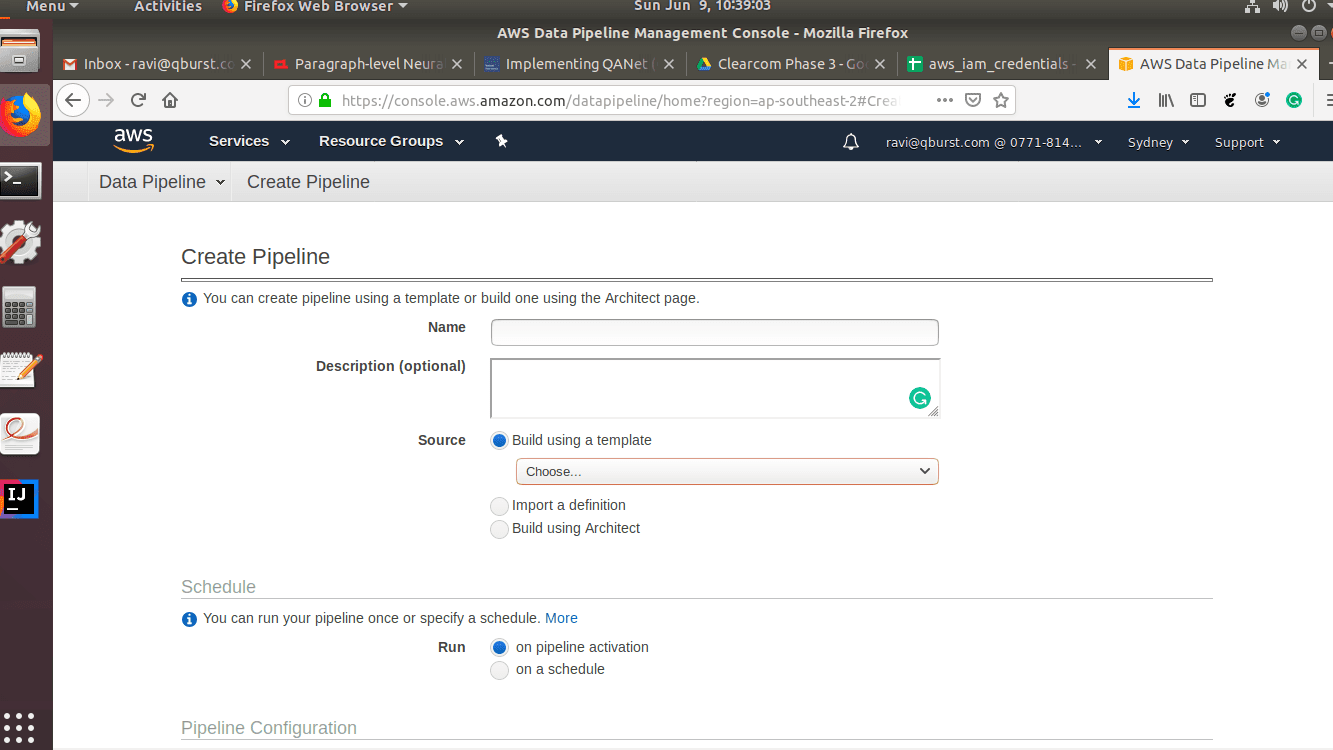
- Enter the name and description of the pipeline and choose a template. Here we choose ‘incremental copy of MySQL RDS to Redshift’. There is also another option to configure the pipeline using the Architect application for more advanced use cases.
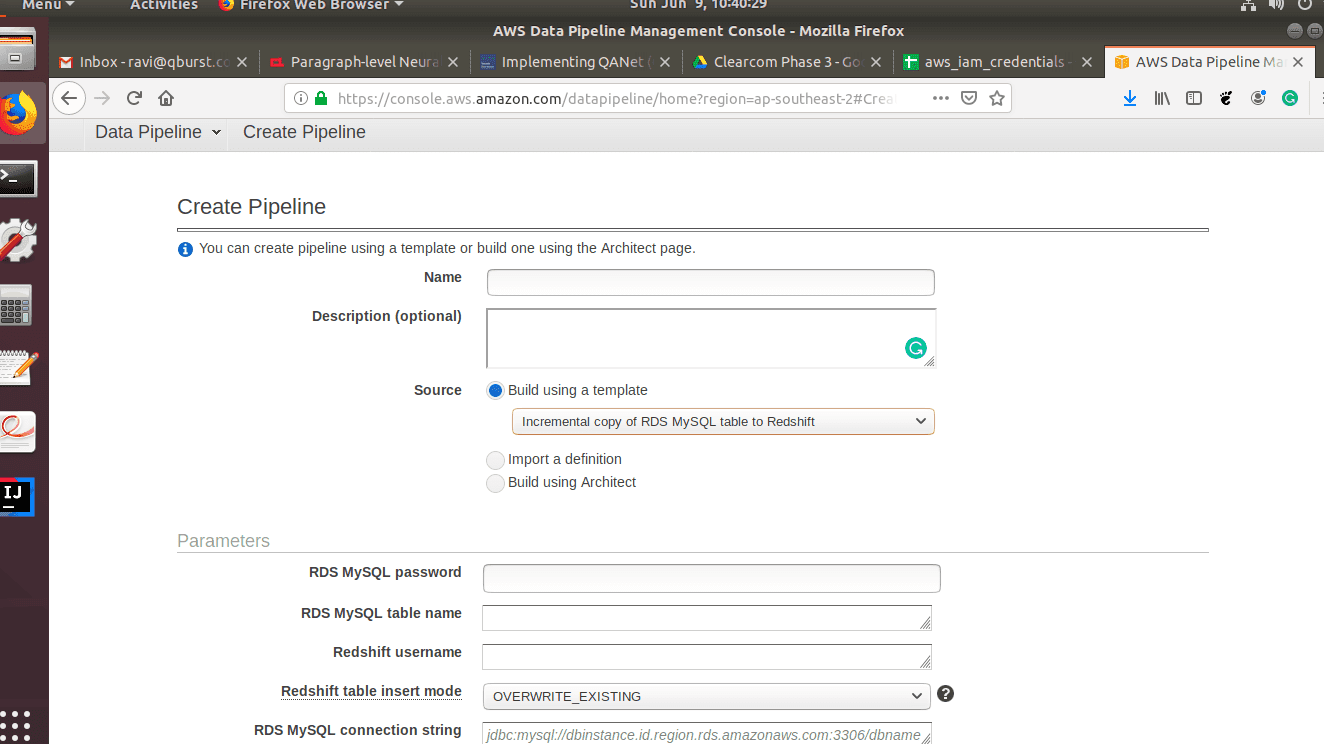
- After selecting the template, it is time to fill in the parameters for the data nodes we are using in this case. Fill up the parameters for the RDS MYSQL instance.
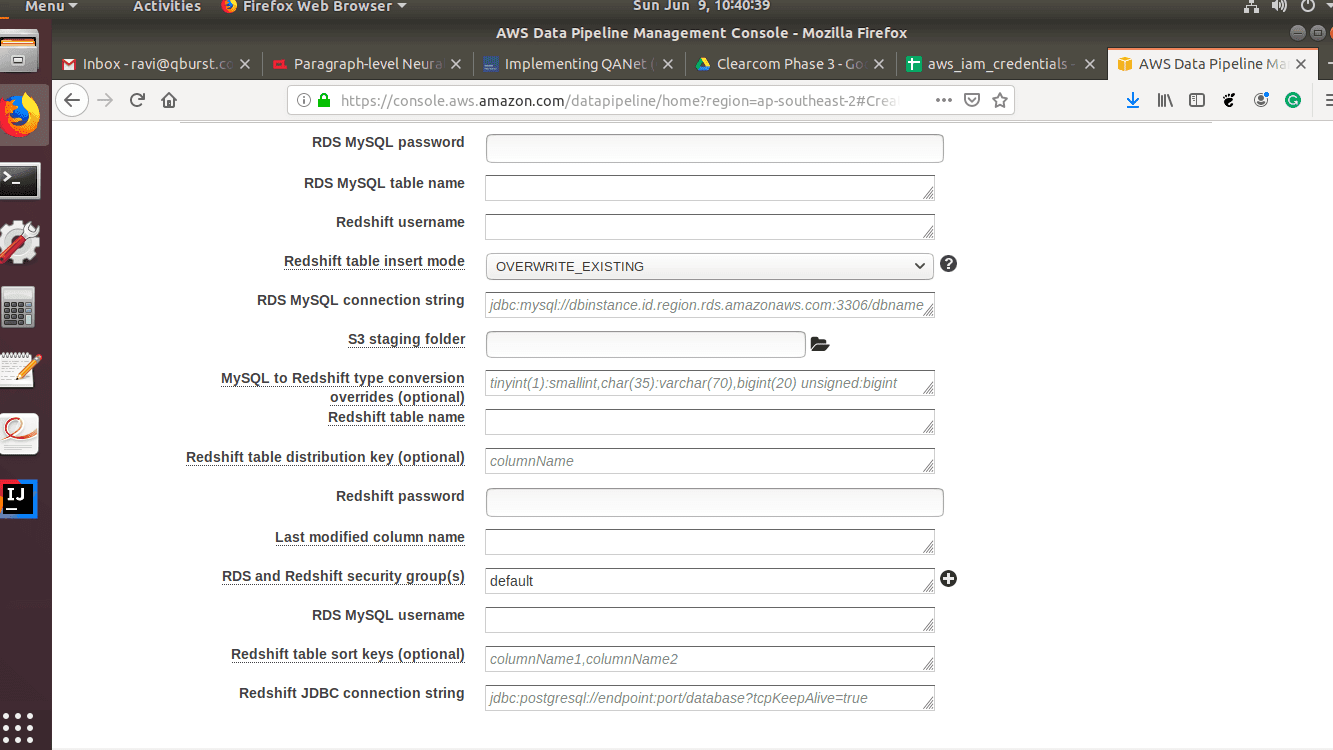
- Configure the Redshift connection parameters.
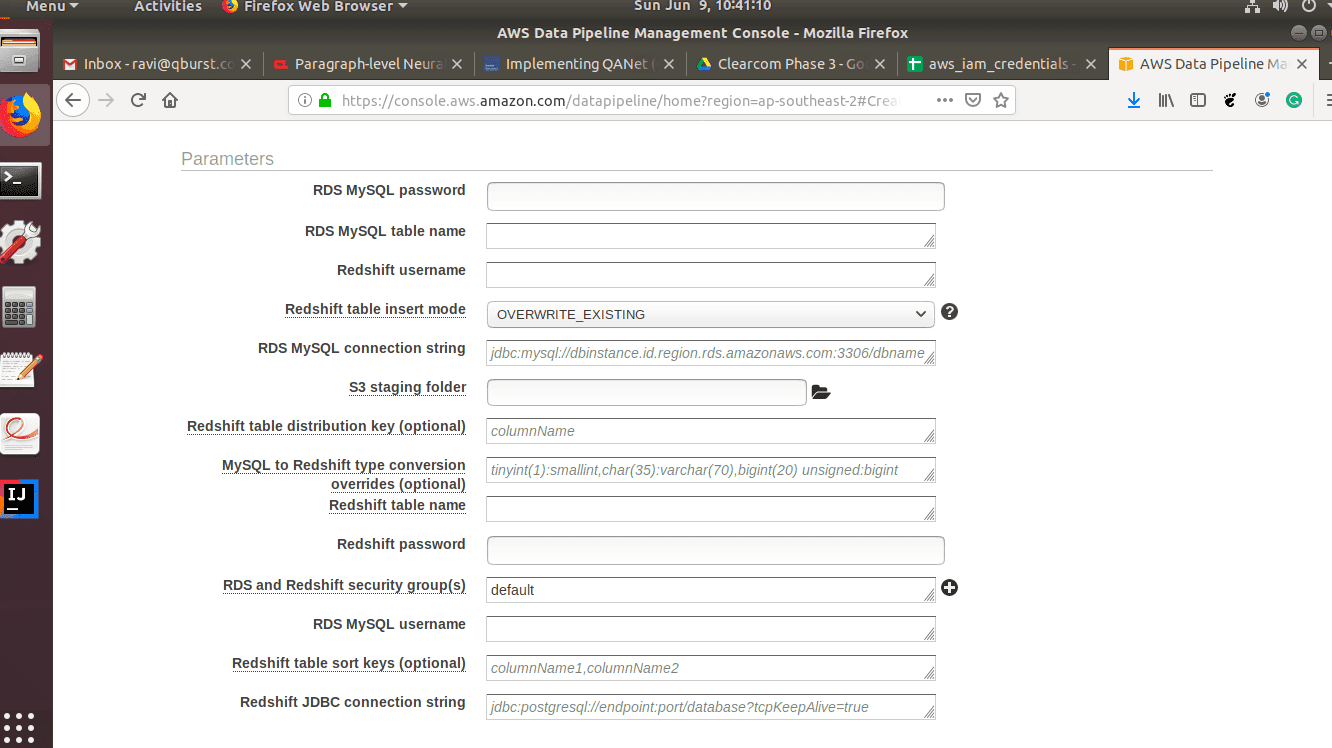
- Select the schedule for the activity to run. You can either select a schedule or enable a one-time run on activation.
- The next step is to enable the logging configuration. We suggest you enable this for any kind of pipeline activity and point the login directory to an S3 location. This can be very useful for troubleshooting activities later. Click ‘Activate’ and you are good to go.
How to Delete AWS Data Pipeline?
Deleting your pipeline will delete your pipeline definition and its associated objects. Let’s look at the steps to delete your AWS data pipeline:
- Click on the List Pipelines and then select the pipeline which you want to delete.
- Click Actions and select Delete.
- Confirm your delete operation by clicking on Delete again.

Conclusion
If your ETL tool involves AWS ecosystem components only, then the AWS Data pipeline is an excellent choice for implementing ETL workflows without having to maintain an ETL infrastructure on your own.
That said, it is not without its quirks, and we have attempted to explain the less elegant bits in the above sections.
If your use spans beyond AWS components or if you are looking to implement a fuss-free ETL, it may be better to use robust data pipeline platforms such as Hevo Data that provide much more flexibility along with an enterprise-grade data migration experience.
Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
FAQs
1. What is AWS data pipeline vs AWS Glue?
AWS Data Pipeline automates data workflows, including moving and transforming data between different AWS services and on-premises systems. It’s more flexible in terms of supporting a variety of data processing tasks.
AWS Glue is a fully managed ETL service that simplifies data preparation by automatically discovering, cataloging, and transforming data. It’s designed specifically for ETL tasks and has built-in support for data cleaning, transformation, and integration with data lakes and warehouses.
2. What is an ETL pipeline in AWS?
An ETL pipeline in AWS extracts data from various sources transforms it into a suitable format, and then loads it into a target data store, such as Amazon Redshift or S3. AWS provides several tools for building ETL pipelines, including AWS Glue, Amazon EMR, and Amazon Data Pipeline.
What is the Amazon data pipeline?
Amazon Data Pipeline is a web service that automates the movement and transformation of data across various AWS services and on-premises data sources. It enables you to create, schedule, and manage data-driven workflows, ensuring that your data is processed and available when needed.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





