Product
EXPLORE THE PLATFORM
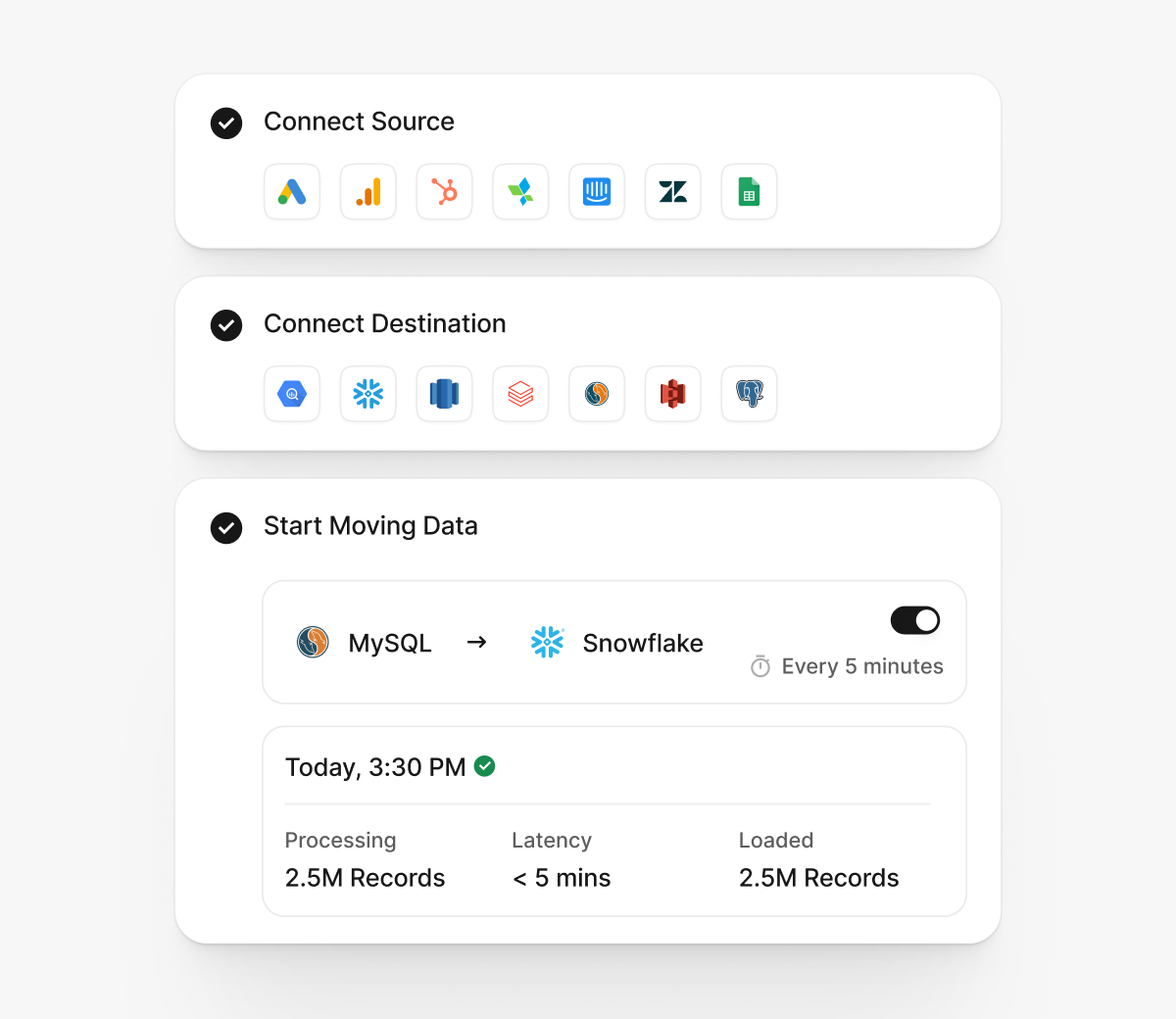
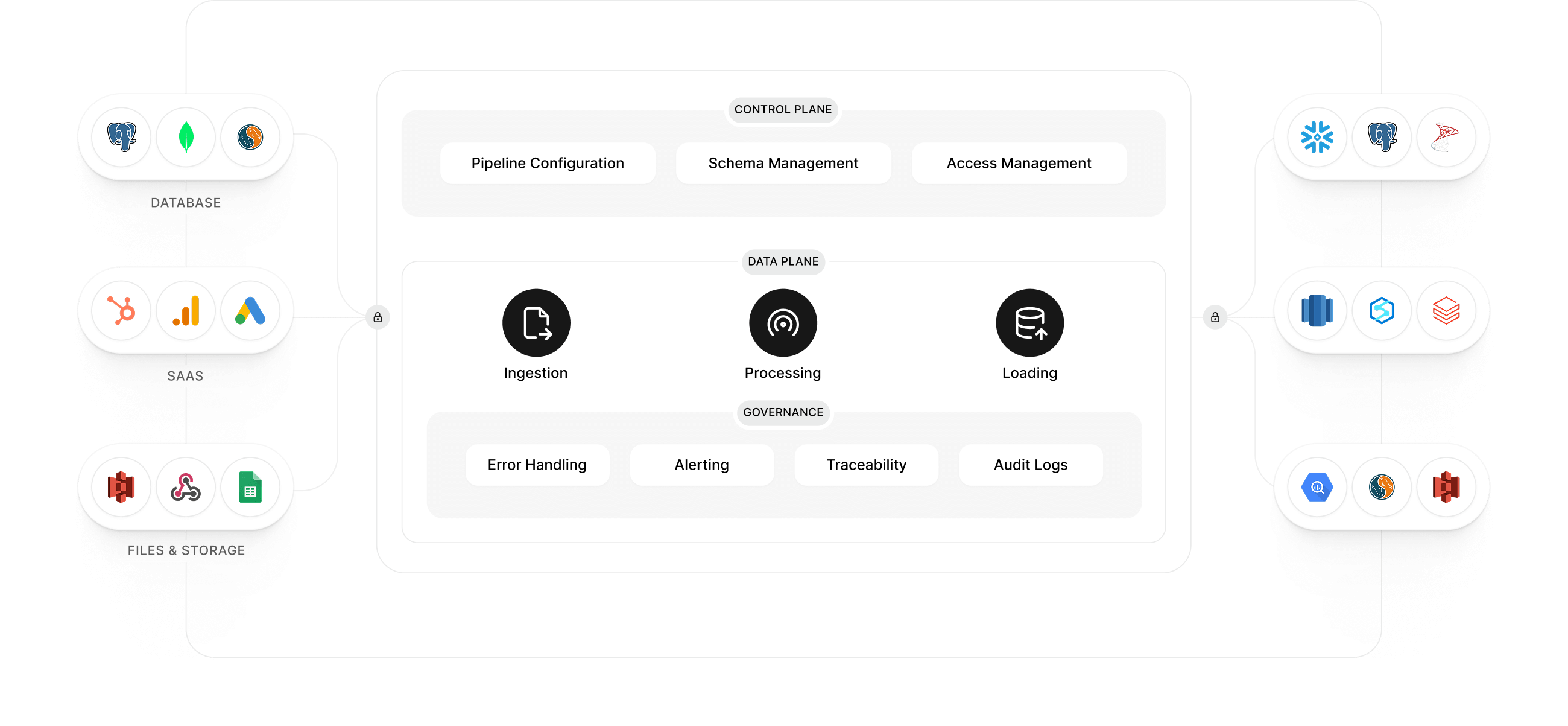
Ingestion
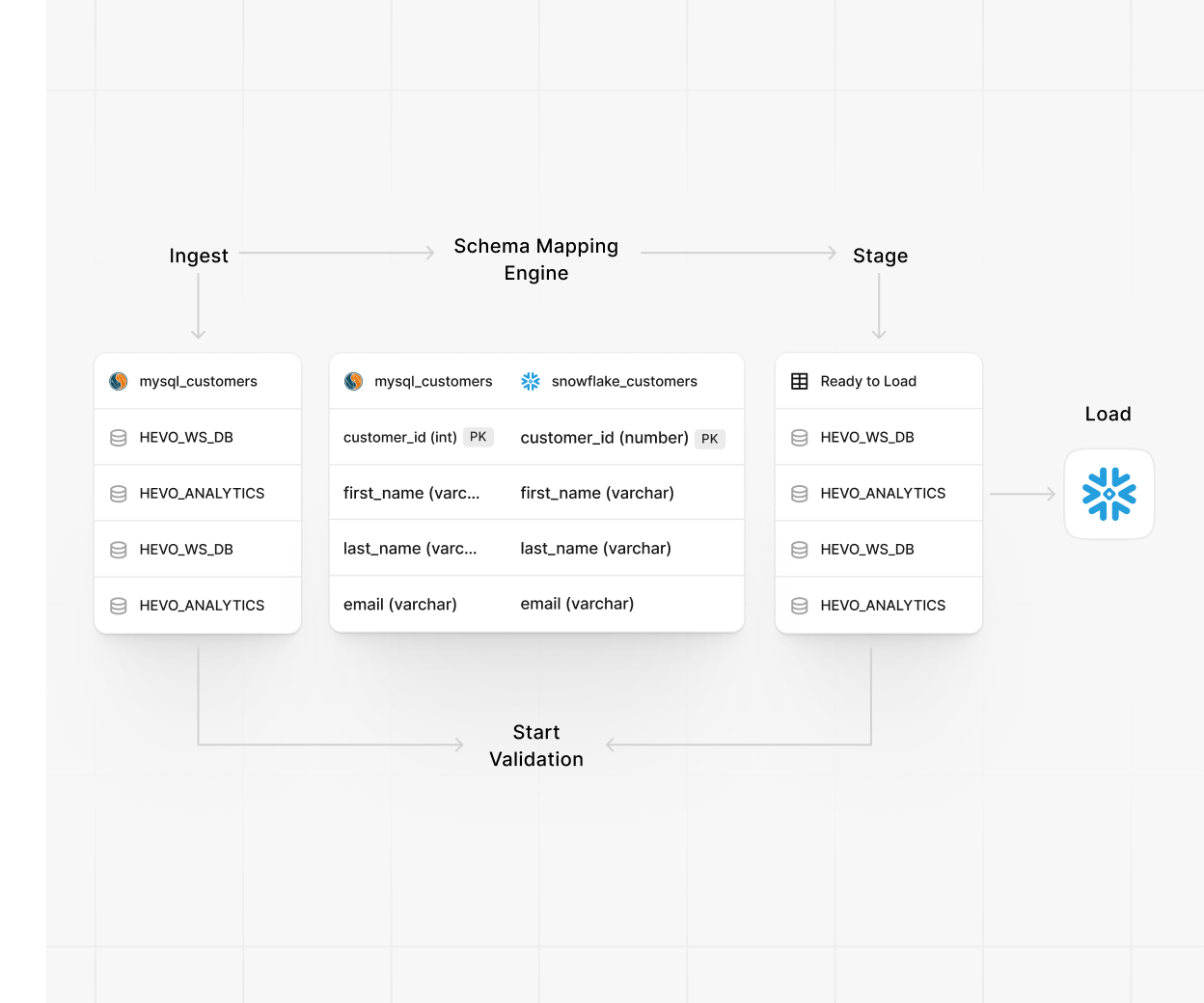
Transformation
Destination
PLATFORM FEATURES
Reliability Engine
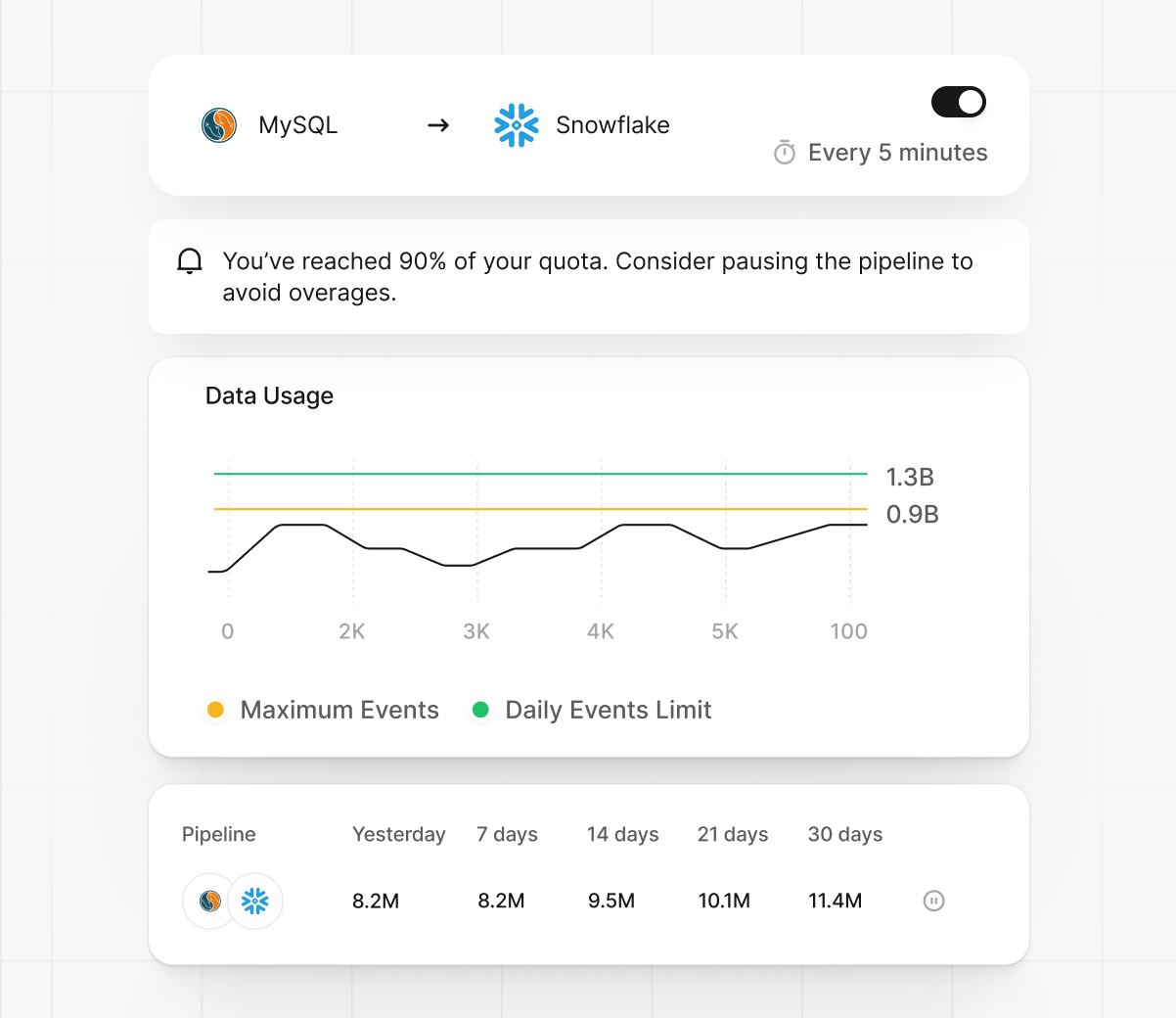
Observability & Alerts
Security
Governance
Ease of Use
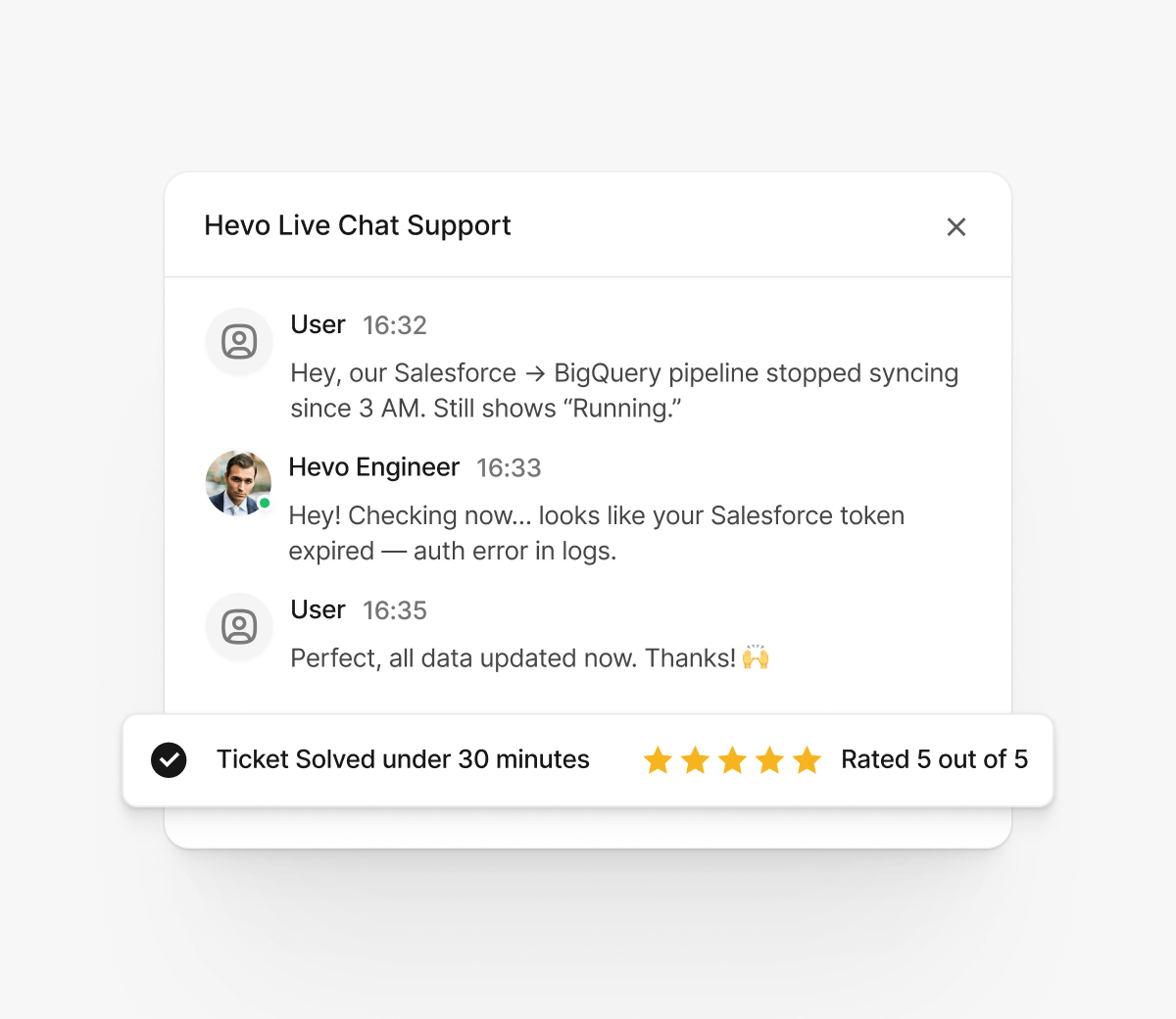
Enterprise Support
Transparent Pricing
Solutions
BY TECHNICAL USE CASE
Data Democratisation
Analytics
AI-Ready Data
Cost Optimization
BY BUSINESS USE CASE
Database Replication
SaaS Replication
File Replication
BY INDUSTRY USE CASE
Software & Technology
Retail & E-Commerce
HealthTech
FinTech