

About Pelago
Pelago is a travel experiences platform created by Singapore Airlines Group. They are like a travel magazine that customers can book - highly curated, visually inspiring, with the trust and quality of Singapore Airlines. They connect customers with global, local cultures and ideas so they can expand their lives.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
Pelago is a B2C travel experiences platform by Singapore Airlines, present in 80+ countries worldwide. They help travelers discover and book all sorts of experiences within cities, ranging from guided tours, transportation, and events, to tickets to tourist attractions. Merchants list their various offerings on the platform, and consumers from around the world discover and book those offerings.
Pawan is the CTO at Pelago and has seen the evolution of their data stack from the beginning. Data has been crucial to Pelago from Day 0, specifically for making efficient decisions and building a platform that offers a very high level of user personalization.
He shares how they effortlessly moved all their data to the warehouse using Hevo, enabling them to manage data volumes for remarkable business growth without spending weeks building and managing pipelines.

With business growth, the need to move data grew too
When they started, Pelago built custom data pipelines using Glue for AWS to collect first-party event streaming data from their platform. This data was loaded to their data warehouse Redshift for analytics and a real-time database for personalization at scale.
The business exploded, and they witnessed over 50x growth in a year, which rapidly increased the data volume and added new SaaS applications. The data team started receiving requests from different teams to extract data from various SaaS applications for analytics. It was a small but highly skilled team of 3 that was already managing the platform data for over 1M users monthly.
On one side, the marketing team wanted to pull data from various sources to accurately calculate the CAC (customer acquisition cost). They have hundreds of campaigns, as they run campaigns on every single potential pair of origin and destination countries. On the other hand, the fraud team wished to monitor the chargeback and dispute cases daily. To achieve all this, data from various sources, like GA, FB Ads, Stripe, Zendesk, etc., needed to be moved quickly to their warehouse for analysis. There were many more use cases as well, and the data team was overwhelmed by the number of requests coming in from other teams.
Given the small team size, it was not efficient for them to manually write code to create and manage pipelines, particularly for available fully-managed connectors in the market. It would take away the time the team could be building advanced data models, enhancing analytics, etc.
So, Pawan started looking for an automated data pipeline that scales seamlessly and requires minimal coding and maintenance.
Leveraged Hevo to effortlessly set up Data Pipelines for various sources
Pawan and his team came across Hevo Data. The vast range of available connectors and the auto schema mapping functionality, which greatly eliminated the frustrating set-up and maintenance of pipelines, were some reasons he felt that Hevo was the best pick.

Hevo Data gives a rock-solid foundation for any organization to be truly data-driven, and not just as a hype word, in each and every business function; from product to operations to marketing. It enables the proliferation of data in a very scalable and lean manner.
Pawan and his team leveraged the hassle-free data pipeline capabilities of Hevo to seamlessly move data from SaaS applications to their warehouse, unlocking multiple analytical applications.
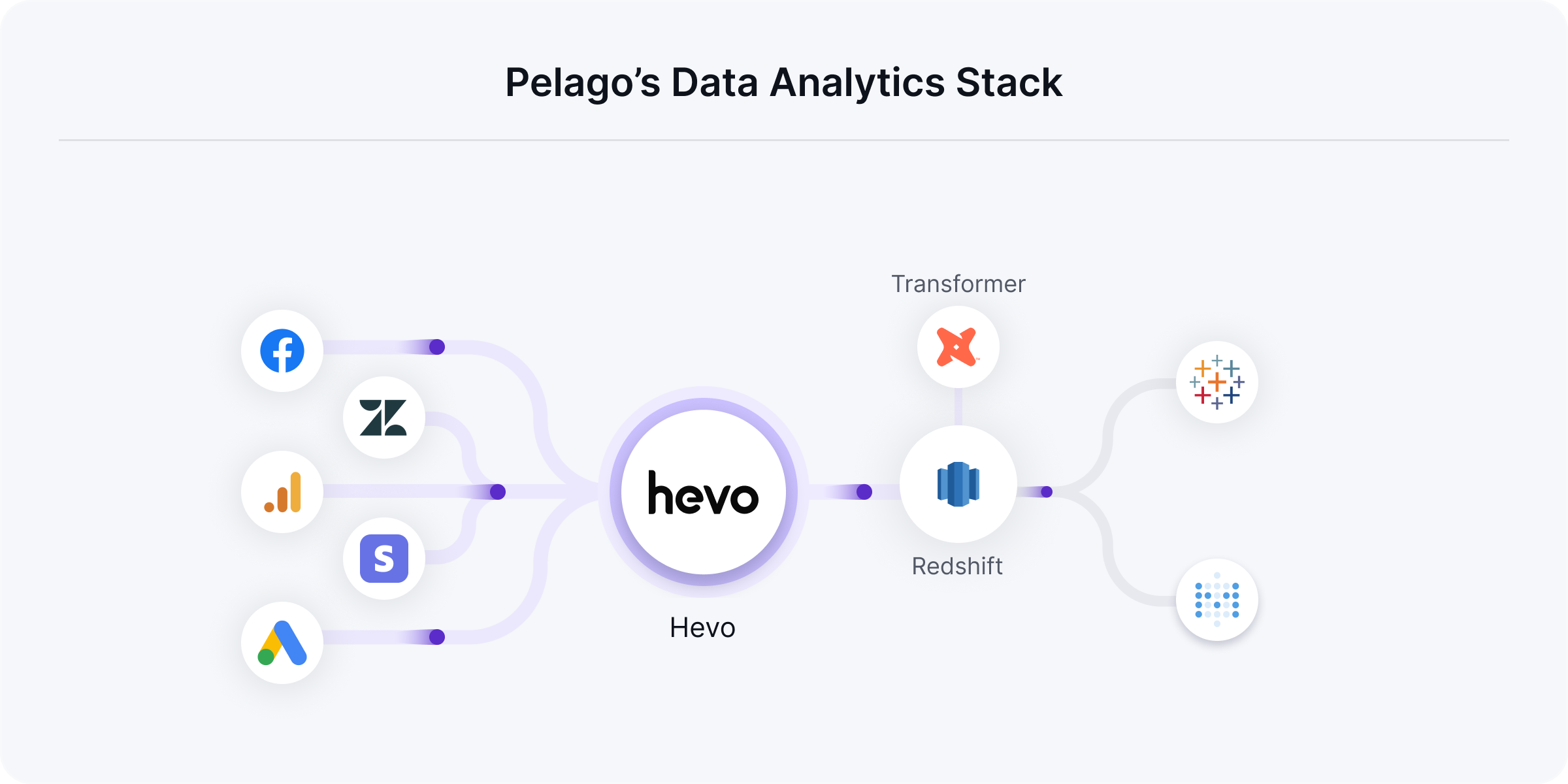
The marketing team: The team quickly set up pipelines from sources like Google Ads, Facebook Ads, and Google Analytics in a few clicks. Now, the marketing team can get an accurate value in Redshift of the CAC for each and every marketing campaign they run. This gives them very granular insights on region, campaign, and Origin-Destination pair level, which allows them to quickly and effectively monitor their campaigns and optimize them.
The finance team: Due to the industry they are in, Pelago faces a lot of potential frauds that they need to keep on top of. For example, users might purchase tickets using stolen credit cards- this is easy because tickets don't have a name or any other user identification on them. Hence, various teams need to monitor fraud transactions and disputes daily. Through the integration from Stripe, they can get the chargeback and dispute information within the warehouse to create a dashboard. They have a notification engine running inside this data, and various teams use other workflows from Redshift to monitor and act upon them.
The customer success team: Through data integrated from Zendesk, the customer success team can easily access ticket data in one place to do their own analysis on them. They are able to understand common customer issues, do sentiment analysis on reviews, etc.
After successfully moving all the data into Redshift, Pelago employs dbt to transform and normalize the data, ensuring its readiness for analysis. By connecting Redshift to QuickSight and Metabase, Pelago provides visualizations and dashboards to various teams.
Automated ELT Workflow with Hevo and set up self-serve analytics
By setting up pipelines with Hevo, Pawan and his team were able to cut down the time on setting up data pipelines from a minimum of two weeks to just a few clicks.
Hevo seamlessly managed the entire ELT workflow and automatically scaled as the business grew, all without requiring any maintenance from the data team, thus saving the data team valuable hours of maintaining pipelines. Low SLAs mean that data is always available as soon as it is required.
With the click of a button and simple massaging of data on Hevo Data, you can get all your data into your data lake pretty easily. Otherwise, understanding and creating data schemas, creating pipelines, doing transformations…this would be a very laborious process.
They particularly enjoy the flexibility of managing schedules using the workflows provided by Hevo, as well as the collaborative and customer-centric approach of the Hevo team to add any requested features quickly.
By harnessing the normalized data stored in the warehouse, the data team empowered business teams with self-serve analysis capabilities. This enabled business users and analysts to independently connect to Metabase, write their queries, gain instant insights, and build their own self-serve dashboards without relying on the data team. This self-serve approach not only accelerated the decision-making process but also reduced the workload on the data team.
All teams can now access the required data quickly, accurately, and with minimal effort from the data team. This has created a truly accessible and democratized system of data within Pelago.
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.