

About Playtomic
Playtomic is the biggest network of sports reservations in Europe. Using their platform, players can find and book sport locations, primarily tennis & padel courts. Founded in Spain, Playtomic has now expanded to over 30 countries. Playtomic aims to revolutionize how sports events are organized by leveraging technology & data.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
Playtomic makes it easy for players to book a sports venue online, either through their website or mobile application. Therefore, making the entire booking process more convenient. Additionally, users can join matches created by other users that are searching for new players or created by the system itself leveraging an algorithm that suggests the best candidates to fill the open spots. Lastly, partner sports clubs use this platform to manage bookings online, maximize their club occupancy and reach new players.
The different stakeholders of Playtomic including top-management & middle-management have a heavy reliance on data for monitoring, assessing, and anticipating day-to-day business decisions. Additionally, partner sports clubs consume data via Playtomic’s Sports Management Software to power payments, booking schedules, and eCommerce. This puts data at the heart of a lot of core business processes. Thus, ensuring the timely availability of accurate & unified data is a top priority.
Playtomic is a young company and has a very flexible team. Their development team works on several microservices divided into macro-areas, every area has its own team of developers and in every team, there's an ‘expert’ responsible for its data. Meet Marco Rossi, the Head of Business Intelligence at Playtomic, the person in charge of the company’s BI and assisted by the CTO and those experts. Marco is responsible for integrating data from all business applications and presenting it in an easily accessible and convenient form to all the stakeholders.

Data Challenges
In the early days of Playtomic, being a start-up, there was no need for a dedicated pipeline solution due to the usage of limited data sources and low data volumes. They were just using Tableau as their reporting tool to create monthly reports and it used to pull data directly from the servers where their databases were storing the org-wide data. But, as their business grew, both in terms of employees and operations, data needs also grew exponentially.
Access to org-wide data was limited to high-level executives, thereby, limiting the usage of data by different team members for faster decision-making. After Marco joined Playtomic, his mission was to inculcate data literacy throughout the company to extend the influence of data across various business functions.

I wanted to democratize data, make it available to everyone within the organization, but our current setup wasn’t allowing that. Keeping an eye on the future, I needed a scalable solution that was easy to set up at the beginning and cope up with our growing needs. Before trying Hevo, I had reviewed a few of the data pipeline tools and also tried a few all-in-one solutions like Sisense, Holistics, and GoodData because we wanted to centralize everything yet avoiding allocating too many resources.
The Solution
Since its inception, the data team at Playtomic used to directly aggregate data from three different databases to their BI tool every day, and they were aggregating data from other sources using CSV import on the monthly basis. Before Marco joined Playtomic, they had no data stack in place. Marco started scaling their Business Intelligence vertical, switched to Metabase from Tableau, and started searching for a data pipeline solution to put their entire data stack in place.
My expectations from a data pipeline tool, and what I am really happy to have found in Hevo, is the plug-n-play approach that allows us to connect to a source without significant time investment and start ingesting data within a few minutes. Ease of use is essential because it allows non-developers to accomplish tasks that normally would require some very skilled developers. Also, it’s an all-in-one platform that caters to all of our ETL/ELT needs.
Currently, Marco is using Hevo to connect all their essential data sources but they plan to integrate all the major & minor data sources as well to gain deeper insights. In addition to standard transformations, they’re leveraging these features to further automate and streamline Data Pipelining:
Data Models on BigQuery on a recurring basis to create complex data models and overcome restrictions on materialized views on BigQuery
Workflows to define dependencies between different models and automate execution in a specific order to eliminate errors when dealing with intricate Data Models
Visual Transformation Builder allows non-developers to create data pipelines without writing code in an intuitive GUI
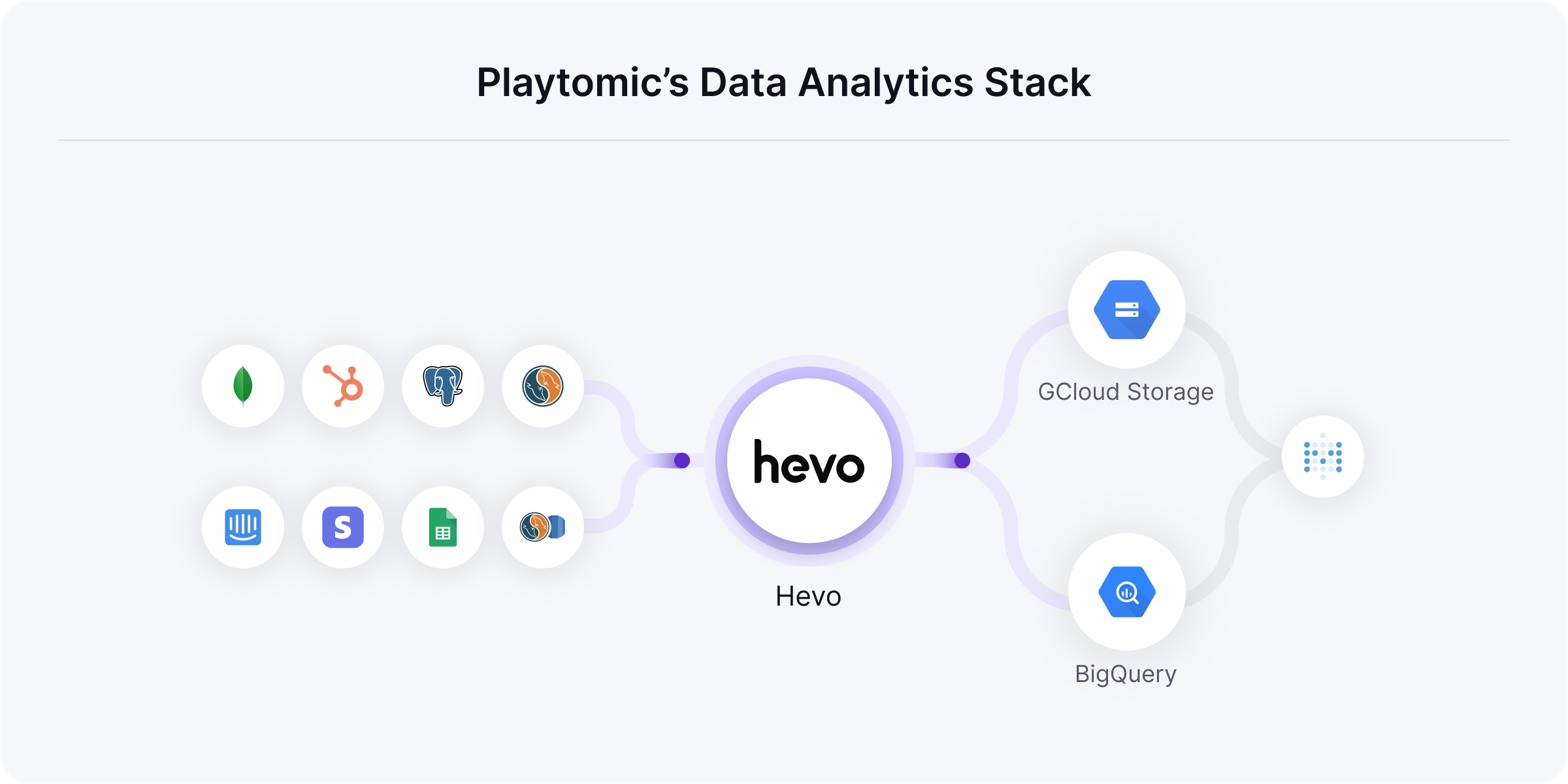
Playtomic is using Hevo to pipeline data from multiple data sources including Amazon Aurora MySQL, MySQL, PostgreSQL, MongoDB, Stripe, HubSpot, Intercom, and Google Sheets to their Google Cloud Storage Data lake and BigQuery Data Warehouse. They finally load this data to Metabase to make dashboards, run queries, and report.
Key Results
Thanks to Hevo we have successfully managed to set up a cutting-edge pipelining system saving 6 months of development time. Maintenance has a marginal impact and it requires an average of 10h/month, allowing us to avoid allocating full-time resources to this task and refocusing them on where we need the most. Overall, on a yearly basis, we estimate that our savings are close to €120K.
Marco and his team have 20 active pipelines on 7 different sources processing over 50M events per month with zero data loss. Every time they’ve raised an issue, it gets promptly resolved by Hevo’s customer support team ensuring a smooth experience and minimum downtime.
Before Hevo there was no BI at Playtomic, everything was on request and data was difficult to obtain. Hevo has helped us inculcate data literacy at Playtomic by aggregating our data and making it quickly available to those who need it. The single biggest reason I would recommend Hevo is that everyone can use it without prior coding knowledge.
Playtomic’s platform is expanding its business in multiple countries across Europe and the USA and rolling out a premium subscription plan for partner sports clubs. They’re aiming to further improve data literacy by introducing more data-driven processes and AI to increase efficiency. Hevo is amazed to see the strides they’ve made in the sports technology space and is proud to act as a backbone for all their data needs and decision-making.
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.