

 Quick Takeaways
Quick Takeaways- Data replication is essential for businesses facing issues with data downtime, inconsistency, or slow performance. It ensures your data is synchronized and accessible across multiple systems, improving efficiency and minimizing errors.
- Choosing the right tool depends on your business needs, including scalability, security, and integration. Open-source tools offer cost-effective and customizable solutions, while closed-source tools provide robust features and support for more complex requirements.
Data replication is one of those behind-the-scenes tasks that businesses often overlook until it starts causing problems.
You know the drill: data that should be synced across systems gets out of date, reports become unreliable, and your team is left scrambling to fix things. For many companies, this isn’t just an occasional issue; it’s a recurring challenge.
The real problem with data replication isn’t just about moving data from one place to another. It’s about ensuring that data remains consistent, up-to-date, and accessible across systems, without compromising on performance. Many businesses struggle with schema drift, high costs of tools, and keeping everything synchronized in real-time.
That’s why we’ve put together a list of the best data replication tools on the market, from open-source solutions that are flexible and affordable to closed-source tools that offer robust features and reliable support.
Here are our top picks:
- 1
 No-code cloud ETL for effortless, maintenance-free pipeline creation.Try Hevo for Free
No-code cloud ETL for effortless, maintenance-free pipeline creation.Try Hevo for Free - 2
 Open-source ETL offering flexible, customizable connectors for full control..
Open-source ETL offering flexible, customizable connectors for full control.. - 3
 Enterprise-grade managed ETL with high reliability and seamless scalability.
Enterprise-grade managed ETL with high reliability and seamless scalability.
- 15Tools considered.
- 10Tools reviewed.
 3Best tools chosen.
3Best tools chosen.
Table of Contents
What is Database Replication?
Database replication means storing data at multiple locations so users can access the latest versions from anywhere. It involves copying data from one server to another for uniform availability and sharing.
Database synchronization or replication tools are essential in maintaining consistency across distributed databases, ensuring data integrity, and facilitating error-free data updates between different environments. SQL Server replication tools provide their replication features for replicating data across databases. MySQL offers built-in features and third-party tools for database replication. Some popular replication tools include Hevo Data, Fivetran, AWS DMS, etc.
Here is an overview of the top tools we have curated:
 Try Hevo for Free Try Hevo for Free | |  |  | |  | ||
| Reviews |  4.5 (250+ reviews) | 4.5 (50+ reviews) | 4.3 (100+ reviews) | 4.4 (80+ reviews) | 4.3 (100+ reviews) | 4.2 (400+ reviews) | 4.4 (80+ reviews) |
| Pricing | Usage-based pricing | Volume/capacity-based pricing | Capacity-based pricing | consumption-based pricing | Volumne-based pricing | MAR-based pricing | Consumption-based pricing |
| Free Plan |  | Open source | | | | ||
| Free Trial | 14-day free trial | 14-day free trial | 30 day free trial | 14-day free trial | 14-day free trial | ||
| Overview | Hevo is a proprietary platform for real-time ELT and automated data integration. | Airbyte is an open-source ELT platform with customizable connectors. | Talend offers an open-source platform for ETL, data quality, and master data management. | Informatica is a closed-source, AI-driven data integration solution, offering advanced governance and real-time synchronization. | Qlik Replicate is a closed-source solution offering low-latency, real-time data replication tool. | Fivetran is a closed-source, fully managed data integration tool with pre-built connectors. | Matillion is a closed-source, cloud-native ETL tool optimized for Snowflake, Redshift, and BigQuery. |
| Best Suited For | Businesses that need real-time, fault-tolerant data integration. | Businesses with unique integration and customization needs. | Companies focused on data quality, governance, and security. | Large enterprises with complex workflows. | Enterprises with large datasets needing real-time integration. | Businesses that need easy, low-code data pipeline setup. | Businesses using cloud-native data warehouses. |
| Pricing | Free Tier, Starter at $239 and Professional is $ 679 | Free open-source version, pricing varies for managed services. | Open-source version available; enterprise plans based on users. | Pricing varies based on suite, free trials available. | Pricing depends on features; free trial available. | $1.00 per credit (Starter), $1.50 (Standard), $2.00 (Enterprise). | Pay-as-you-go model, free trials available. |
How do we choose the top 10 Data Replication Tools?
Data Volume & Performance
If your business handles small data workloads, lightweight tools will suffice. However, for larger datasets, look for tools with parallel processing capabilities to enhance performance and processing speeds. This ensures that your tool can handle your current data volume and scale with your future needs.
Cloud vs. On-Premises
Ensure the replication tool you select is compatible with your existing infrastructure. If you’re utilizing cloud services like AWS, Azure, or Google Cloud, or have a hybrid deployment model, the tool should integrate seamlessly into your environment. Cloud-native tools offer flexibility, but on-prem solutions may be more suitable if you have specific control or compliance requirements.
Real-Time vs. Batch Replication
The choice between real-time or batch replication depends on your business needs. If your operations require low-latency data transfer, opt for real-time streaming replication tools. For businesses that can tolerate periodic data updates, batch processing tools are a more cost-effective solution.
Scalability
As your data grows, your replication tool must scale with it. Look for tools that handle increased data volumes efficiently, with auto-scaling capabilities to prevent lag and ensure smooth operations as your business expands.
Customization & Automation
Modern data replication tools should support automatic transformations and easy schema changes with minimal manual intervention. A highly customizable and automated system can reduce complexity and save time, making it easier to manage evolving data structures and business requirements.
Pricing
Pricing models can vary significantly. Tools that follow a pay-as-you-go model offer more flexibility, while enterprise-level fixed pricing may suit larger organizations with predictable usage. For budget-conscious businesses, open-source tools can provide a cost-effective option, though they might come with limitations in terms of support or advanced features.
Security & Compliance
Data security is paramount. Ensure that your replication tool uses end-to-end encryption for data transmission and complies with relevant regulations like GDPR, HIPAA, and others. Look for features such as Role-Based Access Control (RBAC) to manage permissions and safeguard your data.
Vendor Lock-In Risk
Consider the flexibility of switching to other tools or platforms in the future. The tool you choose should store data in portable formats that make it easier to migrate away from the vendor if needed. Avoid being trapped in a solution that makes future transitions costly and complicated.
Having trouble with obsolete or inconsistent data across systems? Hevo’s robust data replication features ensure that your data is constantly synchronized and accessible, eliminating the need to write a single line of code. Our no-code platform allows you to:
- Automate Data Replication: Continuously and reliably replicate data from source to destination in real-time.
- Maintain Data Integrity: Ensure your data stays accurate and consistent across all platforms and tools.
- Enable Real-Time Access: Empower your teams with always-available, up-to-date data for faster decisions and analytics.
Rated 4.4 on G2, Hevo offers a simple solution for your data needs. Discover how companies like Postman have benefited from Hevo. For more details, try a personalized demo for free or explore our Documentation.
10 Top Database Replication Software
1. Hevo Data

Hevo is a real-time ELT no-code data pipeline platform that cost-effectively automates flexible data pipelines to your needs. With integration into 150+ data sources (60+ free sources), we help you not only export data from sources and load data into destinations but also transform and enrich your data, making it analysis-ready.
It’s a fully automated pipeline that offers data to be delivered in real-time without any loss from source to destination. Its fault-tolerant and scalable architecture ensures that data is handled securely and consistently, with zero data loss, and supports various forms of data.
What makes Hevo Amazing
- Zero Data Loss – Hevo’s unique fault-tolerant architecture ensures the completeness of data and reliably moves it without data loss.
- Low time to Implementation – Once the simple setup procedure is complete, Hevo can migrate data in no time.
- Automapping: Hevo automatically analyzes the schema of the data it receives for replication and seamlessly maps it to your data warehouse structure
- Fully Managed – The Hevo platform is fully managed and works out of the box.
- Scalability – Hevo is built to handle data of any scale. With Hevo, your business can grow without any data hiccups.
- Exceptional Support – Technical support for Hevo is provided on a 24/5 basis over both email and Slack.
Pricing
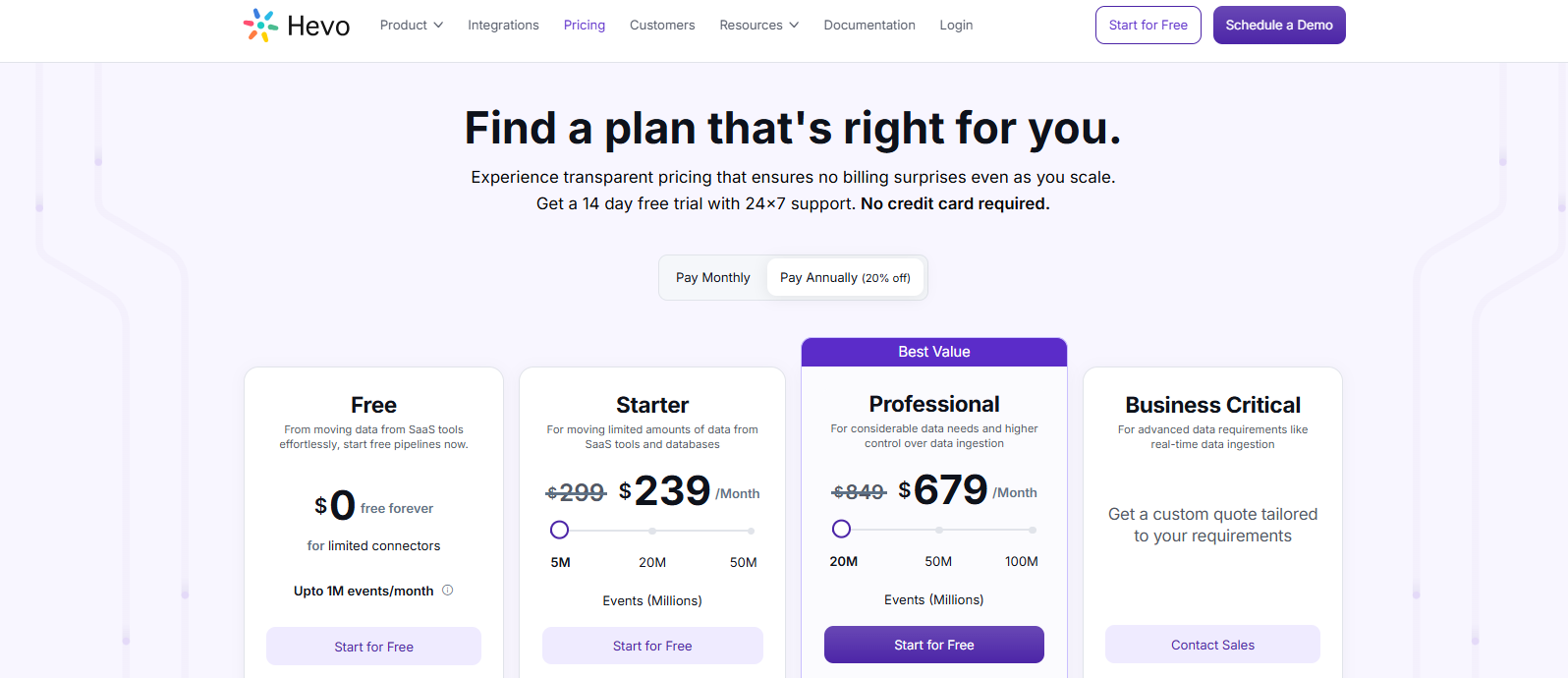
G2 Rating: 4.4 out of 5


2. Airbyte
If your company requires flexibility as well as customization, Airbyte is your go-to tool. Unlike proprietary solutions, Airbyte is open-source, providing you with full control over your data pipelines. It supports over 300+ connectors and allows custom connector creation, making it ideal for businesses with unique integration needs.
Features
- It is an open-source ELT platform supporting over 300 connectors.
- Aids with community-driven customizable connectors for tailored solutions.
- Ensures scalability to handle data from a wide variety of sources and destinations.
- Extensive and customizable platform, allowing developers to build new connectors.
Pros:
- It provides a clean UI to create ELT pipelines
- Its active community and Slack channel keep developers engaged and updated, making it a reliable ETL tool for any data professional.
Cons:
- Airbyte sometimes fails to fetch data from certain sources, and configuring access to in-house databases can be complex
- The tool sometimes lacks up-to-date documentation for certain connectors
Pricing
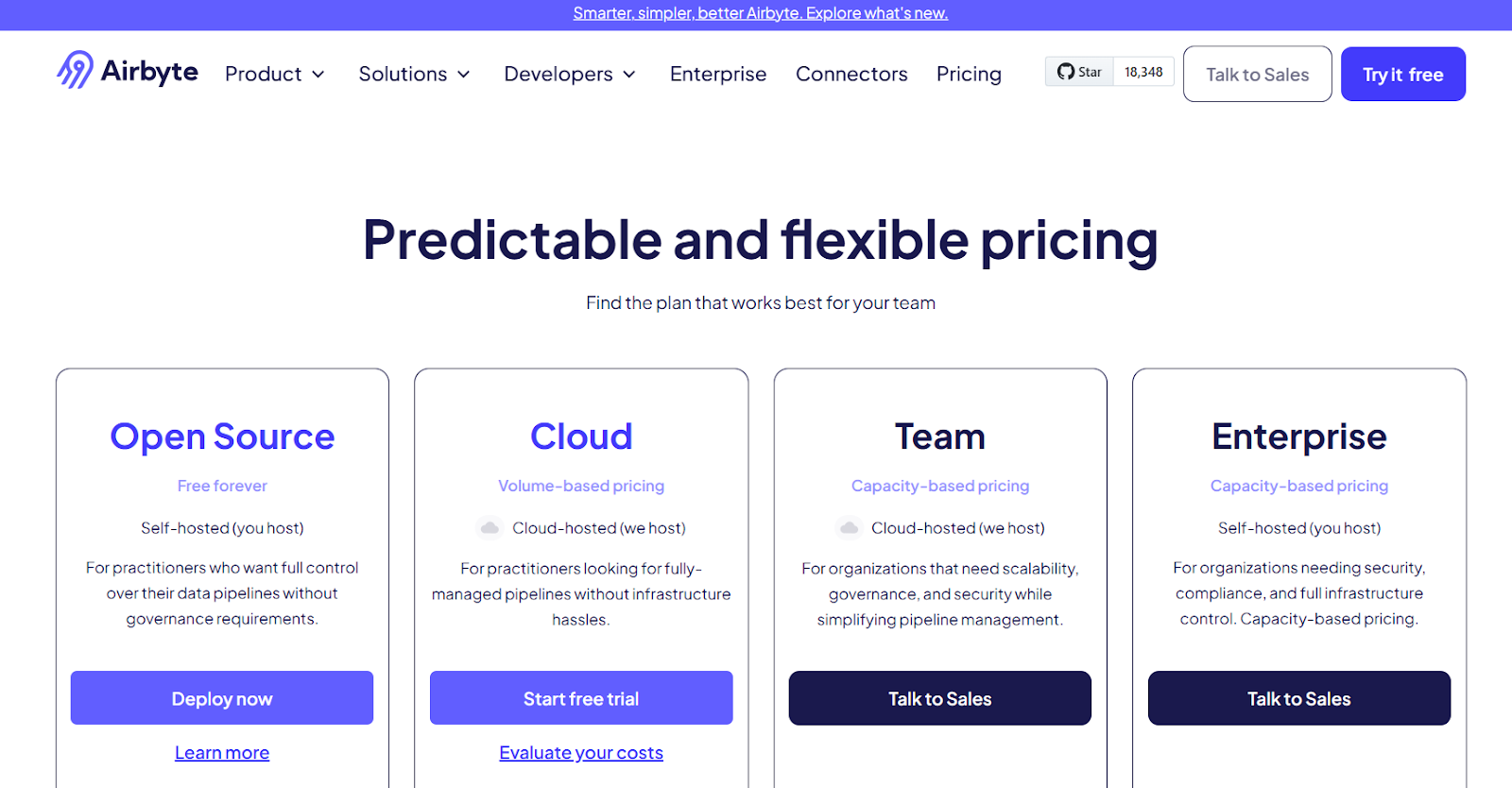
Airbyte offers a free, open-source version. For managed services and additional enterprise features, pricing varies based on your data volume and support needs.
G2 Rating: 4.5 out of 5
3. AWS DMS
If your company deeply depends on the AWS ecosystem, AWS DMS is a natural choice. It provides seamless database replication across Amazon RDS, Aurora, Redshift, and other AWS services, making it ideal for cloud-first businesses.
Features
- AWS DMS migrates databases while keeping the source active, ensuring application availability.
- Compatible with Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle, SQL Server, and SAP ASE.
- Ensures real-time data consistency between source and target databases.
- Multi-AZ support enhances durability and fault tolerance.
- AWS DMS supports the CDC for cost and resource optimization.
Pros:
- It is very easy to set up data migrations between different databases and services and is user-friendly once you learn.
- It even takes care of schema conversion as well , which means if source is relational and destination is non relational
Cons:
- AWS databases can become expensive at scale, especially with high I/O or storage needs.
- AWS DMS is closely tied to the AWS ecosystem, which may create vendor lock-in.
- The service also offers limited customization compared to self-managed databases, which could be a concern for businesses that need more control over their infrastructure.
Pricing
As part of the AWS free tier, you can get started with AWS DMS for free. You can also create your custom pricing and calculate your total spend through their calculator.
G2 Rating: 4.1 out of 5
4. Talend Data Fabric
Talend Data Fabric is more than just a database replication tool – it’s a comprehensive data management platform. If your focus is on data quality, governance, and security, Talend is a strong contender.
Qlik recently acquired Talend, bringing together two powerful platforms to give you smarter, faster access to reliable data. Check this press release if you are curious about Qlick Acquiring Talend.
Features
- Offers ETL, data quality, and master data management tools.
- Supports cloud, on-premises, and hybrid deployments.
- Includes built-in data quality checks to improve accuracy.
- Provides both open-source and enterprise versions.
- An extensive library of pre-built connectors for various systems.
Pros:
- The tool’s user-friendly visual interface makes creating workflows easy and intuitive, allowing users to design and manage data pipelines without extensive technical expertise.
- The tool significantly improves the efficiency of data collection, filtering, and analysis, making it easier for teams to manage and work with secure, well-organized data.
Cons:
- The tool may experience performance and speed limitations, especially when handling large data volumes, and could benefit from improved memory handling and optimization.
- It is expensive when compared to other tools
Pricing
Talend offers an open-source version at no cost, while its enterprise plans, which include advanced features, are priced based on the number of users and the level of support required.
G2 Rating: 4.4 out of 5
5. Informatica
Informatica excels in large-scale enterprise data management, providing a highly scalable and secure data replication solution. With its AI-driven automation, it simplifies complex workflows, enabling organizations to seamlessly manage, clean, and synchronize data across hybrid and multi-cloud environments.
Features
- Enables a comprehensive data integration and management platform.
- Provides you with real-time data integration with support for AI-driven insights.
- It’s scalable for large enterprises and complex workflows.
- Provides you with advanced data governance, security, and quality features.
- Includes data cataloging for effective metadata management.
Pros:
- Easy to use, with a user-friendly interface and low/no-code features
- Wide variety of built-in connectors for different platforms
- Scalable and efficient, handles large volumes of data well
Cons:
- Error reporting and messages can be vague and hard to troubleshoot
- Pricing is high, especially for smaller companies
- Some operational bugs and limitations when running tasks in parallel
Pricing
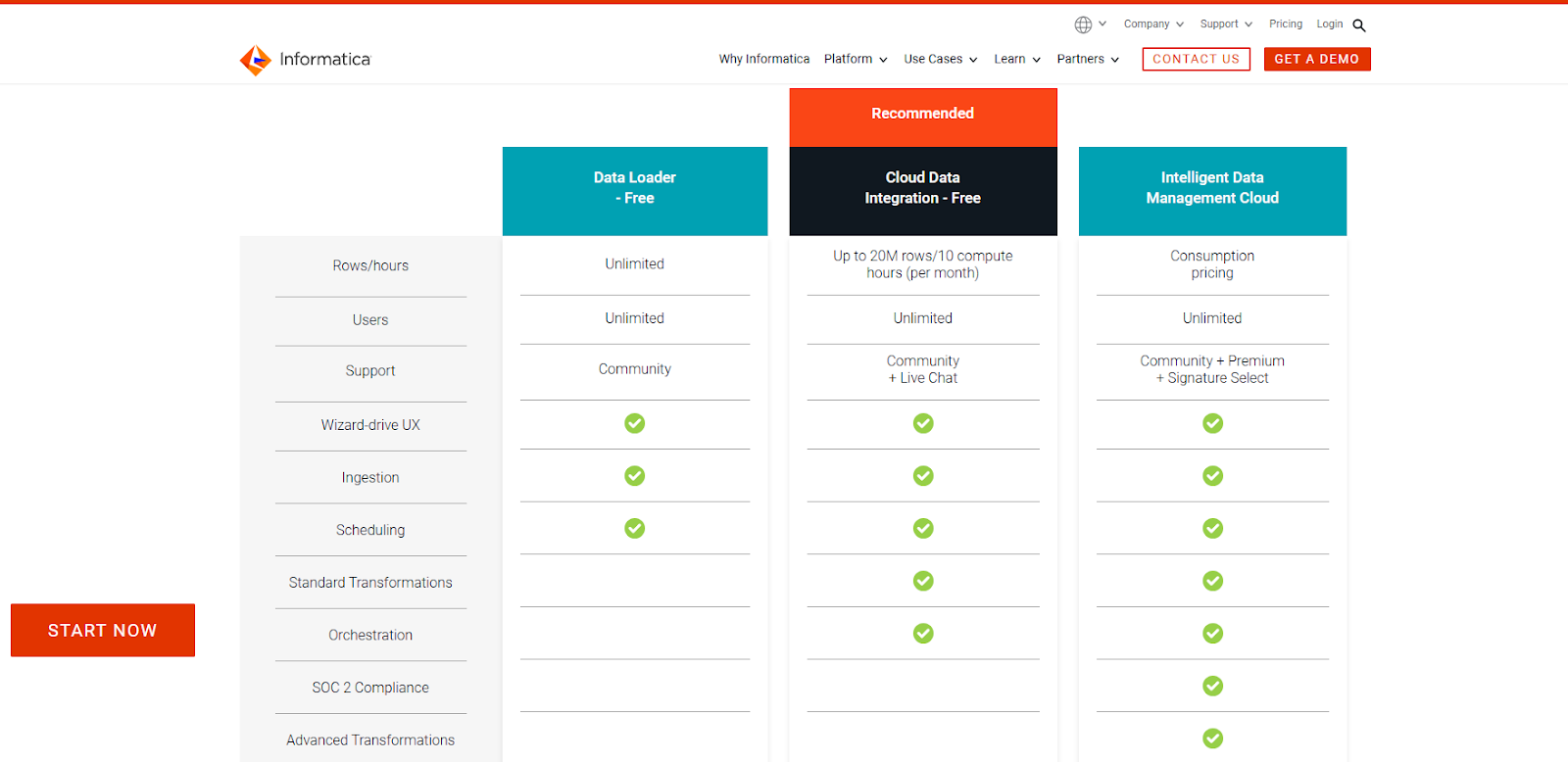
Pricing depends on the product suite and features selected, with enterprise-level plans typically carrying a higher cost. Informatica provides free trials and demos to its customers as well.
G2 Rating: 4.3 out of 5
6. Qlik Replicate

Qlik Replicate is another tool that specializes in large-scale data replication with minimal latency, making it perfect for enterprises dealing with massive datasets.
Features
- Qlik Replicate is a combination of data replication and real-time data integration software. It enables real-time data replication between various databases and data platforms.
- It supports replication between different database systems, providing flexibility for data integration.
- It also integrates with other Qlik products, facilitating end-to-end data integration and analytics workflows.
Pros:
- Easy-to-use graphical interface and centralized monitoring simplify data pipeline management and setup
- Supports a wide variety of databases and endpoints, both on-premises and in the cloud
Cons:
- Steep learning curve, initial setup and understanding system requirements can take time.
- Pricing is higher, and the licensing model could be simpler.
Pricing
The pricing depends on the specific feature you choose, but you can start by taking a free trial.
G2 Rating: 4.3 out of 5
7. Fivetran
Fivetran is a sleek, reliable, and highly intuitive tool. Its biggest strength lies in its vast array of pre-built connectors, making it easy to integrate with virtually any data source.
Features
- Fivetran is suitable for replicating all application databases and files to high-performance data warehouses.
- With an easy five-minute setup, you can standardize your cloud pipelines and have them fully managed without needing maintenance.
- Provides an intuitive, low-code interface that simplifies the creation of data workflows.
- It offers a wide range of pre-built connectors to various data sources.
- It’s optimized for performance and scalability within cloud environments.
Pros:
- Large variety of connectors supporting many popular data sources and destinations.
- Easy integrations with automatic schema adjustments.
Cons:
- Pricing issues with complexity around metered pricing models.
- Data limitations with some restrictions on data volumes or sync frequencies in lower tiers.
Pricing
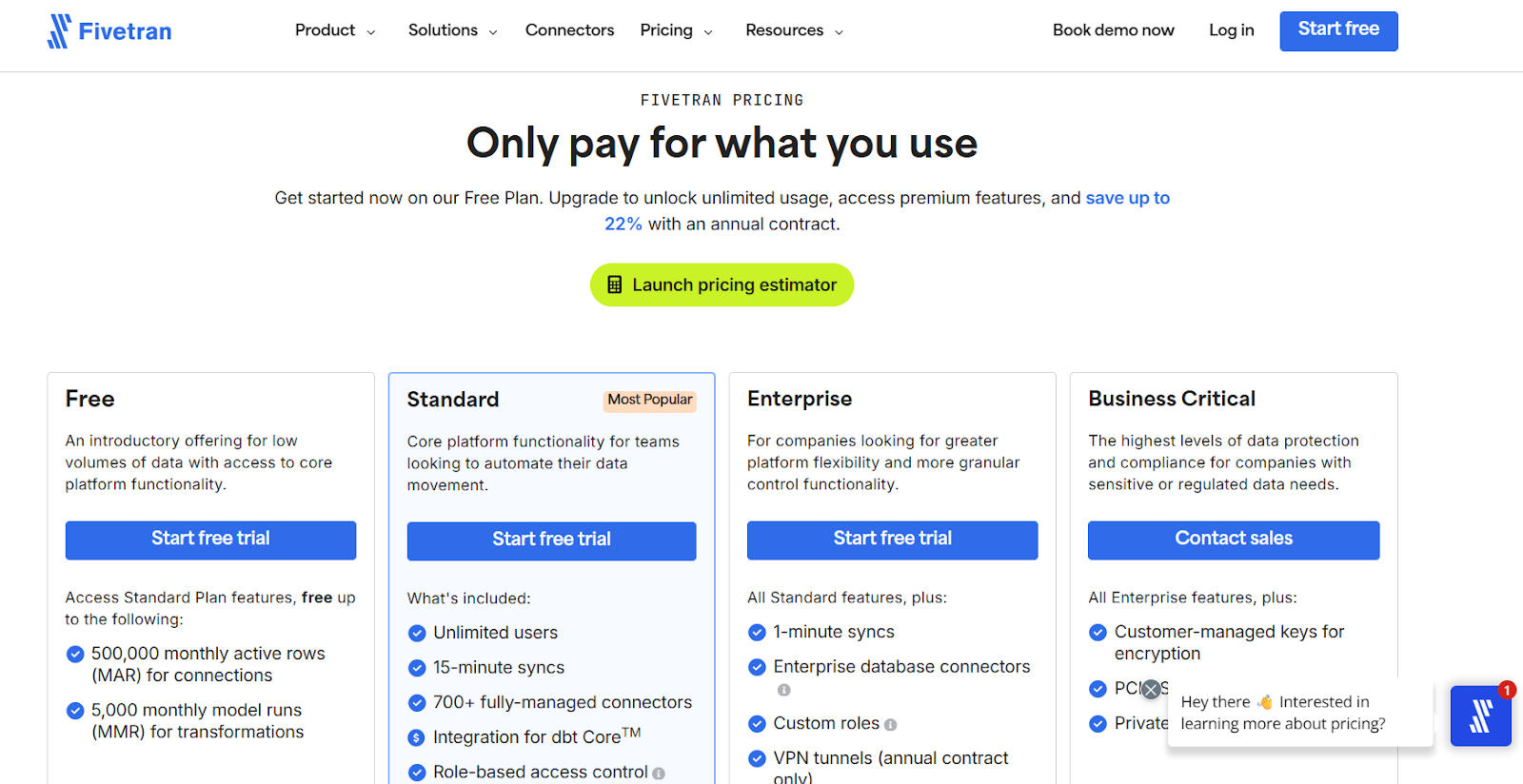
Fivetran pricing varies: $1.00 per credit for the Starter plan, $1.50 per credit for the Standard plan, and $2.00 per credit for the Enterprise plan.
G2 Rating: 4.2 out of 5
8. Carbonite
Carbonite offers comprehensive, fully managed data protection, making it an ideal choice for enterprises seeking robust disaster recovery solutions
Features
- Carbonite Availability, one of the best database replication tools, provides a two-in-one feature for data replication and a disaster recovery option.
- It is one of the few tools that can replicate both physical and virtual environments. Some issues that might exist relate to error handling and restarting server services.
- Prevents downtime and data loss with OpenText Availability. It continuously replicates physical, virtual, and cloud systems.
Pros:
- With just a single click, the failover process is automated, ensuring that your server configuration and all data are available on the other end.
Cons:
- Adding servers to the portal can be time-consuming, especially when authentication and setup take longer than expected.
Pricing
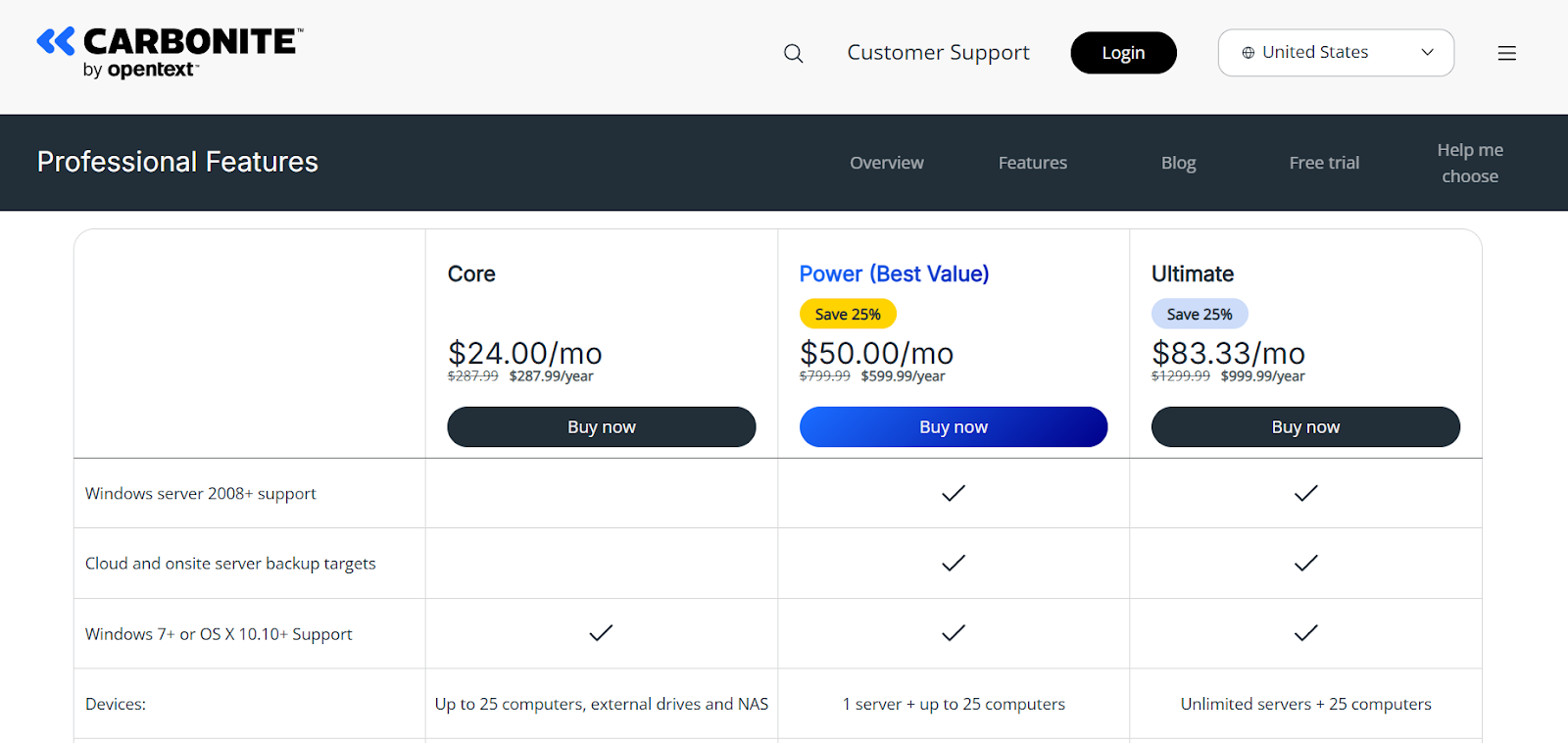
The pricing for Carbonite Availability starts at $1000 per server and adds up depending on the platform used.
G2 Rating: 4.0 out of 5
9. Nakivo Backup and Replication
Nakivo specializes in VMware backup and replication, making it a top choice for hybrid cloud environments. Its fast and incremental backups help reduce storage costs while ensuring minimal downtime.
Features
- Nakivo Backup and Replication is the best data protection solution designed to provide backup, replication, and recovery services for virtualized environments.
- It has a fabulous backup selection that includes virtual machines, cloud workloads, Microsoft 365, and physical machines.
- It also offers an interesting NAS backup solution that enables users to safeguard data from file shares on NAS, Windows, and Linux systems.
Pros:
- The software is easy to install and maintain, offering broad device compatibility, including legacy systems, and providing excellent value with strong support and functionality .
- Offers excellent value with its flexible pricing, making it a great choice for businesses with budget constraints.
Cons:
- Lacks source-based deduplication, resulting in slower backups over low-bandwidth WAN connections and increased storage requirements due to reliance on compression.
- The tool has restricted compatibility with certain hypervisors and applications, limiting its appeal for businesses using a wider range of technologies.
Pricing
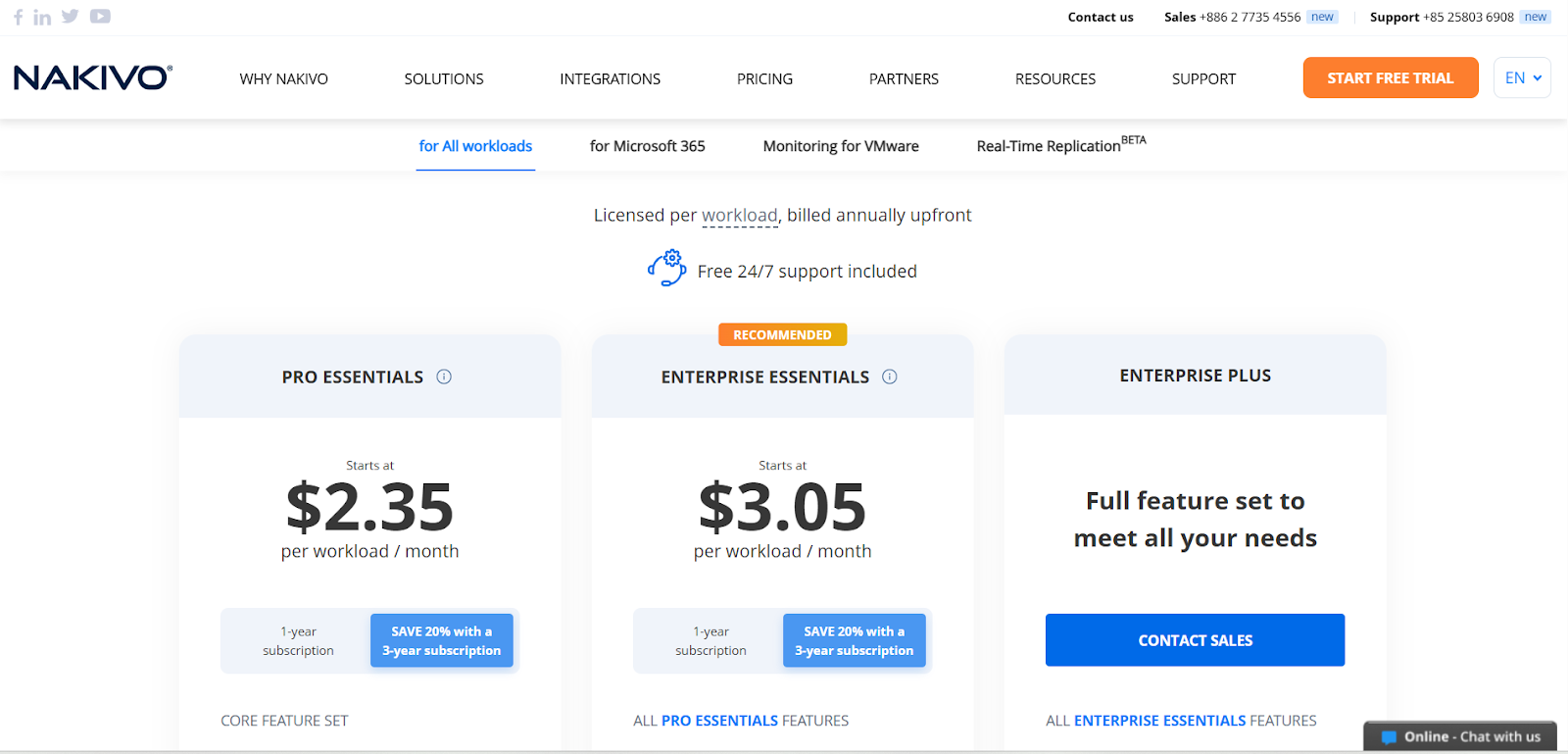
The Nakivo Backup and Replication pricing varies, with $2.35 per workload per month to $3.05 per workload per month.
G2 Rating: 4.7 out of 5
10. Matillion
Matillion is an ELT-first data replication tool for modern cloud environments similar to Snowflake and BigQuery. Unlike traditional ETL tools, it allows you to transform data within your cloud warehouse, improving efficiency and reducing data movement costs.
Features
- Cloud-native ETL tool optimized for Snowflake, Redshift, and BigQuery.
- Visual, drag-and-drop interface for building workflows.
- Supports job orchestration and automation for streamlined processes.
- Pre-built connectors for cloud-native platforms and data sources.
- Focused on in-cloud data transformation at scale.
Pros:
- Simple UI makes user comfortable to configure and easy to understand the flow
Cons:
- This is expensive compared to other tools
- Initial setup and configuration may be complex for beginners
Pricing:
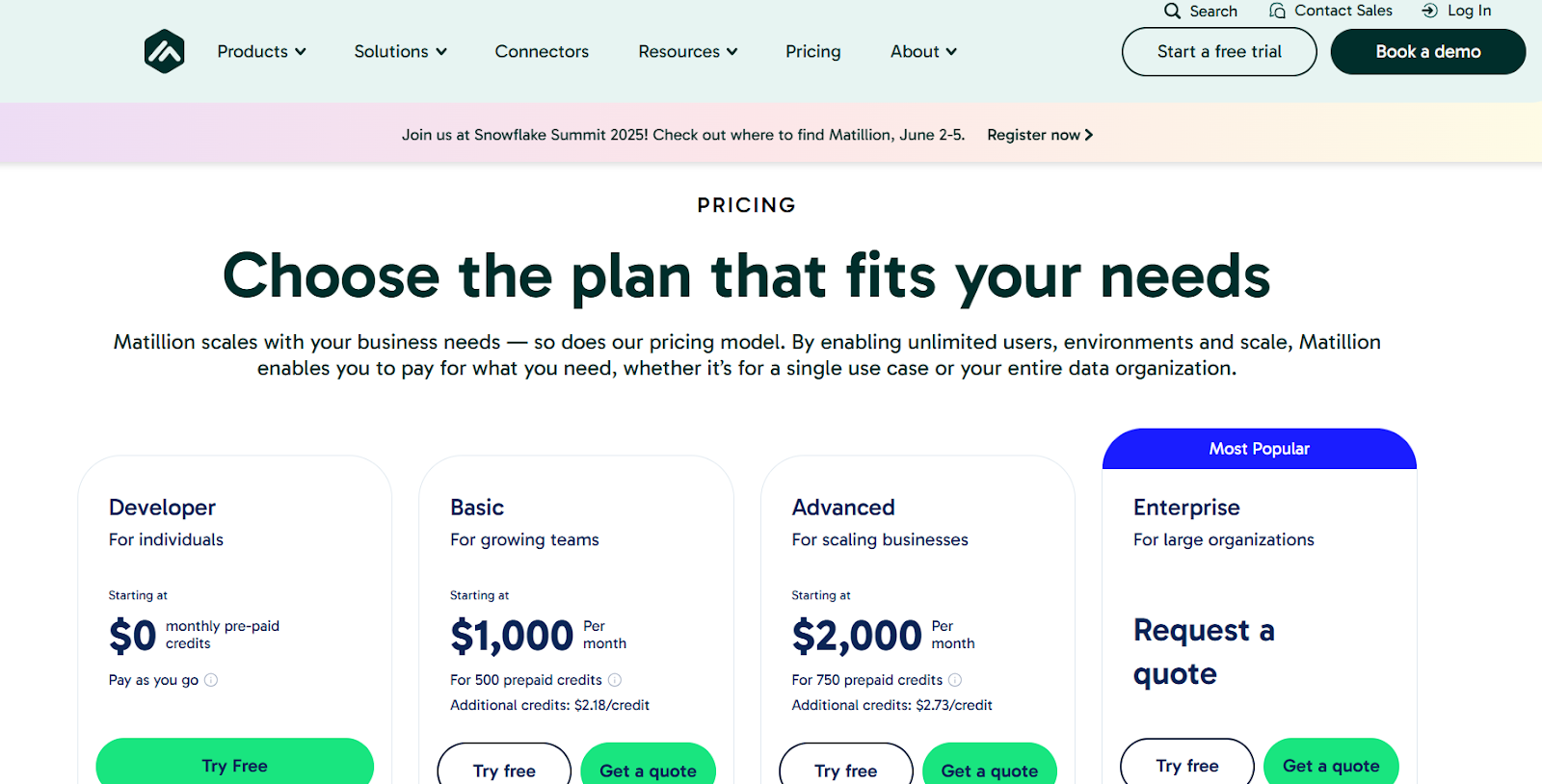
Matillion follows a pay for what you need pricing model, often based on consumption also offers free trials for new users.
G2 Rating: 4.4 out of 5
Importance of Data Replication in Modern Business
Data replication is an essential part of modern business in today’s technological landscape for the following reasons:
- Data Accessibility: Replicating data across various environments provides continuous access to essential information, enabling companies to make informed decisions and drive critical business processes.
- Optimized Data Transfers: Provides you with enhanced data transfers irrespective of your geographical location.
- Optimizing Performance: Sharing data processing tasks between systems boosts the efficiency of your system, primarily during peak user activity periods.
- Reduces Overall Risk: Data replication protects against hardware failures.
- Data Integrity: Helps maintain data consistency and accuracy across multiple locations.
How to Choose the Right Data Replication Tool for Your Business
When selecting a data replication tool, it’s easy to focus on features and pricing, but there are several other crucial factors that should not be overlooked. Your chosen tool must align with your business goals, scalability requirements, and security needs.

A classic example in a reddit thread highlights the need for a balanced approach between real-time data replication (CDC) and the practicalities of dealing with schema changes and hard deletes. This thread presents an excellent example of how organizations should weigh various data replication methods and ETL tools based on their specific needs, constraints, and future goals.
Types of Data Replication
When you replicate data, you can choose from a few different methods depending on how often your data changes and how you want it synced. Here are the three main types you’ll come across:
Snapshot Replication
With snapshot replication, you copy data exactly as it looks at a specific moment. It doesn’t track ongoing changes, just takes a “snapshot” and sends it to the other database. This method works best when your data doesn’t change much between updates.
Merge Replication
Merge replication lets you and others update data in different places, then combines those updates into one consistent version. It’s handy if your users need to work offline or on separate systems and sync changes later.
Transactional Replication
Transactional replication copies changes from one database to another in real time. Every update, insert, or delete is immediately passed on to the replica. This is great when you need your data to be always up to date, like for real-time analytics or reporting.
Conclusion
Choosing the right database replication tool depends on your company’s specific needs. Thus, we recommend that you check out the database replication tools we’ve mentioned above. If you’re dealing with larger chunks of data, tools such as Hevo, Fivetran, or Airbyte are good options. Whereas, for stable data recovery, we recommend Carbonite.
Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
If you’re looking for an all-in-one solution that will help you transfer data and transform it into analysis-ready form, then Hevo Data is the right choice for you! It will take care of all your analytics needs completely automatically, allowing you to focus on key business activities.
FAQs
What is a data replication tool?
A data replication tool copies data from one database to another, ensuring data consistency across systems. Examples include HVR, GoldenGate, and Qlik Replicate.
What are the two basic styles of data replication?
1. Synchronous Replication: In synchronous replication, data is simultaneously written to the primary and secondary (replica) databases.
2. Asynchronous Replication: Data is first written to the primary database and then propagated to the secondary database.
What is the Alternative to Database Replication?
An alternative to database replication is Database Sharding. Sharding involves partitioning the data across multiple databases, or shards, based on a specific criterion (e.g., user ID, geographic location). Each shard contains a subset of the data, and they make up the complete dataset.
How to replicate a database in MySQL?
1. Configure the master server.
2. Configure the slave server.
3. Verify the replication.
What are Common Database Replication Methods?
1. Snapshot Replication
2. Transactional Replication
3. Log-based replication
4. Merge Replication
5. Bi-directional Replication
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





