

In the modern data-centric world, efficient data transfer and management are essential to staying competitive. AWS offers robust tools to facilitate this, including the AWS Database Migration Service (DMS).
Most businesses use a data warehouse for their data storage solution, and one of the leading data warehousing solutions is Amazon Redshift. In 2024, over 11441 companies1 worldwide started using Amazon Redshift as a Big Data Infrastructure tool.
This blog will examine AWS DMS Redshift migration, i.e., how to migrate data to Redshift using AWS DMS. We will also discuss DMS’s limitations and a better alternative. So, let’s get started!
Table of Contents
What is AWS DMS?

AWS Database Migration Service (AWS DMS) is a web service designed to migrate data from on-premise databases, Amazon RDS DB instances, or an Amazon EC2 instance database to a database hosted on AWS services. It can be run in 3 modes:
- Replicate a source database to a destination (also can copy to S3)
- Sync changes from a source database to a destination (known as change data capture or CDC)
- Clone a data source and then keep the source and destination in sync (basically 1, then 2)
Tired of writing long lines of code for replicating your data to Redshift? Unlock the power of your data by effortlessly replicating it using Hevo’s no-code platform. Use Hevo for:
- Seamlessly connect over 150+ other sources without worrying about editions and versions.
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo today to see why Industry Leaders like Cure.Fit, and Whatfix consider Hevo their #1 choice for building a modern data stack.
Get Started with Hevo for FreeKey Components of AWS DMS:
AWS DMS consists of five components:
- Database discovery: DMS Fleet Advisor collects the data from several diverse database environments, providing users with information on their data infrastructure.
- Schema and code migration: You can utilize DMS Schema Conversion to create an initial assessment of the migration complexity for your source data provider and convert database schemas and code objects. You would then apply the converted code against your target database.
- Replication instance: At the highest level, an AWS DMS replication instance is a managed Amazon Elastic Compute Cloud (Amazon EC2) instance hosting one or more replication tasks.
- Endpoint: AWS DMS uses an endpoint to access your source or target data store. You need to enter the following details to create an endpoint:
- Endpoint type – Source or target.
- Engine type – Types of database engines, such as Oracle or PostgreSQL, etc.
- Server name – Server name or IP address for DMS to reach.
- Port – Port number used for database server connection.
- Encryption – SSL mode if it is used to encrypt the connection.
- Credentials – User name and password for various accounts.
- Replication tasks: You can create a replication task to move a data set from the source endpoint to the target endpoint. You need to provide the following details to create a replication task:
- Replication instance
- Source endpoint
- Target endpoint
- Migration type options
You can create an AWS DMS migration by creating the necessary replication instances, endpoints, and tasks in an AWS Region.
How does AWS DMS work?

You can use AWS Database Migration Service (AWS DMS) to migrate your data to and from a few of the most widely used databases. The service supports two types of migrations:
- Homogeneous migrations, such as Oracle to Oracle.
- Heterogeneous migrations between different database platforms, such as Oracle to MySQL or MySQL to Redshift MySQL-Compatible Edition.
In simple words, AWS DMS works in the following steps:
- You create a source and target endpoint to tell AWS DMS from and to where it should migrate the data.
- Next, you schedule a task on this server to move your data.
Then, if tables and schemas don’t exist in the target, AWS DMS creates them. You can also do this manually or use AWS SCT to convert from one schema to another.
What sources and targets does AWS DMS support?
AWS DMS supports various source data stores. A few of them are:
- Oracle versions 10.2 and higher (for versions 10.x)
- SQL Server versions 2005, 2008, 2008R2, 2012, 2014, 2016, 2017, 2019, and 2022.
- MariaDB
- PostgreSQL version 9.4 and higher
- MySQL versions 5.5, 5.6, 5.7, and 8.0
- MongoDB versions 3.x, 4.0, 4.2, 4.4, 5.0, and 6.0
AWS DMS also supports various targets, such as:
- Oracle versions 10g, 11g, 12c, 18c, and 19c
- SQL Server versions 2005, 2008, 2008R2, 2012, 2014, 2016, 2017, 2019, and 2022.
- MySQL versions 5.5, 5.6, 5.7, and 8.0
- Amazon RDS instance databases
- Amazon Redshift
- Amazon Redshift Serverless
- Amazon DynamoDB
- Amazon S3
Prerequisites for Connecting Amazon Redshift using AWS DMS
- Provide basic information about your AWS account and Amazon Redshift cluster, such as your password, user name, and database name.
- The Redshift cluster must be in the same AWS account and the Region as the replication instance.
- Give specific privileges for a table, database, schema, function, procedure, or language-level privileges on Amazon Redshift tables and views.
How to use AWS DMS to configure Redshift as the target?
You can use AWS DMS to configure Redshift as the target using the following steps:
Step 1: Create a Replication Instance
In your AWS DMS console, navigate to the left panel, select the option of ‘Replication Instances,’ and then select ‘Create Replication Instances’
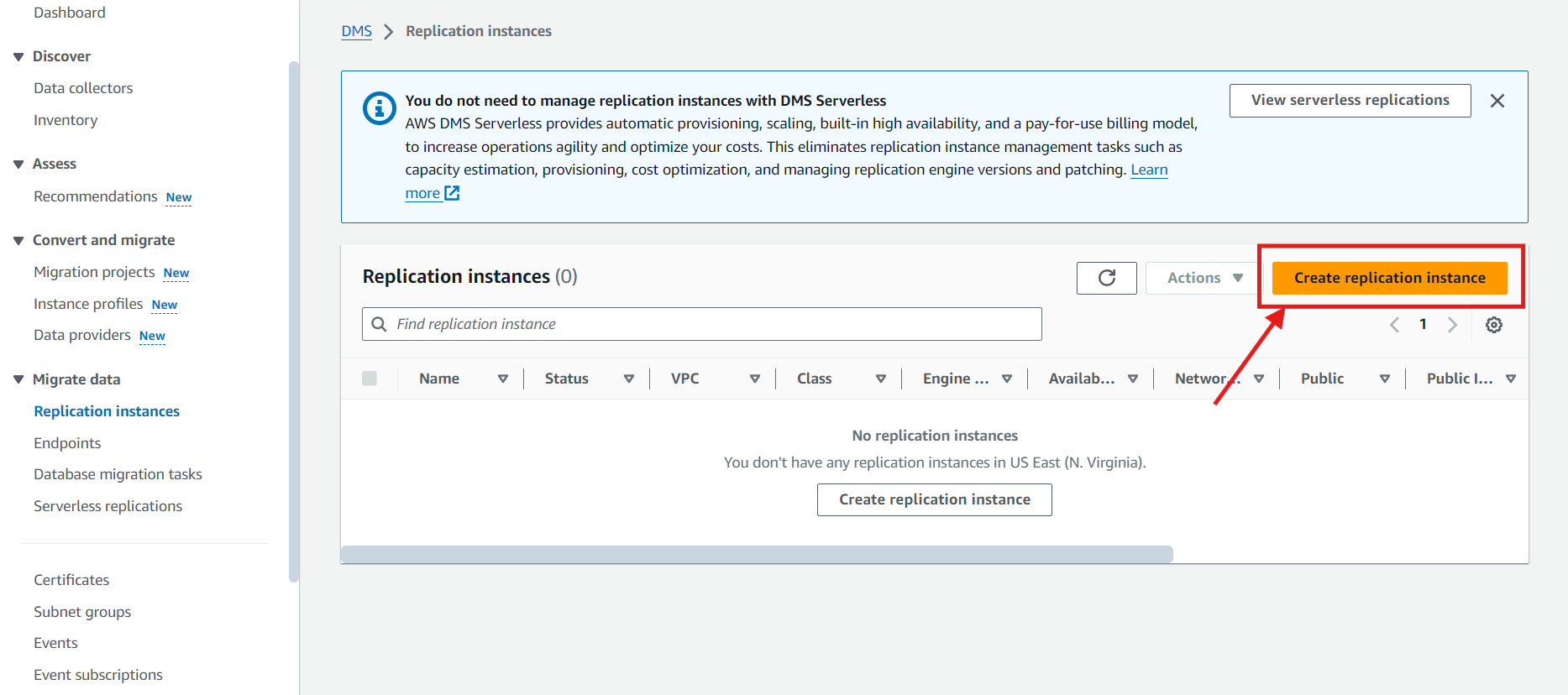
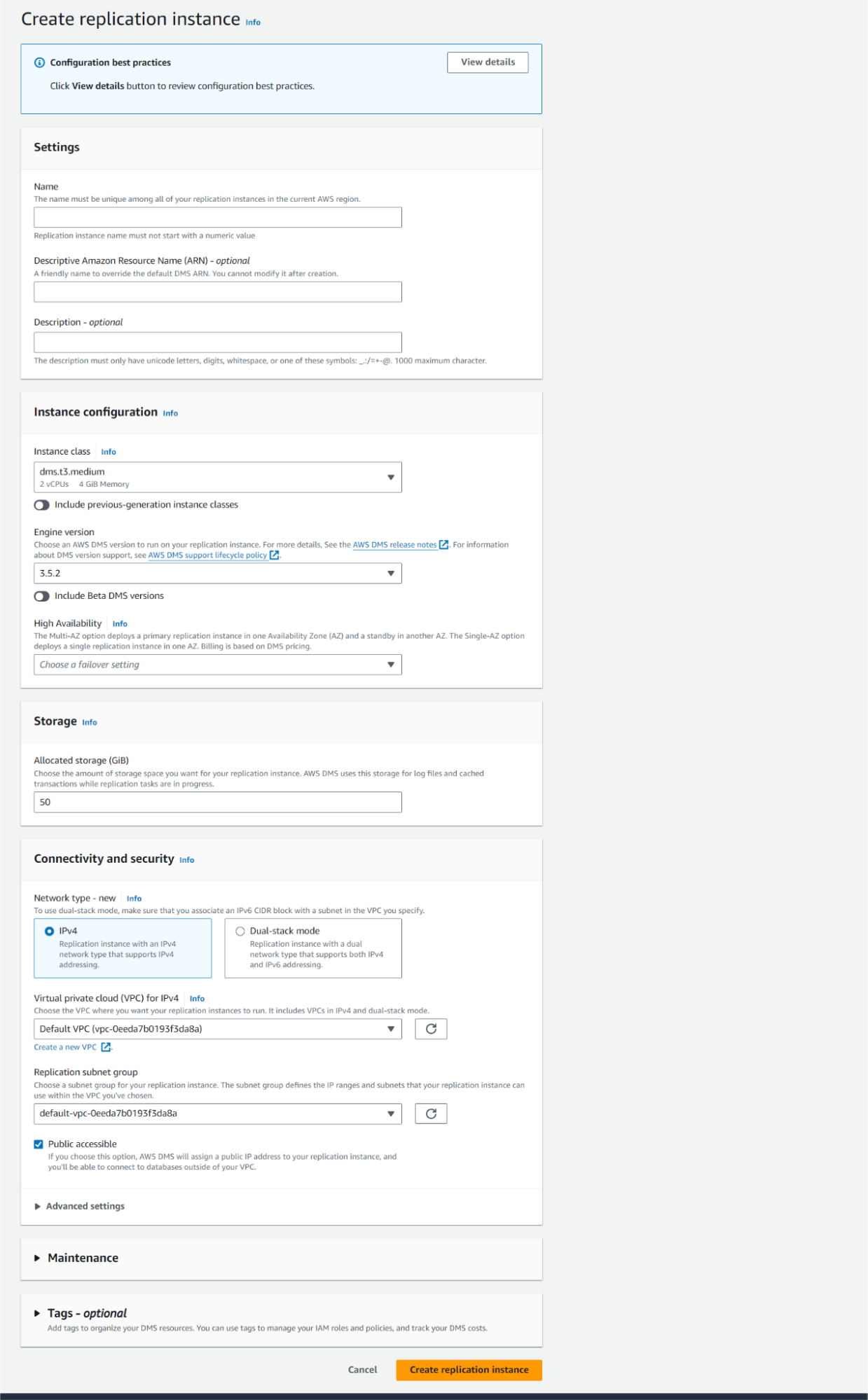
Step 2: Fill in the necessary details.
Fill in the required details like instance class, Engine Version, etc., and then click on ‘Create Replication Instances’
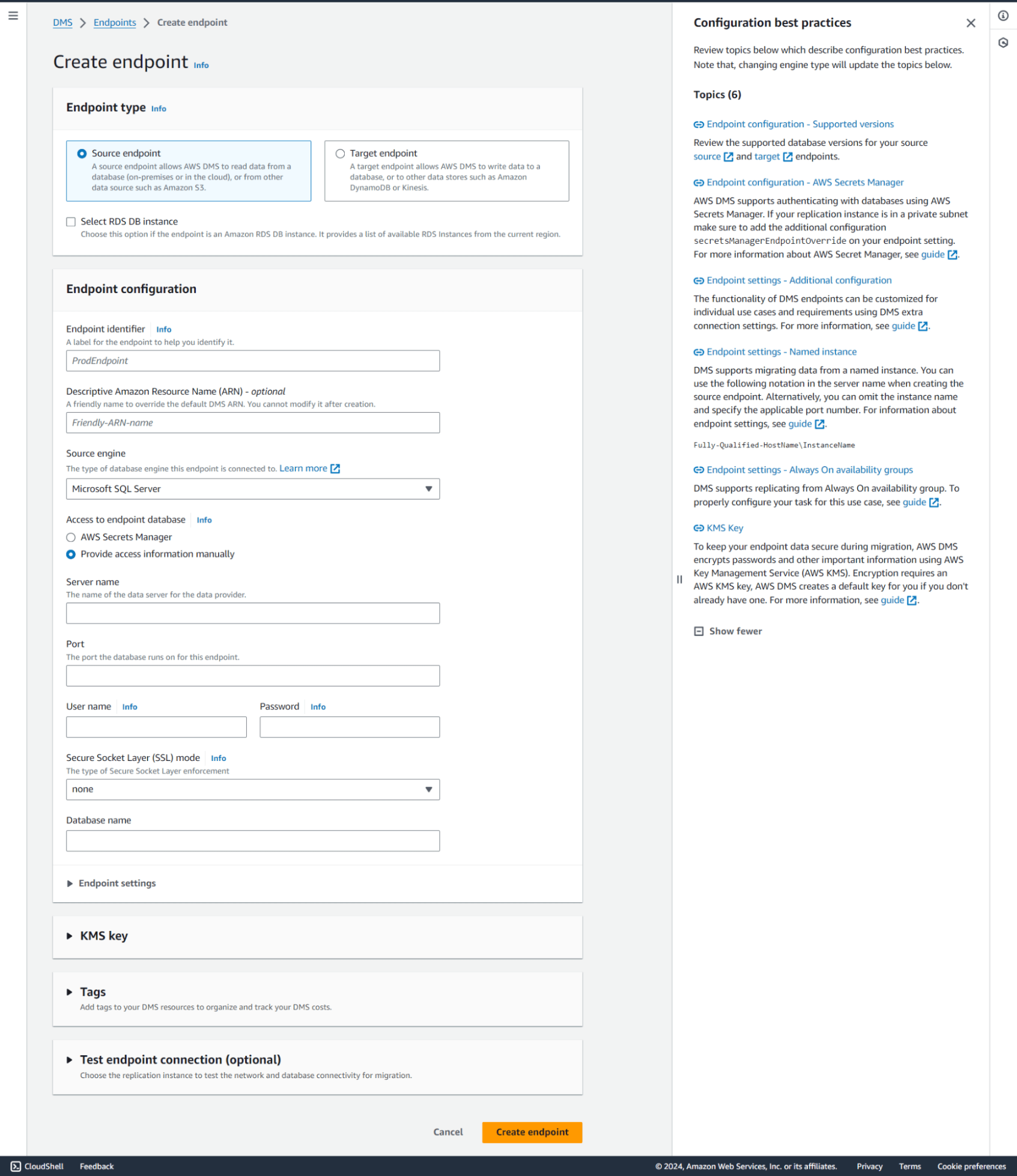
Step 4: Create Source Endpoint
Now that you have created a replication instance, it’s time to create source and target endpoints. Provide details of the source you want to connect to, such as MySQL or Oracle. Give the Server name, port name, etc., and then click ‘Create endpoint.’
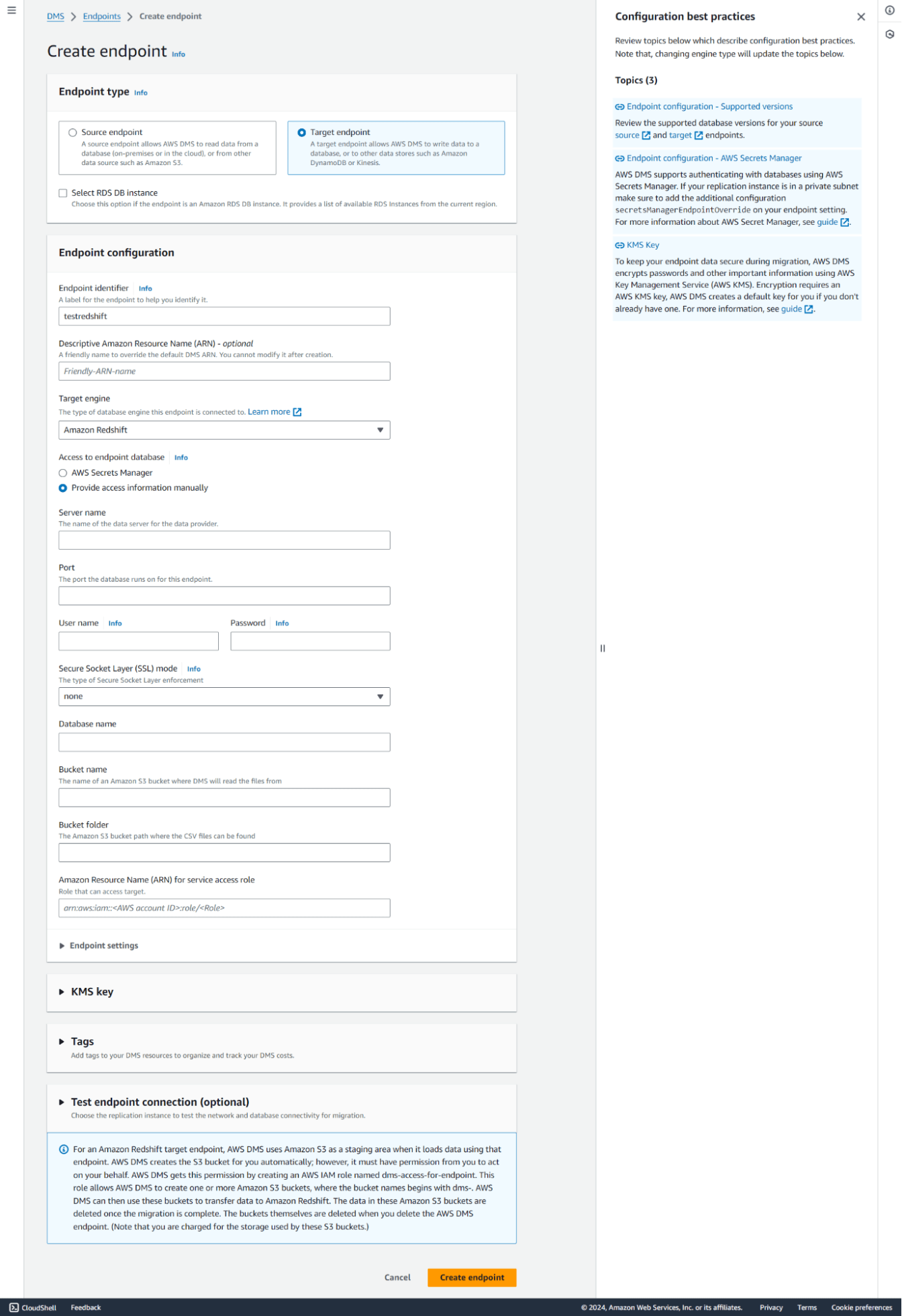
Step 5: Create Target Endpoint
Similarly, create another endpoint for Target and choose ‘Amazon Redshift’ as your Target Engine. Provide the required details and click on ‘create Endpoint.
After your endpoints are created, they’ll be visible in the list of endpoints.
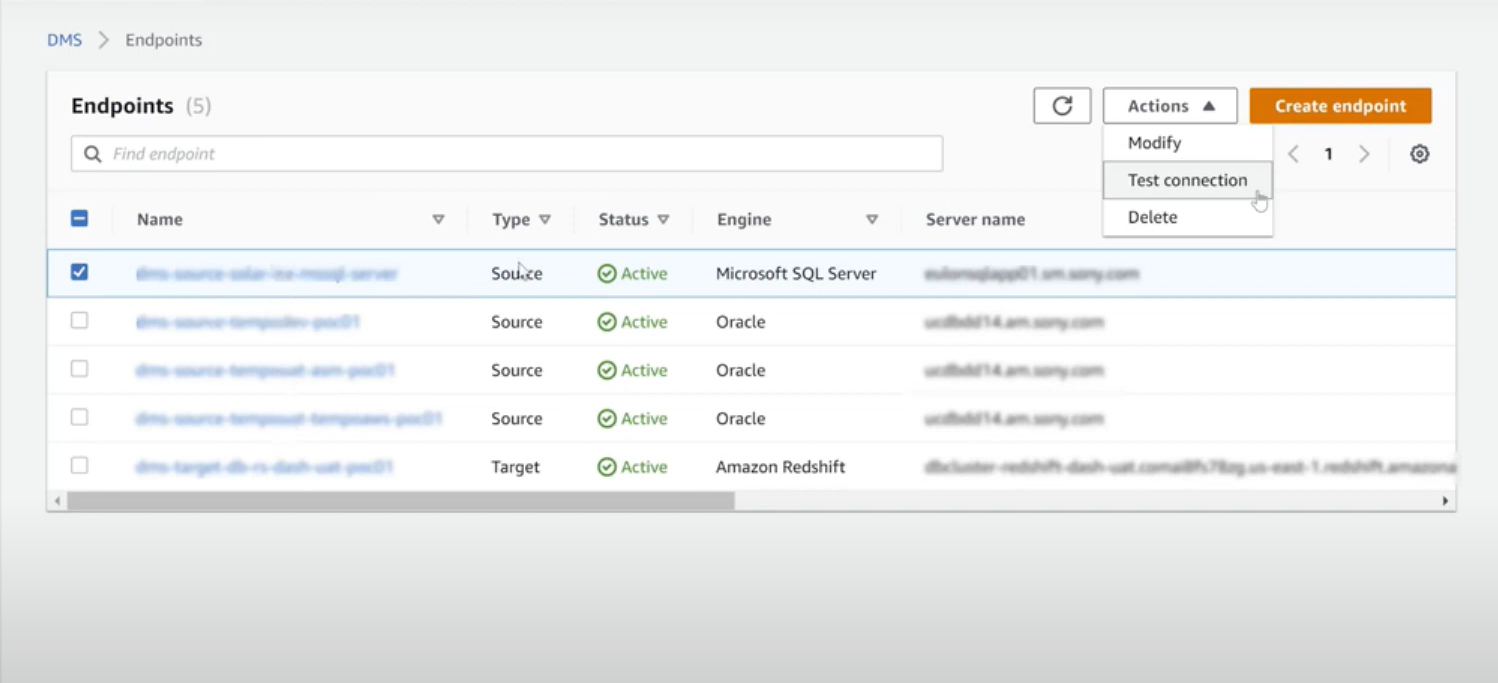
Step 6: Create Database Migration Task.
- Navigate the left panel again, select ‘Database Migration Task,’ and click on ‘Create Database Migration Task.’
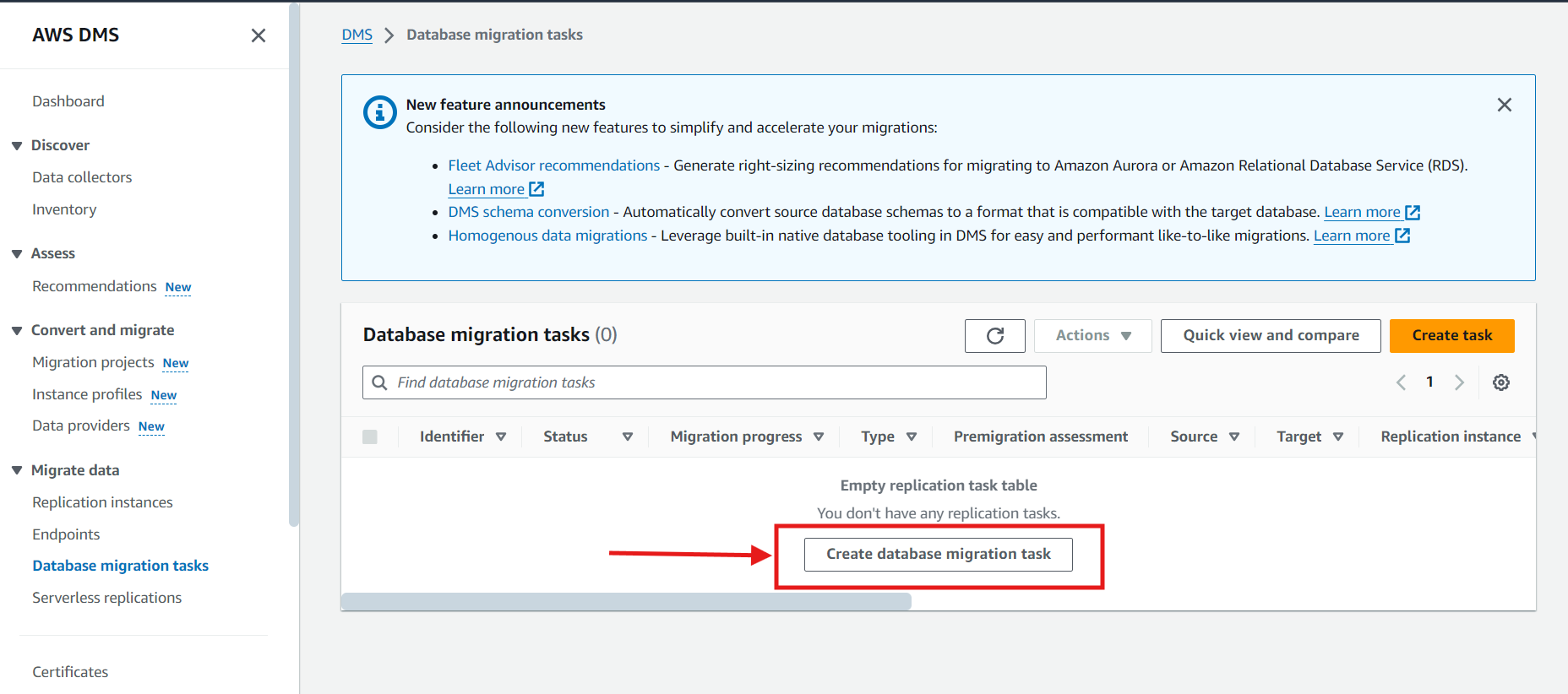
- Now, fill in the required details, such as the Source Endpoint (from where you want to replicate data), Target Database Endpoint (to where you want to replicate data), Migration type, etc., and click ‘Create.’
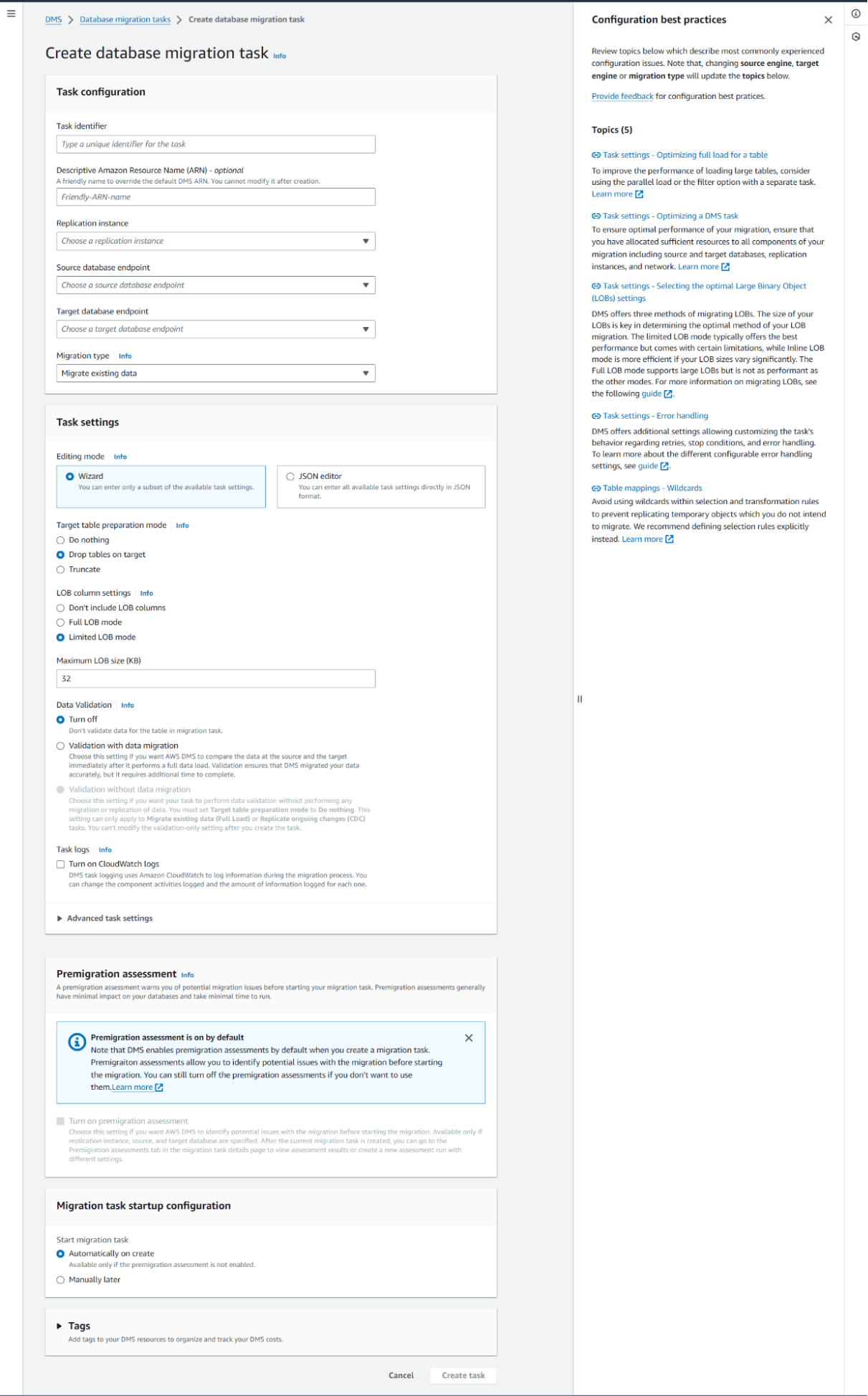
Step 7: Start the Migration Task
Once configured, start the migration task. AWS DMS will move data from Source to Amazon Redshift based on the defined settings.
Step 8: Monitor and Optimize:
Monitor Progress: Monitor the migration task’s progress using AWS DMS monitoring tools and Amazon CloudWatch.
Optimize Performance: Adjust task settings as necessary to optimize performance.
Limitations of using AWS DMS.
AWS DMS seems like an effective data pipeline solution, but it also has various limitations to it:
- Version and Edition are limited to multiple sources and targets.
- DMS does not support specific types of tables(nested, virtual, materialized, temp).
- AWS DMS doesn’t support long object names (over 30 bytes) and needs to export manually.
- One of the requirements for using AWS DMS is that one of your endpoints must be on an AWS service. You can’t use AWS DMS to migrate from an on-premises database to another on-premises database.
- Amazon Redshift doesn’t support VARCHARs larger than 64 KB, and LOBs from traditional databases cannot be stored in It.
- DMS connects to both the source and destination databases as a client.
- DMS does not have the physical layout or capabilities of the source system. Running the wrong things in parallel can very easily slow down database clones.


Hevo’s Redshift Replication as compared to AWS DMS Redshift Replication
To solve these problems, we have a better automated pipeline solution for you. Try Hevo, an automated ETL platform that seamlessly migrates your data from 150+ sources in just two simple steps.
Step 1: Configure your source.
You can choose from a list of 150+ connectors, including RDBMS Sources such as MySQL, Oracle, PostgreSQL, and SQL Server, SaaS Sources like Snowflake, Salesforce, HubSpot, Marketo, and Mailchimp, and Webhooks and REST API.
Step 2: Configure your destination(Redshift)
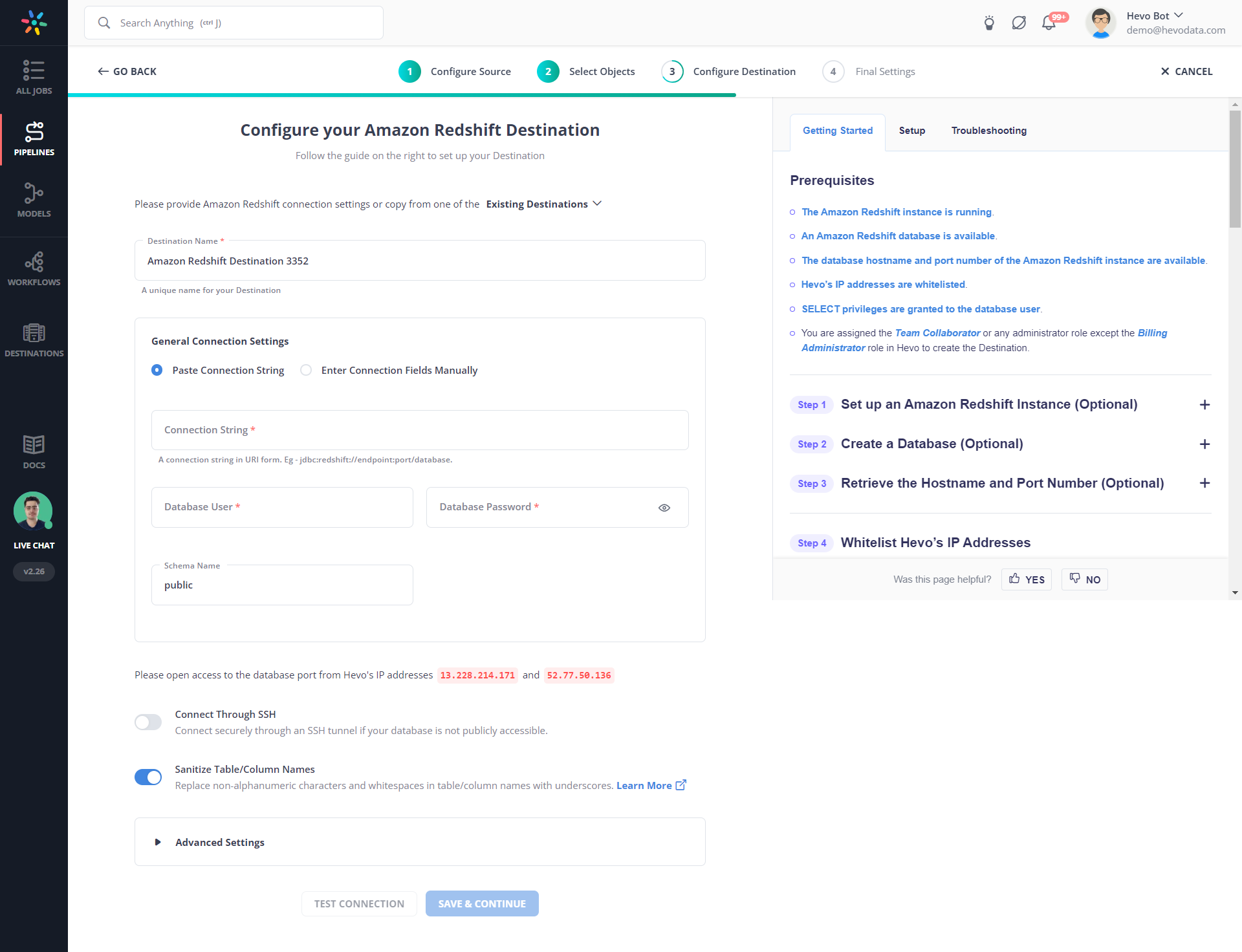
Hevo not only connects your source and destination in minutes but also provides various other features, a few of which are:
- Multiple Workspaces within a Domain: This feature allows customers to create multiple workspaces with the same domain name.
- ELT Pipelines: Hevo’s no-code ELT Pipelines can quickly load huge volumes of data from diverse sources into your desired destination. Then, you can use Hevo’s platform to transform your data.
- In-built Transformations: The Python code-based and Drag-and-Drop Transformations in Hevo allow you to cleanse and prepare the data.
- Post-Load Transformations: Once the data is in the Destination, you can transform it further for analysis by configuring dbt™ Models, creating SQL Models, and combining them in Workflows.
- Historical Data Sync: This is for both Database and SaaS sources.
- Flexible Data Replication Options: You can replicate entire databases, specific tables, or individual columns. You can also customize the data that you want to load.
- On-Demand Credit and Usage-based Pricing: On-Demand Credit helps you continue loading data without interruption, even when your Events quota is exhausted. Hevo offers very competitive tier-based pricing along with 60+ free sources.
References
- Amazon Redshift Statistics by 6Sense.
Conclusion
In this blog, we discussed the steps for AWS DMS Redshift migration, its limitations, and an alternative to solve those limitations. To sum it up, AWS DMS is an effective tool for data migration with lots of potential, but it does not give users the best migration experience in some ways.
If due care is taken in planning, correct settings of the AWS IAM role, configuration of the replication instance, and well-defined migration tasks, then you can ensure a frictionless, efficient migration process. But doesn’t that sound too tedious and time-consuming? A better solution is using Hevo, an automated data pipeline solution that makes data migration a simple two-step process. Sign up for our 14-day free trial and experience seamless data migration to destinations like Redshift.
Frequently Asked Questions
1. What is DMS in Redshift?
AWS Database Migration Service (DMS) helps migrate databases to Redshift with minimal downtime by continuously replicating changes from the source to the target database.
2. Is AWS DMS an ETL tool?
No, AWS DMS is primarily a migration tool, not a full-fledged ETL tool. It can perform some transformations during migration but lacks extensive transformation capabilities.
3. What is the difference between AWS DMS and SCT?
AWS DMS: Focuses on migrating data with continuous replication and minimal downtime.
AWS Schema Conversion Tool (SCT): Converts database schema from one database engine to another, such as from Oracle to PostgreSQL.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





