




Are you trying to choose between AWS Data Pipeline and AWS Glue? Are you figuring out how these AWS ETL tools differ in features, application, pricing, etc.? Do you want to know which service best suits your organizational needs? If so, then you are at the right place.
This blog will compare two popular ETL solutions from AWS: AWS Data Pipeline vs. AWS Glue. It will examine their nuanced differences and help you zero in on one.
Table of Contents
What Is AWS Data Pipeline?

AWS Data Pipeline is a web service on the Amazon Cloud that helps you automate your data movement processes. This is done through workflows that make subsequent data tasks dependent on the successful completion of preceding tasks. These workflows make it possible for you to automate and enhance your organization’s ETL on the AWS cloud.
Simply put, AWS Data Pipeline is an AWS service that helps you transfer data on the AWS Cloud by defining, scheduling, and automating each task.
For example, you can build a data pipeline to extract event data from a data source on a daily basis and then run an Amazon EMR (Elastic MapReduce) over the data to generate EMR reports.
A tool like AWS Data Pipeline helps you transfer and transform data spread across numerous AWS tools and also enables you to monitor it from a single location.
Ditch the manual process of writing long commands to migrate your data and choose Hevo’s no-code platform to streamline your data migration and transformation.
With Hevo:
- 150+ connectors (including 60+ free sources).
- Eliminate the need of manual schema mapping with the auto-mapping feature.
- Seamlessly perform both pre-load and post-load data transformations.
- Benefit from transparent, pay-as-you-go pricing with tiers to meet different data needs.
Experience Hevo and see why 2000+ data professionals including customers, such as Thoughtspot, Postman, and many more, have rated us 4.4/5 on G2.
Get Started with Hevo for FreeKey Features of AWS Data Pipeline
- It is easy to debug or change your data workflow logic since AWS Data Pipeline allows you to exert full control over the compute resources that execute your business logic.
- It has an architecture with high availability and fault tolerance. Thus, it can run and monitor your processing activities effectively.
- AWS Data Pipeline is highly flexible. You can write your own conditions/activities or use the in-built ones to take advantage of the platform’s features, such as scheduling, error handling, etc.
- It provides support for a wide variety of data sources ranging from AWS to on-premises data sources.
- In addition to transferring your data, AWS Data Pipeline enables you to define activities like HiveActivity (will run a Hive query on an EMR cluster), PigActivity (runs a Pig script on an EMR cluster), SQLActivity (runs a SQL query on a database), EMRActivity (runs an EMR cluster), etc. to help you process or transform your data on the cloud.
What Is AWS Glue?

AWS Glue is a serverless, fully managed ETL service on the Amazon Web Services platform. It provides a quick and effective means of performing ETL activities like data cleansing, data enriching, and data transfer between data streams and stores. AWS Glue was built to work with semi-structured data and has three main components: data catalog, ETL engine, and scheduler. It also has a feature known as “dynamic frame.” A dynamic frame is a data abstraction that organizes your data into rows and columns where each record is self-describing and does not require users to specify a schema initially.
At a higher level, AWS Glue Data Catalog is a big data cataloging tool that enables you to perform ETL on the AWS Cloud.
Key Features of AWS Glue
- AWS Glue can automatically generate code to perform your ETL after you have specified the location or path where the data is being stored.
- With AWS Glue, you can set up crawlers to connect to data sources. This helps classify the data, obtain the schema, and automatically store it in the data catalog for ETL jobs.
- It is easy to set up continuous ingestion pipelines for preparing streaming data on the fly with the help of Glue’s serverless streaming ETL function. The streaming data is also available for analysis within seconds. This feature makes it easy to process event data such as clickstreams, network logs, etc.
- Furthermore, AWS Glue also has an integrated data catalog with table definitions and other control information that helps you manage your AWS Glue environment. The data catalog will automatically compute statistics and register partitions to make your queries efficient and cost-effective.
- Glue can also clean and prepare your data through FindMatches, its transform feature. FindMatches helps you locate matching records and dedupe your data.
AWS Data Pipeline vs AWS Glue vs Hevo
You can get a better understanding of Hevo’s Data Pipeline as compared to AWS Glue & AWS Data Pipeline using the following table:
| Features | AWS Data Pipeline | AWS Glue | Hevo Data |
| Specialization | Data Transfer | ETL, Data Catalog | ETL, Data Replication, Data Ingestion |
| Pricing | Pricing depends on usage frequency and setup (AWS/on-premise). | Monthly for Data Catalog; Hourly for Glue ETL. | Flexible & transparent pricing; Free, Starter & Business tiers. |
| Data Replication | Full table; Incremental via Timestamp Field | Full table; Incremental via CDC through AWS DMS. | Full table; Incremental via SELECT, Replication key, Timestamp & CDC. |
| Connector Availability | It supports DynamoDB, SQL, Redshift, and S3. | Supports Amazon platforms (Redshift, S3, RDS, DynamoDB) & JDBC. | 150+ native connectors; integrates with Redshift, BigQuery, Snowflake, etc |
| Ease of Use | JSON-based configuration can be complex. | Visual interface for ETL jobs; automated schema discovery. | Intuitive, user-friendly interface with no-code setup. |
| Support and Documentation | Comprehensive documentation; limited direct support. | Extensive documentation and AWS support plans. | 24/5 support, extensive documentation, and resources. |
| Data Transformation Capabilities | Limited; relies on other AWS services for complex transformations. | Advanced capabilities with built-in transforms and custom code. | Advanced features with built-in functions and custom transformations. |
| Integration with Cloud Platforms | Primarily integrates with AWS cloud services. | Integrates with AWS cloud services and third-party databases via JDBC. | Integrates with a wide range of cloud platforms such as databases, data warehouses |
| Security and Compliance | Leverages AWS security and complies with major standards. | Integrates with AWS security features and is compliant with industry standards. | Robust security; data encryption, access control, GDPR, SOC2 Type 2, HIPAA compliance. |

Factors That Drive the AWS Data Pipeline vs. AWS Glue Decision
Now that you are familiar with AWS Data Pipeline and AWS Glue, let’s directly compare the two services. These are the top parameters to consider when contemplating AWS Data Pipeline vs. AWS Glue:
1) Infrastructure Management
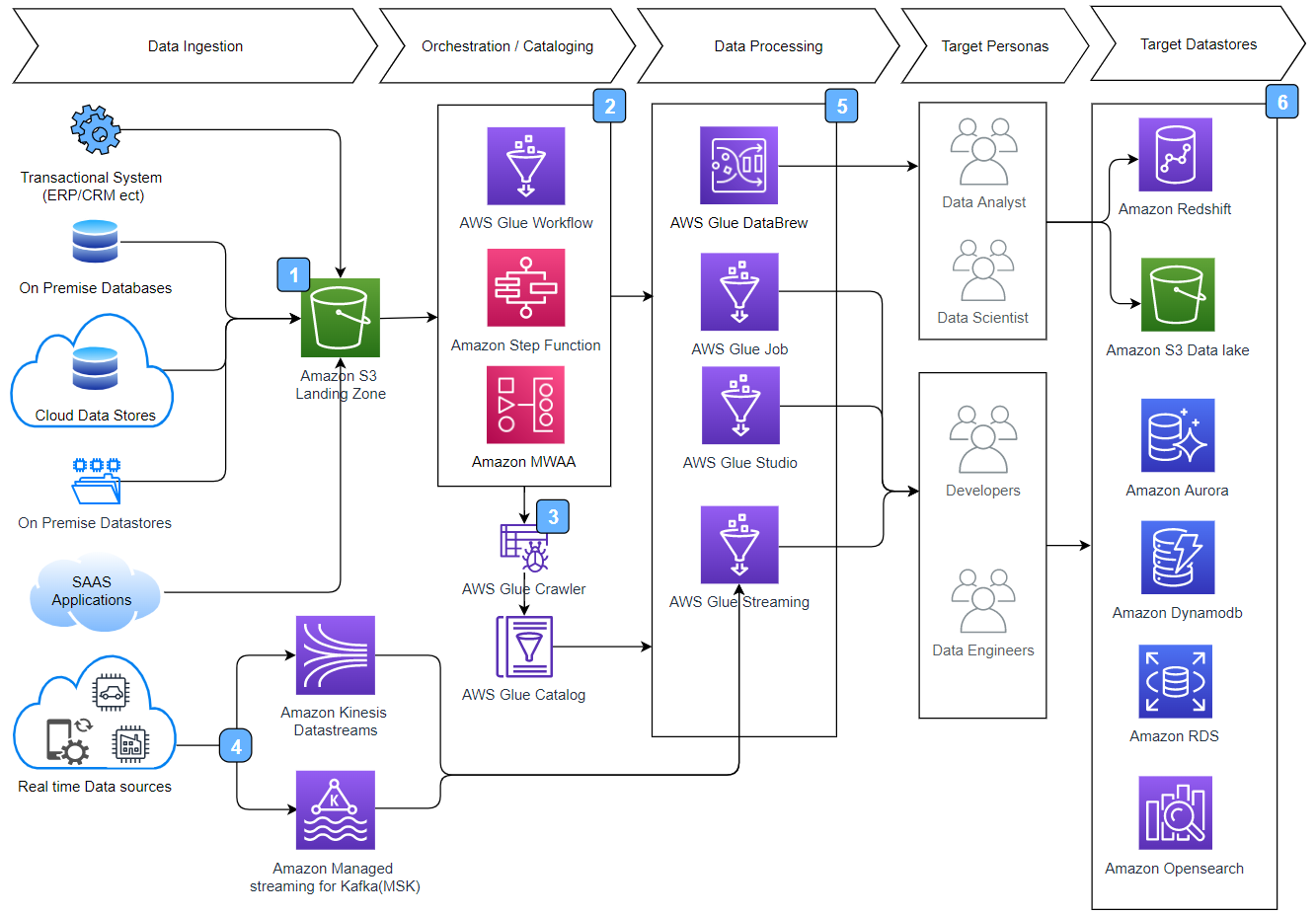
AWS Glue is serverless, so developers have no infrastructure to manage. Glue’s Apache Spark environment fully manages scaling, provisioning, and configuration.
AWS Data Pipeline is not serverless like Glue. It launches and manages the lifecycle of EMR clusters and EC2 instances to execute your jobs. You can define the pipelines and have more control over the compute resources underlining them.
These are important factors while doing an AWS Data Pipeline vs AWS Glue comparison, as this will determine the kind of skills and bandwidth you would need to invest in your ETL activities on the AWS cloud.
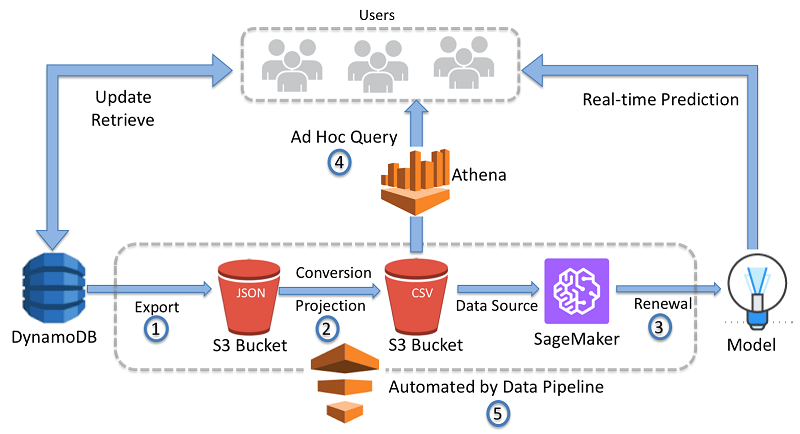
2) Operational Methods
AWS Glue provides support for Amazon S3, Amazon RDS, Redshift, SQL, and DynamoDB and also provides built-in transformations. On the other hand, AWS Data Pipeline allows you to create data transformations through APIs and also through JSON, while only providing support for DynamoDB, SQL, and Redshift.
Additionally, AWS Glue supports the Apache Spark framework (Scala and Python), while AWS Data Pipeline supports all the platforms supported by EMR and Shell.
Data transformation functionality is a critical factor while evaluating AWS Data Pipeline vs AWS Glue, as this will impact your particular use case significantly.
3) Compatibility / Compute Engine
AWS Glue runs your ETL jobs on its virtual resources in a serverless Apache Spark environment.
AWS Data Pipeline does not restrict to Apache Spark and allows you to use other engines like Pig, Hive, etc. This makes it a good choice for your organization if your ETL jobs do not require the use of Apache Spark or multiple engines.
4) Pricing
Pricing is one of the most important factors to consider when deciding which of the two tools to adopt for your organization. Below is a high-level pricing summary for both services beyond their respective free tiers.
AWS Data Pipeline charges a fee of $1 per month per pipeline if it is run more than once a day and $0.68 per month per pipeline if run one time or less per day. You are also required to pay for EC2 and any other resources you may consume.
AWS Glue charges $0.44 per Data Processing Unit hour, billed at every second of use. Data Processing Units are consumed when you run crawlers or jobs. $1 is also charged per 100,000 objects that you manage in the data catalog, and also $1 per million requests to the data catalog.
When considering comparing AWS Data Pipeline with AWS Glue, it is important to consider the type, frequency, and objects involved in your ETL activity, as this will significantly impact your costs.
5) Use Cases
AWS Data Pipeline transforms and moves data across AWS components. It also gives you control over the compute resources that run your code and allows you to access the Amazon EMR clusters or EC2 instances. For example, you can use AWS Data Pipeline to create a template to move DynamoDB tables from one region to another with EMR.
AWS Glue is best used to transform data from its supported sources (JDBC platforms, Redshift, S3, RDS) to be stored in its supported target destinations (JDBC platforms, S3, Redshift). Using Glue also lets you concentrate on the ETL job as you do not have to manage or configure your compute resources. For example, you can infer a schema from data in an S3 location and build a virtual table through Glue Crawler. You can then run a Glue transformation job and also use the JDBC drivers to connect to Athena to query the virtual table.
When Should You Choose AWS Glue?
AWS Glue suits those who want to get started with a managed ETL service that makes it easy to prepare and catalog data. Generally, it would be a good value when you’re already deep within the AWS ecosystem and require rich data transformation and real-time processing with AWS Glue Streaming or Redshift, S3, and RDS integration. AWS Glue is an automated, serverless option that meets the scaling needs of data in processing and provides a more complete data catalog for data management.
When Should You Choose AWS Data Pipeline?
AWS Data Pipeline enables customers to copy data from one location to another and perform batch processing across various AWS services and customer premises. Specifically, it’s helpful if you need to automate a data workflow, manage complex data dependencies, or run periodic data processing tasks. Consider using AWS Data Pipeline if you need more granular control over your pipeline configurations. AWS Data Pipeline should be considered where full and incremental replication is a core requirement of the tool but comes at the cost of more manual setup and a far greater learning curve than AWS Glue.
Conclusion
This article introduced you to AWS Data Pipeline and AWS Glue and explained their key features. It also discussed the 5 key parameters that will help you conclude the AWS Data Pipeline vs. AWS GLue discussion. While both of these services can be used to assist with your organization’s ETL tasks, they are best suited for their specific use cases and applications, as outlined above. So it is imperative that you carefully consider each of these points before deciding the one that is right for your needs and organizational requirements.
Hevo is an all-in-one cloud-based ETL pipeline that helps you transfer data and transform it into an analysis-ready form. Its native integration with 150+ sources (including 50+ free sources) ensures you can move your data without writing complex ETL scripts.
Sign up for Hevo’s 14-day free trial and experience seamless data migration. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Is AWS Data Pipeline Obsolete?
Yes, AWS Data Pipeline is considered outdated, with AWS Glue now being the preferred service for ETL and data integration tasks.
2. What Is the Difference Between AWS and AWS Glue?
AWS: A broad cloud platform offering various services.
AWS Glue: A specific ETL service within AWS for data preparation, transformation, and integration.
3. Is AWS Glue Good for ETL?
Yes, AWS Glue is well-suited for ETL tasks, offering serverless data processing, scalability, and integration with other AWS services.




