

Have you ever opened the billing section of a BigQuery account and got a shocking surprise? You are not alone. BigQuery is a powerful tool, but this power does not come for free all the time. It can quickly deplete your budget if you do not practice good cost management. BigQuery is one of the most popular cloud data warehouses, allowing organizations to handle massive datasets efficiently. You can process enormous amounts of data in seconds, but it also comes with cost management. A company’s expenses may increase by 60% in just three months due to its rapidly expanding data and scaling needs in BigQuery. They did not optimize their storage or queries, which might have caused increased costs.
We will explore some practical strategies for BigQuery cost optimization. Whether you’re starting with BigQuery or have been using it for a while, these cost-saving strategies and best practices will help you maximize efficiency.
Table of Contents
What is BigQuery?

BigQuery is a powerful data warehouse that allows you to run SQL queries on massive datasets. It is a great solution for businesses that need to process large amounts of data for analytics and processing. You only need to worry about the data, not the infrastructure.
Key Features:
- Machine Learning: BigQuery ML allows users to train and run machine learning models in BigQuery using only SQL syntax.
- Serverless Architecture: BigQuery manages servers and storage in the background, so a user does not need to.
- High Scalability: It scales seamlessly to handle petabytes of data.
- SQL Compatibility: It supports ANSI SQL, which is useful for people who already know SQL and want to write and run queries. This also allows a user to combine various BI tools for data visualization.
Are you having trouble migrating your data into BigQuery? With our no-code platform and competitive pricing, Hevo makes the process seamless and cost-effective.
- Easy Integration: Connect and migrate data into BigQuery without any coding.
- Auto-Schema Mapping: Automatically map schemas to ensure smooth data transfer.
- In-Built Transformations: Transform your data on the fly with Hevo’s powerful transformation capabilities.
- 150+ Data Sources: Access data from over 150 sources, including 60+ free sources.
You can see it for yourselves by looking at our 2000+ happy customers, such as Doordash and Cure.Fit, and Pelago.
Get Started with Hevo for FreeBigQuery Pricing and Storage Model
BigQuery pricing can be divided into two main categories: storage and query costs. Google offers two pricing models for query costs:
- Storage
- Active storage
- Long-term storage
- Streaming inserts
- Query processing
- On-demand
- Flat-rate
Later, the query processing can be divided into two types:
- On-Demand Pricing
You pay $5 per terabyte of data processed by your queries. You pay as you query more data. This is ideal for users who run queries on an infrequent basis. - Flat-Rate Pricing
You pay a fixed price, starting at $2000 for 100 slots (a slot measures reserve query processing capacity) per month. Flat-rate pricing is great for businesses with consistent work and query loads, as it enables better cost control.
The initial 10GB of data storage per month is free for storage costs. When the 10 GB allowance finishes, users pay $0.02 per gigabyte for active storage (data modified within 90 days) and $0.01 per GB for long-term storage (data not modified within 90 days). This model is cheaper for storing historical data without affecting access speed. Data that has been modified within 90 days) and $0.01 per GB for long-term storage (data that has not been modified for 90 days). This model is cheaper for storing historical data without affecting access speed.
BigQuery Cost Optimization – Best Practices
Cost optimization for BigQuery includes managing storage, improving query efficiency, and selecting the right pricing model. A few key changes can minimize your BigQuery costs while maintaining performance and scalability.
1. Use Partitioned Tables for Time-Based Data
One of the easiest ways to reduce query costs is to use partitioning. When tables are partitioned, BigQuery only processes the data chunks relevant to the query.
For example, we have a dataset of user activity logs. We can partition the table by date, as log data can be massive. This will ensure that only the necessary date ranges are being scanned, not the entire table, significantly reducing the amount of data processed.
CREATE OR REPLACE TABLE `project.dataset.user_activity`
(
user_id STRING,
action STRING,
activity_time TIMESTAMP,
device STRING
)
PARTITION BY DATE(activity_time)There are two ways to implement this:
- We can use TIMESTAMP or DATE columns to partition your tables.
- We can also use WHERE clauses, which limit the data scanned by applying time/date conditions to the data.
| Pro tip: While creating or updating partitioned table, you can enable “Require partition filter” which will force users to include a WHERE clause that specifies the partition column, or else the query will result in error. |
2. Clustering for Faster Queries
Data clustering organizes data within each partition based on columns. It allows BigQuery to quickly find its needs without scanning the whole data. Clustering automatically sorts the data in each partition according to your chosen columns. For example, using the activity logs data, the column could be user ID, connection ID, or region. This increases efficiency as BigQuery can skip unnecessary rows. The result is faster query performance and lower costs since less data is scanned.
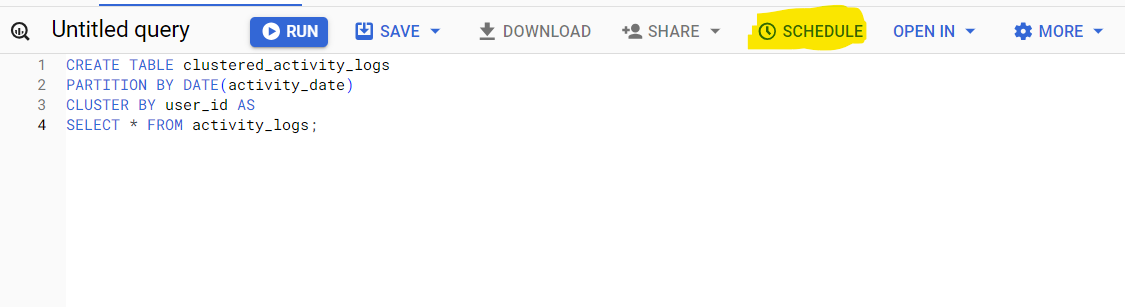
CREATE TABLE clustered_activity_logs
PARTITION BY DATE(activity_date)
CLUSTER BY user_id AS
SELECT * FROM activity_logs;There are two ways to implement this:
- We can choose the columns for clustering that align with your most queried data.
- We can use both clustering and partitioning to maximize efficiency.
| Pro tip: Clustering is allowed only on partitioned data. You can always use partitioning based on ingestion data, or introduce a fake date or timestamp column to enable clustering on your table. |
3. Avoid SELECT
Using ‘SELECT’ is one of users’ most common blunders when querying data. Users quickly query data by adding ‘SELECT from table’ to view or test out queries. However, they are unaware that using `SELECT` is one of the most common causes of high query costs. As it is apparent, it retrieves all the columns in a table, even if your analysis needs two or three. For example, activity_logs data usually have hundreds of irrelevant and insignificant columns that are not crucial for analysis. Using this SELECT, all of those columns will be retrieved. BigQuery charges based on the amount of data processed. Hence, you can reduce the data size scanned and thus lower your costs by choosing specific columns.
There are two ways to implement this:
- Specify the columns you need in your queries.
- Use the query optimization and analyzer tools to identify redundant columns.
4. Query Scheduling and Caching
There is a section called Scheduled Queries in BigQuery. If your queries need to run on a schedule, leverage BigQuery’s query scheduling feature to ensure the same query is not running repeatedly. Scheduled queries automate repetitive jobs while ensuring they are running efficiently. BigQuery caching feature automatically stores query results temporarily. BigQuery retrieves the same results from the cache at zero cost if the query is repeated within 24 hours and data remains the same.
There are two ways to implement this:
- Use the scheduled queries feature. Create a schedule that meets your needs.
- Take use of cached results by ensuring that searches are structured consistently across datasets.
5. Leverage Flat-Rate Pricing for Known Workloads
The flat-rate pricing model might be a good option for you if you have a consistent and heavy workload. The on-demand pricing model charges per TB of data processed, but flat-rate pricing gives you a set of processing slots for a fixed price, starting at $2000 for 100 slots. This option will save you a lot of costs.
There are two ways to implement this:
- Check your workloads to see if your usage pattern is consistent enough to benefit from flat-rate pricing.
- Utilize the BigQuery cost calculator to estimate the costs based on your usage. You can then forecast your potential savings.
6. Data Deduplication and Compression
Redundant data is unnecessary and inefficient. It only increases both the storage and query costs. Hence, it is necessary to use data deduplication techniques to reduce the amount of storage used. There are also other ways, such as using other data compression formats, such as Avro and Parquet, to compress your data further. It can minimize storage costs without compromising access speed.
There are two ways to implement this:
- Data transformation techniques are used in the ETL process to regularly clean and remove duplicate records.
- Consider using other compressed data formats to reduce the amount of data scanned.
7. Use the BigQuery Data Transfer Service
Google provides a service known as the BigQuery Data Transfer Service. It automates data import from external sources like Google Analytics, Google Ads, YouTube, and SaaS apps. The service easily connects with these external applications and saves time ingesting data. Manually loading data is inefficient, of course! Automating these processes ensures the data is transferred efficiently, reducing the probability of loading excessive or redundant data.
There are two ways to implement this:
- Set up automatic transfers for the external data sources you use frequently.
- Monitor and manage these transfers to avoid unnecessary data loads.
8. Set Billing Alerts
Cloud Billing Alerts help you regulate your costs and alert you when they exceed a certain threshold. You can set an alert to notify you when the current month’s costs exceed the previous month’s costs. It is essential to have visibility on your BigQuery usage to avoid unexpected costs. As a result, you can quickly optimize your queries if needed.
There are two ways to implement this:
- Setting up Cloud Billing Budgets and Alerts in Google Cloud Console.
- Monitor your usage with BigQuery Cost Control reports regularly.
9. Keep your data only as long as you need it.
Data stored in BigQuery’s Capacitor columnar data format is already encrypted and compressed by default. Configure default table expiration on your dataset for temporary staging data that you don’t need to preserve.
In BigQuery, data stored in its Capacitor columnar format is encrypted and compressed by default. Set default table expiration on your dataset for temporary staging data that you would not like to retain any longer.
10. Set up controls for accidental human errors.
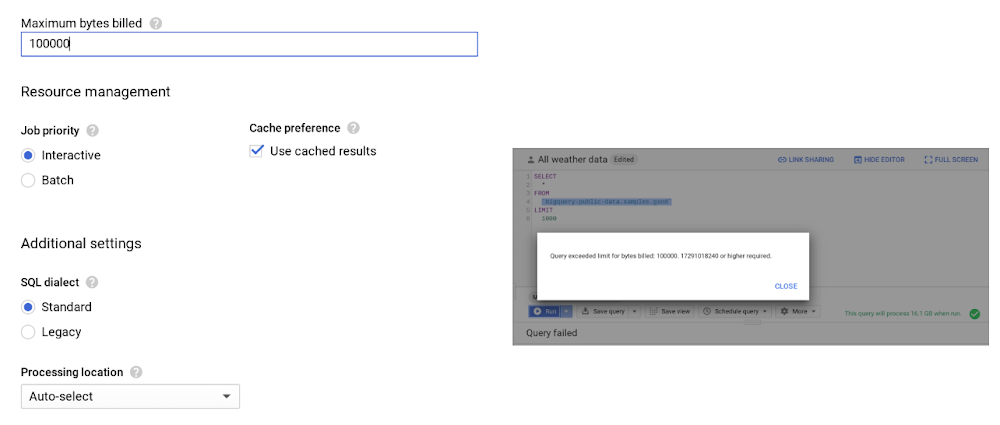
Usually, a query is about the magnitude of GB, a mishap that can cost you a few cents, which is acceptable for most businesses. However, when you have dataset tables that are in the magnitude of TBs or PBs and are accessed by multiple individuals, unknowingly querying all columns could result in a substantial query cost.
In this case, use the maximum bytes billed setting to limit query cost. Going above the limit will cause the query to fail without incurring the cost of the query, as shown below.
Are there any Free BigQuery Operations?
Yes, there are a couple of free operations in BigQuery that you can utilize for your benefit:
- 10 GB Free Storage
As discussed, BigQuery gives all users a free allowance of 10 GB of data each month. This allows any user to learn and explore BigQuery without any cost stress. You can test out queries by uploading data and learning the features. Furthermore, data is moved to long-term storage after 90 days, billed at $0.01 per GB compared to $0.02 for active storage.
- Free Query Execution
BigQuery provides 1TB of free data processing per month! This is a perfect deal for startups with small-scale businesses. You can also experiment if you are working on small-scale datasets and playing with the platform. You can also perform your analytics within the free tier.
- Free Manual Data Loading and Exporting
BigQuery does not charge for manual data loading or exporting using CSV files or other formats. Hence, you can move data into or out of BigQuery at no cost. This is super great if you want to archive or migrate data to BigQuery for quick analytics.
- Free Metadata Queries
You can retrieve metadata using queries free of cost, such as information about schemas or checking the size of datasets.
Why BigQuery Cost Optimization?
- Scalability
Data volumes will grow, and if you do not optimize costs, costs will grow as well. Applying cost optimization will ensure that you can manage increased data without costs going out of control. - Predictability
BigQuery provides cost forecasting and estimation tools that help you create budgets and allocate necessary resources. This is very important for small businesses with tight budgets or limited resources. - Resource Efficiency
BigQuery allows you to pay as you use it. You ensure that you only pay for the resources that you actually use. You avoid over-allocating resources that may unnecessarily increase costs. - Maximize Return On Investment
Cost optimization increases return on investment in data analytics. You should maximize the value you can take from BigQuery when using its capabilities while controlling costs. Optimizing costs ensures a better return on investment (ROI) in data analytics.


Conclusion
BigQuery is a powerful and flexible data warehouse, but it requires careful management to control costs and avoid unnecessary expenses.
By leveraging strategies and best practices as discussed in this blog, which include but are not limited to partitioning, clustering, and query optimization, you can significantly reduce query and storage expenses. We should take advantage of the free operations that BigQuery provides to our best and use the billing and budgeting tools to stay within the budget while maintaining performance. BigQuery Cost optimization maximizes return on investment and enables you to scale your data analytics solutions in BigQuery. Now, you are on track to leverage BigQuery fully.
To optimize the total cost of ownership while using BigQuery, sign up for Hevo’s 14-day free trial and experience seamless data migration within budget.
Frequently Asked Questions
How does BigQuery achieve cost-effectiveness for query processing?
BigQuery uses a columnar storage format. It processes queries in parallel across distributed systems. This feature allows BigQuery to scan only the necessary columns and process large datasets.
What are the two pricing models for BigQuery query costs?
BigQuery has only two pricing models: on-demand pricing, which charges per terabyte of data processed, and flat-rate pricing, which charges a fixed monthly fee for slots.
How do you optimize cost per order?
It involves minimizing the data scanned in queries. To limit the amount of data processed, you can use data partitioning and clustering. You can also select the right pricing model based on your organizational workload and needs.
How do you optimize the cost?
Reduce unnecessary queries and clean redundant data processing. You can also leverage cached results, schedule queries, and ensure that queries are designed to scan only relevant data.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





