




A virtual table that is defined by a SQL query is known as a BigQuery View. The presented views have a logical view rather than a materialized one, and it is because of this factor that every time a view is queried, the query that defines the view is run each time.
In other words, an entirely handled and managed warehouse of enterprise data that helps one analyze and manage one’s data with the assistance of built-in features such as business intelligence, geospatial analysis, and machine learning.
Table of Contents
What is Google BigQuery?

Google BigQuery is a big data analytics web service that is cloud-based and is used for the processing of very large read-only data sets. The basic purpose with which BigQuery was designed was for the analyzing of data on the order of billions of rows, with the use of syntax like SOL.
It is mainly run on the Google Cloud Storage Infrastructure. They can be accessed by a REST-oriented application program interface (API).
BigQuery was released as V2 in 2011. Google profoundly calls it an ‘externalized version’ of its very own Dremel query service which is its home-brewed software.
Both of these software accommodate columnar storage for efficient data scanning and a tree architecture for the dispatch of queries and generating results across huge computer ranges.
Key Features of Google BigQuery
In a simpler aspect, BigQuery is a serverless data warehouse that is fully managed and it enables scalable analysis than petabytes of data. Its service is to provide support for querying using ANSI SQL.
- Serverless Service: Generally in a Data Warehouse environment, organizations need to commit and specify the server hardware on which computations will run. Administrators then have to provision for performance, reliability, elasticity, and security. A Serverless Model helps overcome this constraint. In a Serverless Model, the processing is automatically distributed across a large number of machines working in parallel. By using Google BigQuery’s Serverless model, Database Administrators and Data Engineers focus less on infrastructure and more on provisioning servers. This allows them to gain more valuable insights from data.
- SQL and Programming Language Support: Users can access Google BigQuery through Standard SQL. Apart from this, Google BigQuery also has client libraries for writing applications that access data using Python, C#, Java, PHP, Node.js, Ruby and Go.
- Multiple Data Types: Google BigQuery offers support for a vast array of data types including strings, numeric, boolean, struct, array, and a few more.
- Security: Data in Google BigQuery is automatically encrypted either in transit or at rest. Google BigQuery can also isolate jobs and handle security for multi-tenant activity. Since Google BigQuery is integrated with other GCP products’ security features, organizations can take a holistic view of Data Security. It also allows users to share datasets using Google Cloud Identity and Access Management (IAM). Administrators can establish permissions for individuals and groups to access tables, views, and datasets.
What are Table Views?
As the name suggests, a BigQuery table view serves the information in rows and columns like that of a table which makes it pretty easy for the viewer to access and understand the respective data.
The columns where data is composed are also known as fields. The tables are categorized according to the schema that describes the column names, data types, and various other information.
What are the Key Aspects of BigQuery Views?
BigQuery is typically used to justify the purpose of dealing with several database accounts, analytical readings, and/ or processed data. The views are read-only sets of data or where humans are required to perform tasks related to interactive ad-hoc queries. The language instilled which is used is Structured Query Language.
Some additional querying features of BigQuery can be illustrated as follows:
What are the Limitations of BigQuery Views?
Every day-to-day task is made easy with today’s technology but it is to be remembered that the technology can only prove to be a helping hand thus it comes with its limitations. BigQuery Views also have the same with regards to the response size, row size, etc. A more detailed analysis is presented below:
- Read-only views: The dataset views could only be read and not edited in the long – run. The files could be shared only for revising purposes and not that of modifications. The DML (delete, insert, update) queries could not be run against a view.
- Same location: Both the datasets that are, one with the views and the other one with the tables referenced by the views have to be in the same location.
- Response size: The maximum response size is set to 10GB compressed, and could not be updated further.
- Row size: The maximum row size is set 100MB and this too could not be altered in the long run.
These are to be kept in mind while working with views.
How to use the BigQuery Create View Command?
Here are the steps involved in setting up a BigQuery Create View:
BigQuery Create View Setup: Using the BigQuery Console
- Step 1: After running the query, click the save view option from the query results menu to save the query as a view.
- Step 2: In the Save View dialogue:
- While choosing the “Project Name”, select a project to store the view.
- In “Dataset Name”, select a dataset to store the view.
- Finally, for “Table Name”, mention the name of the view.
- Click on “Save”.
BigQuery Create View Setup: Using SQL
Choose the ‘Create view’ command to create a new view. The SQL statement could be run in the Cloud Console. On the BigQuery page, put the statement in the query editor.
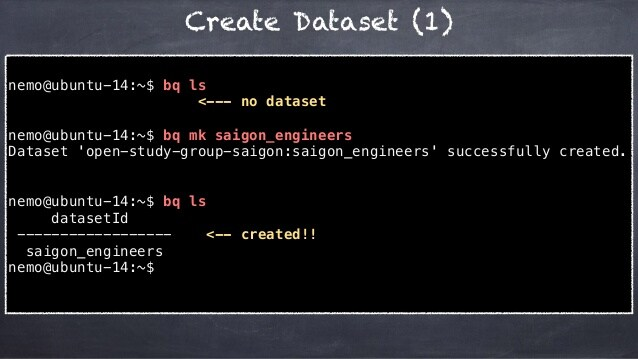
BigQuery Create View Setup: Using the BQ Command
You can also use the bq command-line tool’s bq mk command, to create your view in BigQuery. This can be seen in the following instance:
BigQuery Create View Setup: Using the API
If you want to use the API method for creating a BigQuery view, the tables.insert API method can be called to make the initiation.
Automate Your Google BigQuery Data Pipelines:
BigQuery Create View: How to Name a View?
A name describes the purpose of a certain thing. Therefore, it is very important to name the view accordingly as its name would suggest the unique dataset it contains. Some technicalities to be kept in mind while naming the view are:
- The name can contain up to 1,024 characters.
- The name can accommodate Unicode characters in category M (mark), L (letter), Zs (space), Pd (dash), N (number), Pc (connector, including underscore).
BigQuery Create View: How to Secure a View?
To configure access to the views, one may grant an IAM role to an entity at the below-presented levels:
- A high level in the Google Cloud Resource Hierarchy.
- The dataset level.
- The table/ view level.
Access to data can also be restricted within the tables using the following methods:
- Column – level security
- Row-level security.
How to Manage a BigQuery Create View
A) Renaming a View
The name of a pre-existing view cannot be changed, but what could be done is that you can recreate the view altogether with the new name.
B) Copying a View
The bq command-line tool cannot be used to copy a view. Instead, you must recreate the view in the target dataset. The easiest way to do this is to copy the SQL query used to define the view. You can utilize the format flag to control the output as shown below:
bq mk
--use_legacy_sql=false
--view_udf_resource=PATH_TO_FILE
--expiration INTEGER
--description "DESCRIPTION"
--label KEY:VALUE
--view 'QUERY'
--project_id PROJECT_ID
DATASET.VIEWFrom the illustration above:
- PROJECT_ID is your project’s ID.
- DATASET is the dataset’s name.
- VIE is the view’s name.
- PATH_TO_FILE is the output path in your local machine.
- INTEGER specifies the view’s lifetime (in seconds).
- DESCRIPTION is a quote-based description of the viewpoint.
- The key-value pair KEY: VALUE represents a label.
- QUERY is an appropriate query.
C) Deleting a View
Go to the BigQuery page and enter the statement to the query editor. Now, use the bq rm command with the table flag to delete a view. After doing so, you must not forget to confirm the action. Below is the code for the same:

Where
- -f is the force flag used to skip the confirmation
- -t is the table flag used to delete a view
Examples of BigQuery Views
Below, you will find three different types of Bigquery View Syntaxes. The first one is the base syntax and is quite straightforward as outlined below:

The second uses the Joins Syntax to create a view in BigQuery.

The last one, Materialized Views, is way more efficient and is precomputed to cache query results for increased performance and efficiency. Below is the syntax:

Now, let us see a View in action. Below is a real-world example of a View code syntax in BigQuery:
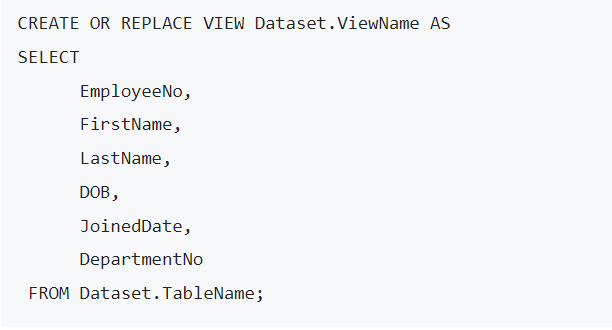
The view in the above scenario is named view_name and must be unique per dataset. From the example, some of the attributes in the view include Employee Number, First and Last name, Date of Birth, and more. Finally, below are some of the view’s features:
- It contains up to 1,024 features.
- It contains either letters, numbers, or underscores
Conclusion
The provided methods, hacks, and techniques are not just for beginners but can also guide an expert through his way. BigQuery Views are handy and skeptical at the same time. These views, in a logical manner, help organize and study the datasets.
FAQ on BigQuery Create View Command
Can you create views in BigQuery?
Yes, you can create views in BigQuery. Views in BigQuery are virtual tables that represent the result of a SQL query. They do not store data themselves but instead store the query that retrieves it.
How do I create an Authorized view in BigQuery?
To create an authorized view, you need to define an SQL query that filters data based on user permissions and then create a view using the CREATE VIEW statement. Ensure users have appropriate IAM roles while doing this.
What is the difference between a view and a query?
A view is a stored virtual table that persists in the database and encapsulates query logic for reuse. In contrast, a query is an immediate SQL statement used to fetch data at a specific instance without persistence.
How to check view in BigQuery?
You can check for existing views in a dataset using the BigQuery Console UI or by querying the INFORMATION_SCHEMA views.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link


