



Analysing data stored in On-premise Data Storage units can be a slow and time-consuming task, especially when your data is generating at an exponential rate and requires constant scaling to boost performance.
This is one of the major reasons why growing businesses are gradually adopting Cloud-Based Data Warehousing solutions. One such brilliant example is Google BigQuery which is a serverless Data Warehouse providing on-demand scaling to optimally handle your growing data and analytics needs.
Google BigQuery is a Cloud Data Warehouse and Analytics Platform which can assign the required optimal compute resources for all types of varying workloads allowing business teams to create reports in real-time. You can further minimize the query time by using the BigQuery Partition Tables feature.
Table of Contents
What is BigQuery?

Launched in 2010, BigQuery is a Cloud-Based Data Warehouse service offered by Google. It is built to handle petabytes of data and can automatically scale as your business flourishes. Developers at Google have designed its architecture to keep the storage and computing resources separate.
This makes querying more fluid as you can scale them independently without sacrificing performance. Since there is no physical infrastructure present similar to the conventional server rooms for you to manage and maintain, you can focus all your workforce and effort on important business goals.
Using standard SQL, you can accurately analyse your data and execute complex queries from multiple users simultaneously.
Key Features of BigQuery
Google BigQuery has continuously evolved over the years and is offering some of the most intuitive features :
- User Friendly: With just a few clicks, you can start storing and analysing your data in Big Query. An easy-to-understand interface with simple instructions at every step allows you to set up your cloud data warehouse quickly as you don’t need to deploy clusters, set your storage size, or compression and encryption settings.
- On-Demand Storage Scaling: With ever-growing data needs, you can be rest assured that it will scale automatically when required. Based on Colossus (Google Global Storage System), it stores data in a columnar format with the ability to directly work on the compressed data without decompressing the files on the go.
- Real-Time Analytics: Stay updated with real-time data transfer and accelerated analytics as BigQuery optimally allots any number of resources to provide the best performance and provide results so that you can generate business reports when requested.
What are Partitioned Tables?
BigQuery Partition Tables are the special tables that are divided into segments called partitions making it easier for users to manage and query data. It divides large tables into smaller tables to improve query speed, and Performace, and control the costs by reducing the number of bytes read by the query.
Users can perform BigQuery partition on tables by:
- Ingestion Time
- Integer Range
- Time-Unit Column
What is BigQuery Partition?
Previously, database administrators leveraging Google BigQuery used to split large datasets into smaller tables that were demarcated by time and/or date. For instance, each day a table may be generated where the table name is suffixed with the current date (for instance, books_20211230, books_2021229, etc.).
Despite this method being functional, it used to create a lot of headaches to not only manage all these split tables but queries quickly become quite complex since the potential date ranges crossover and increase. To tackle this problem head-on, Google BigQuery introduced the partitioned table. This table resembles a normal table, except that it is automatically partitioned for every date.
You can use BigQuery partitions to manage and query your data with the best possible performance. It also allows you to gain better control over the costs associated with the use of Google BigQuery. Google BigQuery Partition can help you automatically create smaller chunks of a single table on the basis of specific criteria. For instance, every day, Google BigQuery can create a new table containing the data only for that particular day.
How does BigQuery Partition Work?
When you try to execute a query requesting data for a particular date, Google BigQuery can read only a specific table or a small set of them instead of the entire database. This has two primary benefits, involving pricing and performance.
In terms of performance, the system can now read smaller tables much more quickly, therefore, even complex queries can become much more efficient during execution. As far as pricing goes, Google BigQuery’s pricing model is based on the size of the query and data transfers.
Prerequisites
- An active BigQuery Account.
3 Critical Aspects of BigQuery Partition Feature

BigQuery Partition Feature can be quite advantageous in terms of enhancing query performance. BigQuery Partition can divide your datasets into different sections based on a field or column which ultimately helps you optimize your query speed and reduce costs for the number of bytes read per query.
To understand how to use the BigQuery Partition feature for your datasets, the following 3 Aspects are critical :
1) Create BigQuery Partitioned Tables
To create BigQuery Partitioned Tables, you need to have the following administrative permissions:
- bigquery.tables.create permissions for building the table.
- bigquery.tables.updateData for writing your data to the table by performing a load job, a query job, or a copy job.
- bigquery.jobs.create for executing a query job, load job, or copy job to write data to your table.
There 3 types of BigQuery Partition Tables that you can create:
- Time-unit column: Tables are divided based on a TIMESTAMP, DATE, or DATETIME column in the table. You can use a time-unit column field to write and read information from the partitioned tables based on these fields. For instance, if you want to write a new record, Google BigQuery will automatically search for the data and write the data into the correct partition based on the time-unit column. Based on the aforementioned column fields, Google BigQuery can apply different granularities. This provides you with more flexibility over the partitions.
- Ingestion time: Tables are partitioned based on the timestamp when the data is uploaded on the BigQuery server. The partitioning takes place in a way resembling the time-unit column partitioning.
You can choose between daily, hourly, monthly, and yearly granularity for the partitions. To execute the queries, Google BigQuery creates two pseudo columns called _PARTITIONTIME and _PARTITIONDATE. BigQuery stores the ingestion time for each row here, truncated by the granularity of your choice. - Integer range: Tables are separated based on an integer column. To create an integer-range partition table in Google BigQuery, you need to provide four arguments: the integer-type column name, the starting, and ending value for range partitioning, and the interval between the ending and starting values.
Based on these arguments, Google BigQuery will create a set of partitions. This means the values in the integer-type column name in column 1 will be split into ranges of intervals as mentioned in column 4.
For creating Bigquery Partition Tables, you can use Google Console, bq commands, SQL, API, or client libraries such as Python, Go, Node.js and Java.
To build BigQuery Partition Tables using Google Console, follow these simple steps:
- Step 1: Open the BigQuery Page on your browser.
- Step 2: Navigate to the Explorer Panel and click on the desired dataset from your project.
- Step 3: Click on the Actions option and select Open.
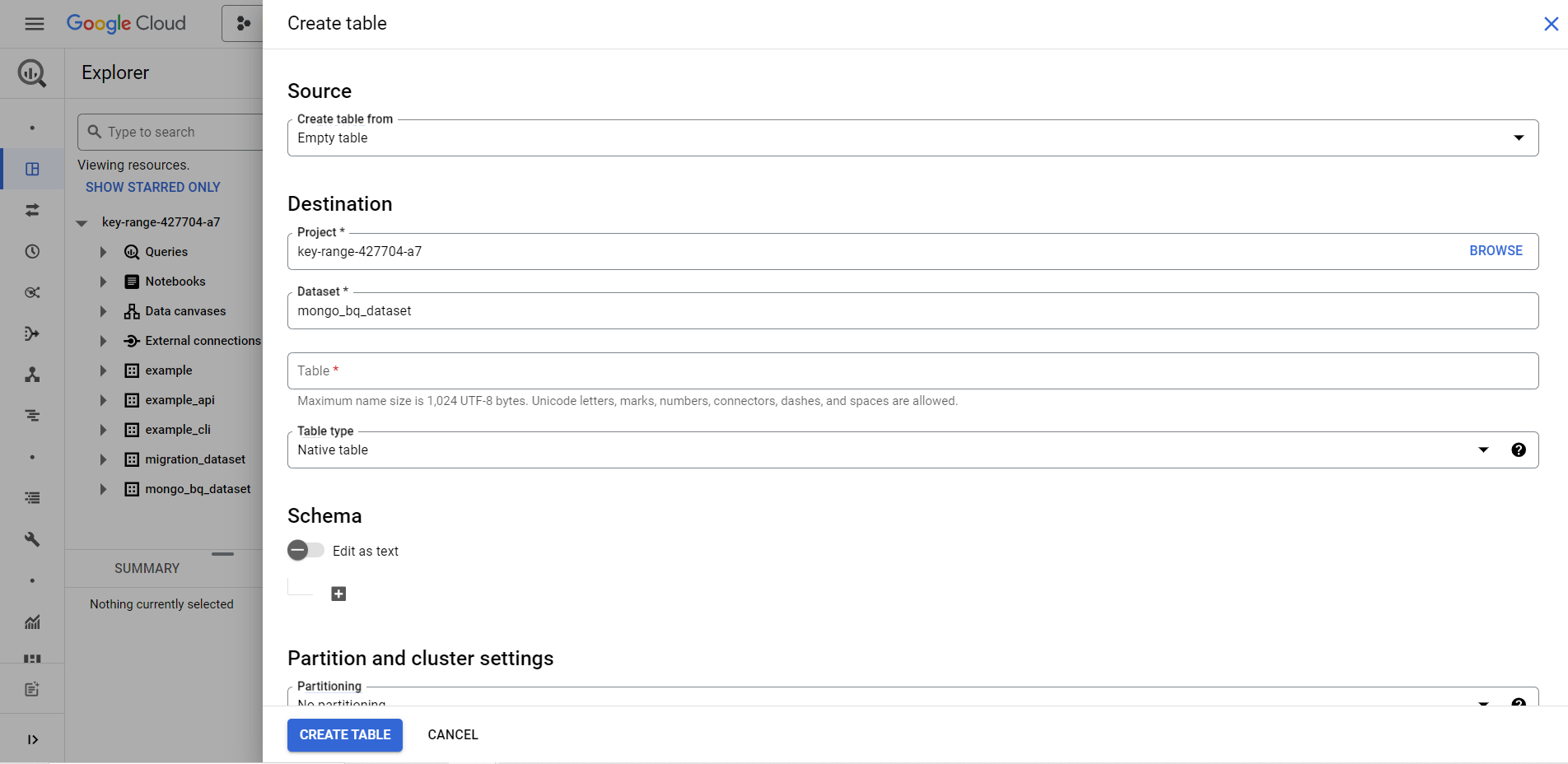
- Step 4: From the details panel, click on the Create Table option and a new Create Table Page will appear on your screen.
- Step 5: Check the Empty Table option in the Source section.
- Step 6: In the Destination section, fill in the Table name and select the desired dataset from the drop-down menu. Ensure that the Table type is set to Native table.
- Step 7: Enter the schema Definition in the Schema field, for example, for the time-unit column partition you can enter TIMESTAMP, DATE, or DATETIME.
- Step 8: From the drop-down menu, select the daily, hourly, monthly, or yearly partitioning.
- Step 9: Finally, hit the Create Table button.
If you are familiar with the SQL environment, then the example given below can be used as a reference for partitioning your table. In this example, arrival_date is used as a time-unit column for partitioning.
CREATE TABLE
mydataset.newtable (passenger_id INT64, arrival_date DATE)
PARTITION BY
arrival_date
OPTIONS(
partition_expiration_days=3,
require_partition_filter=true
)Bigquery provides bq commands to execute various jobs easily. In the example given below, tableone is partitioned based on arrival_time on an hourly basis with an expiration date of 3 days(259200 seconds).
bq mk --table
--schema 'ts:TIMESTAMP,qtr:STRING,sales:FLOAT'
--time_partitioning_field arrival_time
--time_partitioning_type HOUR
--time_partitioning_expiration 259200
datasetone.tableoneFor information on how to create BigQuery Partition Tables using API and via Client Libraries, you can visit the Creating BigQuery Partitioned Tables Page.
2) Manage BigQuery Partitioned Tables
Once you have to build your BigQuery Partition Tables, you can also update the partition expiration time, delete a partition, copy an individual partition, or even the complete partitioned table. Let’s see these various functionalities in detail:
- Firstly, to access metadata and the list of all the partitions of your dataset, you use the INFORMATION_SCHEMA.PARTITIONS standard SQL view:
SELECT table_name, partition_id, total_rows
FROM `datasetone.INFORMATION_SCHEMA.PARTITIONS`
WHERE partition_id IS NOT NULL- The partition expiration time is set during the creation of tables. This is important as it automatically deletes the data which you don’t require after a certain time that in turn reduces query costs. To update the partition expiration time at a later stage, follow these simple steps:

- Step 1: On the BigQuery Page, click on the Query option.
- Step 2: Use the code given below in the text editor to set the expiration time as 5 days and Click Run (You can also set Partion_expiration_days as NULL to remove it).
ALTER TABLE datasetone.tableone
SET OPTIONS (
partition_expiration_days=5
)- Copying an Individual Partition is also possible by using the bq cp command or via API. You can follow the syntax below to copy a partition to your desired destination.
bq --location=location cp
-a
project_id:dataset.source_table$source_partition
project_id:dataset.destination_table$destination_partitionTo understand its use, the example given below shows that data is copied from the March 25, 2021 partition from the dataset “datasetone.tableone” to a new table i.e. “datasetone.tabletwo“.
For more information on copying the partitions, click here.
- You can also delete a partition permanently using bq rm command or via API. The following syntax can be used as a reference when deleting a partition through bq commands:
Keeping the above syntax, the following example deletes a partition for August 1, 2021 from the table “tableone” of the dataset “datasetone“.
3) Query the BigQuery Partitioned Tables
To query a partitioned table you must ensure the following access permissions:
- bigquery.tables.getData to query a table.
- Bigquery.jobs.create to run a query.
For tables partitioned based on Ingestion time, two pseudo columns are added by default, namely:
- _PARTITIONTIME : Contains the timestamp of when the data is appended to the table.
- _PARTITIONDATE : Contains the data according to the timestamp in _PARTITIONTIME.
The following example reads the partitions of the dataset “datasetone” from the table “tableone” which were created between the dates August 1, 2021 and August 15, 2021.
SELECT *
FROM
datasetone.tableone
WHERE _PARTITIONDATE BETWEEN '2021-08-01' AND '2021-08-15'While using a comparison operator such as “>”, keeping the _PARTITIONTIME column on the left side of the operator can improve the query performance. You can easily understand its application in the code given below:
SELECT *
FROM datasetone.tableone
WHERE
_PARTITIONTIME > TIMESTAMP_SUB(TIMESTAMP('2016-04-15'), INTERVAL 5 DAY)Partitioning versus Clustering
Partitioning and Clustering are used to increase the performance and reduce the query cost.
You can use BigQuery Partition for the following scenarios listed below:
- When you want to know the query cost before running the query. BigQuery Partition pruning is performed to get the query cost by the dry run.
- You need BigQuery Partition level management.
- You want to describe how data is partitioned what data is present in each of the BigQuery Partition.
You can use Clustering under the following circumstances listed below:
- The queries that you want to execute mostly use filters and aggregation.
- The cardinality of the number of values in a column or group of columns is large.
- When you don’t require strict costs information before running queries.
Partitioning versus Sharding
Sharding is the process of storing data in multiple tables with the name prefix such as [PREFIX]_YYYYMMDD.
While Partitioning is preferred over table Sharding because these tables perform better. BigQuery has to maintain the copy of the schema and metadata when using sharded tables and also needs to verify the permissions.
Loading Data in a Partitioned Table
Loading data into BigQuery Partition Table is similar to loading other tables. For this example, sample data is used from bigquery-public-data:samples.github_timeline dataset. The sample query to load data is given below:
SELECT
repository_name,
repository_language,
repository_size,
repository_watchers,
created_at
FROM
[bigquery-public-data:samples.github_timeline]
WHERE
created_at IS NOT NULL
ORDER BY
created_at ASC
LIMIT
1000This will give the following output given below:
[
{
"repository_name": "node-orm",
"repository_language": "JavaScript",
"repository_size": "208",
"repository_watchers": "101",
"created_at": "2012-03-11 06:36:13"
},
{
"repository_name": "nimbus",
"repository_language": "Objective-C",
"repository_size": "18304",
"repository_watchers": "1259",
"created_at": "2012-03-11 06:36:13"
},
{
"repository_name": "impress.js",
"repository_language": "JavaScript",
"repository_size": "388",
"repository_watchers": "7149",
"created_at": "2012-03-11 06:36:13"
},
...
]BigQuery Partitioned Tables Pricing
Google BigQuery partitioned tables come at no additional cost. Similar to the standard tables, you can make and leverage partitioned tables in Google BigQuery and your charges will be based on the data stored in the BigQuery partitions and the queries you run against those tables.
You can use Google BigQuery partitions to minimize the costs since you can limit the bytes retrieved by a query and optimize the related costs at the same time.
Limitations of BigQuery Partitioned Tables
BigQuery Partitions also come with a couple of limitations. As mentioned earlier, Google BigQuery does not provide you with the ability to partition a table using multiple columns (or through non-integer/ non-time columns).
Apart from this, partitioned tables can only be availed through Standard SQL dialect. This means that legacy SQL cannot be leveraged to write or query results to them. On a final note, the integer-range BigQuery partition table comes with the following limitations:
- The partitioning column needs to be a top-level field since you cannot partition over nested fields such as Arrays or records.
- The partitioning column needs to be an integer column. This column can afford to have null values.
How can you Query an Externally Partitioned Table in BigQuery?
Google BigQuery provides support for querying ORC, Avro, Parquet, CSV, and JSON partitioned data that are hosted on Google Cloud Storage by leveraging a default Hive partitioning layout. The directory structure of a Hive partitioned table is assumed to have the same partitioning keys that appear in the same order, with an upper limit of ten partition keys per table.
To load a new partitioned table on the basis of external partitioned files, you can follow along with the steps mentioned below:
- Step 1: Open up the Google BigQuery Console.
- Step 2: Select your dataset where the Google BigQuery table should be created.
- Step 3: Next, click on “Create a Table” and choose Cloud Storage.
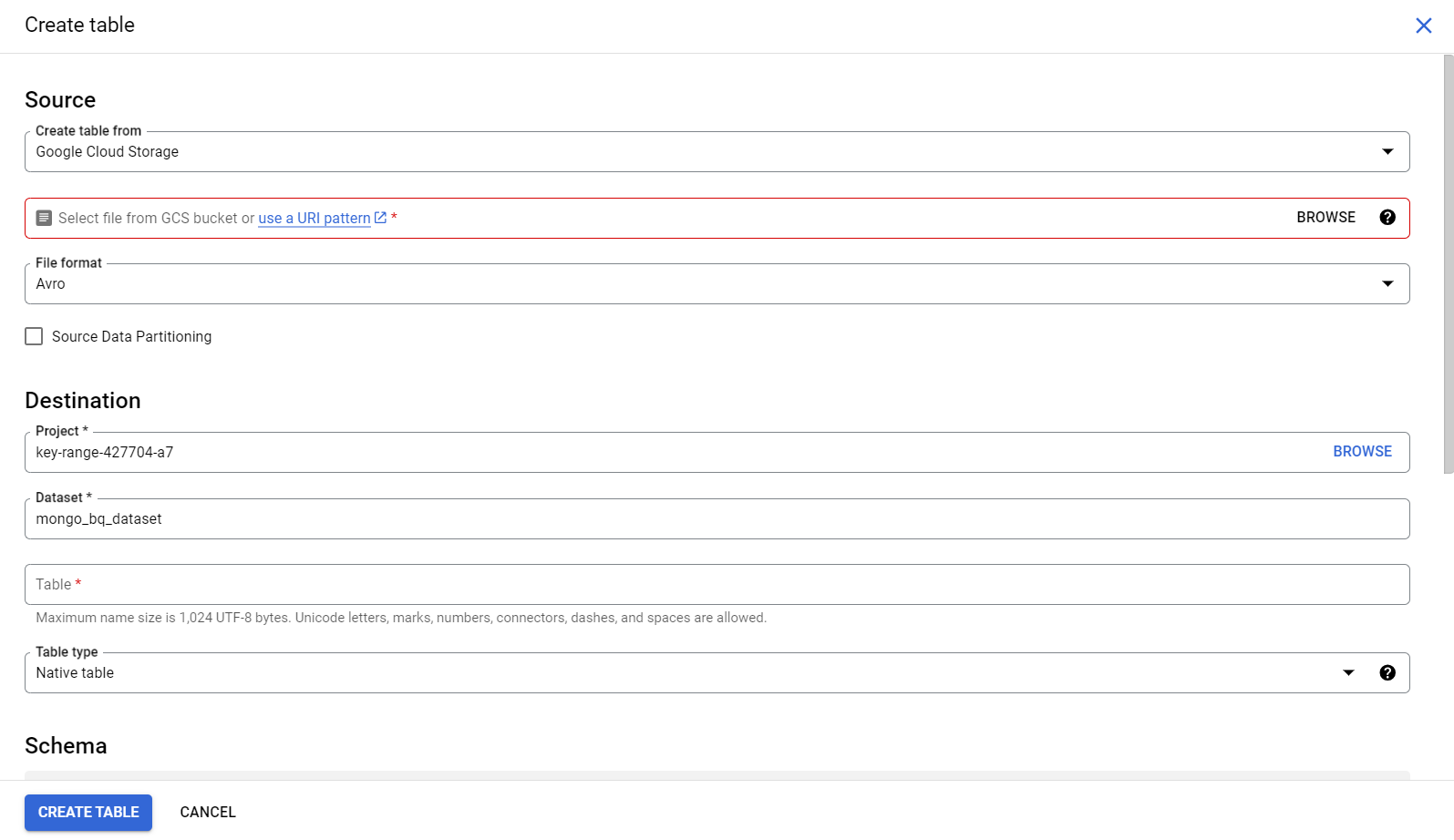
- Step 4: Provide the path to the Cloud Storage folder by leveraging the Wildcard format. For instance, test_bucket_hevo/my_files.
- Step 5: Next, select the Source data partitioning checkbox.
- Step 6: Provide the Cloud Storage URI prefix (for instance, gs://test_bucket_hevo/my_files.)
- Step 7: You can leave the partition inference mode as Automatically Infer types.
- Step 8: Finally, click on the “Create Table” button to complete the process of querying an external BigQuery Partition Table.
BigQuery Partition – Should We use it?
BigQuery Partition is a great tool that comes in handy to accomplish partitioning work. Partitioning is a good practice to follow over table sharding because the partitioned tables perform better. Feel free to explore more on BigQuery Partitioning.
Conclusion
In this article, you have learned how to use the BigQuery Partition Feature to your advantage. BigQuery Partition feature is an elegant tool to optimize your query performance and also reduces storage costs.
BigQuery offers various ways to create a table such as Google Cloud Console, API, SQL, and programming environments like Java, Python, Node.js, etc. The standard SQL being the most popular among data analysts, helps them to comfortably manage and query their data from the BigQuery Partition Tables.
As your business grows, the data associated with your customers, products, and services are generated at an astonishing rate. BigQuery’s scalability and best-in-class performance help in handling all types of varying workloads.

Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





