




When working with BigQuery, performing complex data operations like UPSERTs (Update + Insert) can be challenging. While BigQuery doesn’t support a direct UPSERT command, the MERGE statement offers a powerful alternative to achieve the same result—and much more. In this article, explore how MERGE and EXECUTE IMMEDIATE statements can be used to perform efficient data manipulations, handle dynamic SQL scripts, and simplify your workflows in BigQuery. Get ready to unlock new ways to manage your data effortlessly!
In this article, you will cover 2 statements from the BigQuery SQL syntax:
- MERGE, which is a DML (data manipulation language) statement, on par with INSERT, UPDATE, etc. (Will be used for BigQuery UPSERT)
- EXECUTE IMMEDIATE, which is a scripting statement, on par with DECLARE, CASE, IF, etc.
Table of Contents
Overview of Google BigQuery

- Google BigQuery is a prominent Data Warehouse solution. A Data Warehouse is used for OLAP (Online Analytical Processing) tasks, unlike a Database, which is used for OLTP (Online Transactional Processing) tasks.
- However, both Databases and Data Warehouses generally support SQL for querying data. The internal implementation of our queries is, of course, different since BigQuery organizes data in columns instead of rows to enable Parallel Processing.
- However, as the end-users, we need not worry about the implementation. If you are familiar with SQL operations on a database, then you should feel at home with BigQuery SQL.
Prerequisites
- In order to try out the code snippets presented in this article yourself, you should have a Google Cloud account with billing enabled. The MERGE query, being a DML query, is not allowed in the free Google BigQuery Sandbox.
- All the examples within this article will be covered within the $300 worth of free credits you get when signing up for Google Cloud; thus, you won’t incur any charges. However, you will need to add credit/debit card information.
- If you do not have a billing-enabled Google Cloud account, you should still be able to understand this article if you are familiar with SQL.
Hevo Data, a No-code Data Pipeline, helps load data from any source, such as Databases, SaaS applications, Cloud Storage, SDKs, and Streaming Services, and simplifies the ETL process. It supports 150+ Data Sources, including 60+ Free Sources. The process is three-step: selecting the data source, providing valid credentials, and choosing the destination.
Hevo loads the data onto the desired Data Warehouse, such as Google BigQuery, in real-time, enriches the data, and transforms it into an analysis-ready form without having to write a single line of code.
Check out why Hevo is the Best for you:
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled securely and consistently with zero data loss.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Simplify your BigQuery ETL & Data Analysis with Hevo today!
SIGN UP HERE FOR A 14-DAY FREE TRIAL!Working with BigQuery UPSERT using MERGE
- As mentioned earlier, BigQuery UPSERT means UPDATE+INSERT. It is essentially INSERT that behaves like an UPDATE in case of duplicates, so as to not violate any uniqueness constraints. In other words, if you have a target table T into which you want to insert entries from source table S, maintaining the uniqueness of column PK, then the following will happen:
- If a row of S does not have a matching PK value in T, it will get added to T (INSERT)
- If a row of S has a matching PK value in T, the corresponding row of T will get replaced by the row of S (UPDATE)
- Of course, the uniqueness constraint can be different, and not restricted to a single column. The illustration above was a broad simplification of how BigQuery UPSERT will work to make the concept clear.
- What does MERGE do? It generalizes the idea of performing different actions in the case of MATCHED and NOT MATCHED values. Apart from INSERT and UPDATE, it also allows you to DELETE. Furthermore, it allows you to even take conditional actions, like for rows that are in the NOT MATCHED pool, only insert the ones which have a certain column value above 20. So essentially, BigQuery UPSERT is a very special case of MERGE.
- Now, an in-depth explanation of the MERGE statement can be found in the documentation, along with several examples. We will focus on the special case: UPSERT. Here’s the structure of the BigQuery UPSERT statement implemented using MERGE:
MERGE INTO target_table T
USING source_table S
ON condition
WHEN MATCHED THEN
UPDATE statement
WHEN NOT MATCHED THEN
INSERT statement- As you can see, when both the source table and target table contain matching rows for the given condition, then the rows of the target table are updated. The additional rows in the source table (with no match in the target table) are inserted into the target table. In the next section, you will understand the example of BigQUery UPSERT query using MERGE statements.
Example of BigQuery UPSERT using MERGE
- Let us understand this through an example. Let us create two tables: payroll and payroll_2022, and populate them with some dummy data. Now, payroll is like the master table which needs to be up-to-date, while payroll_2022 contains the latest payroll data which we will use to update the payroll table.
- Creating and Populating the payroll table:
CREATE TABLE my_first_dataset.payroll(
employee_id INTEGER,
annual_ctc INTEGER
);
INSERT INTO my_first_dataset.payroll(employee_id, annual_ctc)
VALUES (1,300000),
(2,350000),
(3,250000)
Creating and populating the payroll_2022 table
CREATE TABLE my_first_dataset.payroll_2022(
employee_id INTEGER,
annual_ctc INTEGER
);
INSERT INTO my_first_dataset.payroll_2022(employee_id, annual_ctc)
VALUES (1,320000),
(2,400000),
(3,280000),
(4,250000)
UPSERT operation:
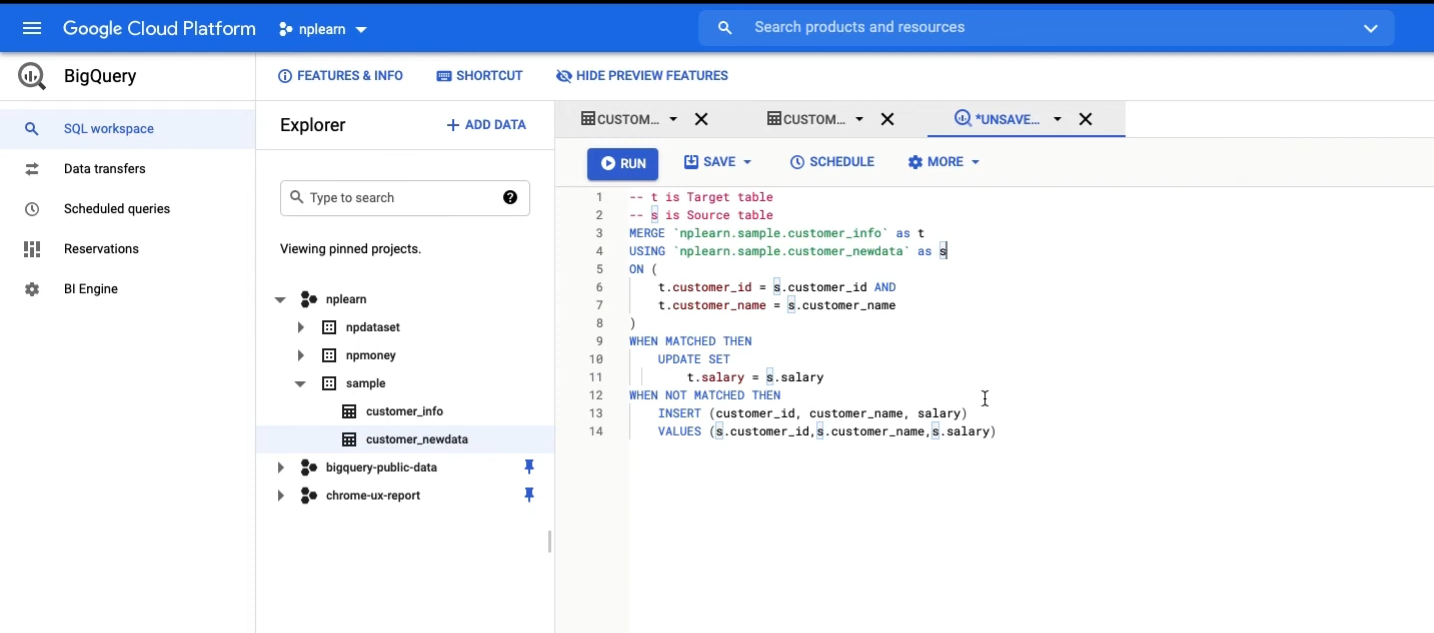
MERGE my_first_dataset.payroll T
USING my_first_dataset.payroll_2022 S
ON T.employee_id = S.employee_id
WHEN MATCHED THEN
UPDATE SET annual_ctc = S.annual_ctc
WHEN NOT MATCHED THEN
INSERT (employee_id, annual_ctc) VALUES(employee_id, annual_ctc)- Now let’s break down the BigQuery UPSERT operation. We are essentially defining payroll as the Target table, and payroll_2022 as the Source table.
- By using the ON clause, we specify how the comparison should be done. The WHEN MATCHED clause essentially specifies what to do when an employee_id in S matches an employee_id in T.
- In that case, we state that the annual_ctc in T should be updated using the annual_ctc in S. Similarly, the WHEN NOT MATCHED clause specifies what to do when an employee_id in S does not match any employee_id in T. In that case, we insert a row into T, using values from S.
- Note: In the WHEN MATCHED and WHEN NOT MATCHED clauses, operations only happen on the Target table. The Source table is not modified. It is only used to modify the target table.
- After running the BigQuery UPSERT query, if you query the contents of the Target table (SELECT * from payroll), you will see the following output:

- As you can see, the CTC values for employee_ids 1,2, and 3 have been updated, whereas a new row has been added for employee_id 4. Thus, BigQuery Merge UPSERT worked as expected.


Working with BigQuery EXECUTE IMMEDIATE
Now let’s come to the next part of this article: EXECUTE IMMEDIATE statements. In order to appreciate the need for these statements, we first need to understand the concept of Dynamic SQL.
Simply put, Dynamic SQL helps you construct SQL statements dynamically at runtime. Thus, think of SQL queries with variables and unknowns (for column names, variables names, WHERE condition elements, etc.), which get populated at runtime. Dynamic SQL makes it possible.
EXECUTE IMMEDIATE statements allow you to do two things essentially:
- Populate the results of an SQL query to a variable
- Substitute placeholders in SQL queries with values
Thus, the syntax of an EXECUTE IMMEDIATE statement is:
EXECUTE IMMEDIATE sql_expression [[INTO var…]] [[USING values...]]Over here, sql_expression can be:
- Query statement
- An expression that can be used on a query statement (CASE, IF, etc.)
- A single Data Definition Language (DDL) statement (CREATE TABLE, ALTER TABLE, etc.)
- A single Data Manipulation Language (DML) statement (INSERT, UPDATE, MERGE, etc.)
The INTO clause can be used to store the results of the query in one or more variables. The USING clause can be used to populate one or more placeholders in the query. The placeholders can either be ? or @identifiers. The examples below will give you more clarity:
Note:
- One EXECUTE IMMEDIATE statement cannot be nested into another.
- If the statement does not return rows, all variables in the INTO clause will be set to NULL.
- If the statement returns more than 1 row, with an INTO clause, an error will be thrown.
- When exactly one row is returned with an INTO clause, values are assigned by position, not variable names.
Example of BigQuery EXECUTE IMMEDIATE
- Let’s look at some examples to get more clarity. We’ll use the same payroll table that we considered in the previous section.
DECLARE x INT64;
DECLARE y INT64;
EXECUTE IMMEDIATE "SELECT * from my_first_dataset.payroll LIMIT 1" INTO x, y- Payroll table has two columns: employee_id, and annual_ctc. This query will store the value of employee_id of the returned row in x, and the annual_ctc in y.
- You can verify the same using a second query after EXECUTE IMMEDIATE:
DECLARE x INT64;
DECLARE y INT64;
EXECUTE IMMEDIATE "SELECT * from my_first_dataset.payroll LIMIT 1" INTO x, y;
SELECT x,y;- Let’s now consider an example with placeholders:
EXECUTE IMMEDIATE "INSERT INTO my_first_dataset.payroll(employee_id, annual_ctc) VALUES(?,?)" USING 5, 600000- Over here, we directly substituted for the ? placeholders. We can even substitute with variables.
DECLARE id INT64;
DECLARE ctc INT64;
SET id = 6;
SET ctc = 500000;
EXECUTE IMMEDIATE "INSERT INTO my_first_dataset.payroll(employee_id, annual_ctc) VALUES(?,?)" USING id, ctc- We can use more legible @identifiers for placeholders instead of ? placeholders:
DECLARE id INT64;
DECLARE ctc INT64;
SET id = 7;
SET ctc = 400000;
EXECUTE IMMEDIATE "INSERT INTO my_first_dataset.payroll(employee_id, annual_ctc) VALUES(@employee_id,@annual_ctc)" USING id as employee_id, ctc as annual_ctcSummary
- You saw how the MERGE statement can be used to construct BigQuery UPSERT statements in BigQuery.
- You also saw how BigQuery UPSERT is, in fact, a special case of MERGE, and how the actual utility of MERGE is much broader.
- In the second half of the article, you saw the use of the EXECUTE IMMEDIATE statements, and how they can help populate variables or be populated by variables.
- However, extracting complex data from a diverse set of data sources like Databases, CRMs, Project management Tools, Streaming Services, Marketing Platforms to your Google BigQuery can be quite challenging. This is where a simpler alternative like Hevo can save your day!
Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources, including 60+ Free Sources, into your Data Warehouse such as Google BigQuery to be visualized in a BI tool.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Question
1. Does BigQuery have upsert?
Yes, BigQuery supports upserts using the MERGE statement.
2. How to write a MERGE statement in BigQuery?
MERGE INTO target_table AS target
USING source_table AS source
ON target.id = source.id
WHEN MATCHED THEN
UPDATE SET target.column1 = source.column1, target.column2 = source.column2
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (source.id, source.column1, source.column2);
3. How to update BigQuery data?
You can update data in BigQuery using the UPDATE statement: UPDATE target_table
SET column1 = 'new_value'
WHERE condition;

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link




