

AWS Lambda is a serverless computing service that lets you run code without worrying about managing servers. It handles everything from server maintenance and capacity provisioning to automatic scaling, code monitoring, and logging, all on a high-availability infrastructure. Lambda is highly scalable, and cost-effective, and allows you to run self-contained applications for tasks like serving web pages, processing data streams, or connecting with AWS and third-party services.
In this guide, we’ll explore how to work with Boto3 in AWS Lambda, perform data wrangling, and save metrics and charts to an S3 bucket. We’ll use Python3, Boto3, and some additional libraries in Lambda Layers. While using Boto3 with Lambda may not be the best practice for cloud computing, this step-by-step demonstration is designed to help beginners get familiar with the basics of Lambda through the console.
Table of Contents
What is AWS Lambda?

AWS Lambda is a serverless, event-driven computing platform from Amazon Web Services that automatically manages the resources needed to run your code in response to events. It supports languages like Node.js, Python, Java, Go, Ruby, and C# (.NET) and has allowed custom runtimes since 2018, enabling you to run code like Haskell through supported runtimes.
Lambda is perfect for tasks like uploading files to S3, updating DynamoDB, responding to website clicks, or processing IoT sensor data. It can also automatically spin up backend services triggered by custom HTTP requests via API Gateway and spin them down when idle to save resources. With API Gateway and AWS Cognito, you can even handle authentication and authorization seamlessly.
Key Features of AWS Lambda
Here are some features of AWS Lambda:
- Integrated Fault Tolerance: To help protect your code against individual machine or data center facility failures, AWS Lambda maintains compute capacity across multiple Availability Zones (AZs) in each AWS Region.
- Scaling on the fly: AWS Lambda executes your code only when it is required and scales automatically to meet the volume of incoming requests without any manual configuration. Your code has no limit on the number of requests it can handle.
- Access Shared File Systems: You can securely read, write, and persist large volumes of data at any scale using the Amazon Elastic File System (EFS) for AWS Lambda. To process data, you do not need to write code or download it to temporary storage. This saves you time, allowing you to concentrate on your business logic.
- Custom Logic can be used to extend other AWS services: AWS Lambda enables you to add custom logic to AWS resources like Amazon S3 buckets and Amazon DynamoDB tables, allowing you to easily compute data as it enters or moves through the cloud.
- Create your own Backend Services: AWS Lambda can be used to build new backend application services that are triggered on-demand via the Lambda application programming interface (API) or custom API endpoints built with Amazon API Gateway.
What is Boto3?

Boto is an official AWS SDK designed to make working with Python in Amazon Web Services easier. Originally a user-contributed library, it simplifies building Python-based cloud applications by converting AWS API responses into Python classes.
Boto comes in three versions: Boto, Boto3, and Botocore. Boto3, the latest version, supports Python 2.6.5, 2.7, and 3.3, offering service-specific features for easier development. It’s compatible with all AWS services like EC2, DynamoDB, S3, CloudWatch, and AWS Config.
While Boto3 replaced the older Boto 2 (which doesn’t support modern Python versions), some developers still use Boto 2 for legacy systems. Botocore, on the other hand, provides low-level access to AWS tools, letting users make direct client requests and handle raw API responses.
Key Features of Boto3
Features of Boto3 are listed below:
- APIs for Resources: Boto3’s APIs are divided into two levels. Client (or “low-level”) APIs map to the underlying HTTP API operations one-to-one.
- Consistent and up-to-date Interface: Boto3’s ‘client’ and ‘resource’ interfaces are driven by JSON models that describe AWS APIs and have dynamically generated classes. This enables us to provide extremely fast updates while maintaining high consistency across all supported services.
- Waiters: Boto3 includes ‘waiters,’ which poll for pre-defined status changes in AWS resources. You can, for example, start an Amazon EC2 instance and use a waiter to wait until it reaches the ‘running’ state, or you can create a new Amazon DynamoDB table and wait until it is ready to use.
- High-level Service-Specific Features: Boto3 includes many service-specific features, such as automatic multi-part transfers for Amazon S3 and simplified query conditions for Amazon DynamoDB.
Hevo Data, a Fully-managed Data Pipeline platform, can help you automate, simplify & enrich your data replication process in a few clicks. With Hevo’s wide variety of connectors and blazing-fast Data Pipelines, you can extract & load data from 150+ Data Sources (including 60+ free data sources) straight into your Data Warehouse or any Databases. To further streamline and prepare your data for analysis, you can process and enrich raw granular data using Hevo’s robust & built-in Transformation Layer without writing a single line of code!
Check out salient features of Hevo:
- Live Monitoring & Support: Hevo provides live data flow monitoring and 24/5 customer support via chat, email, and calls.
- Secure & Reliable: Hevo’s fault-tolerant architecture ensures secure, consistent data handling with zero loss and automatic schema management.
- User-Friendly & Scalable: Hevo’s simple UI makes it easy for new users, while its horizontal scaling manages growing data volumes with minimal latency.
- Efficient Data Transfer: Hevo supports real-time, incremental data loads, optimizing bandwidth usage for both ends.
Creating Boto3 Lambda Application
We now understand what Boto3 is and what features it offers. Let’s create a basic Python serverless application using Lambda and Boto3.
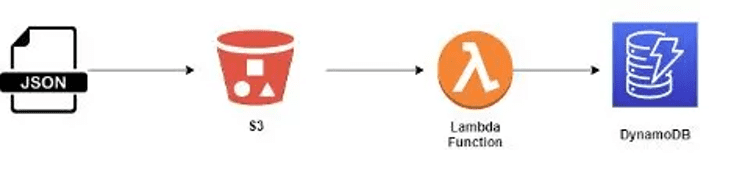
When a file is uploaded to an S3 bucket, a Boto3 Lambda Function is triggered to read the file and store it in a DynamoDB table. The architecture will be as follows:
- Step 1: Create a JSON file
- Step 2: Make an S3 bucket
- Step 3: Make a DynamoDB Table
- Step 4: Construct a Lambda Function
Step 1: Create a JSON file
First, let’s make a small JSON file with some sample customer data. This is the file we’d put in the S3 bucket. Let us call it data.JSON.
#data.json
{
"customerId": "xy100",
"firstName": "Tom",
"lastName": "Alter",
"status": "active",
"isPremium": true
}Step 2: Make an S3 bucket
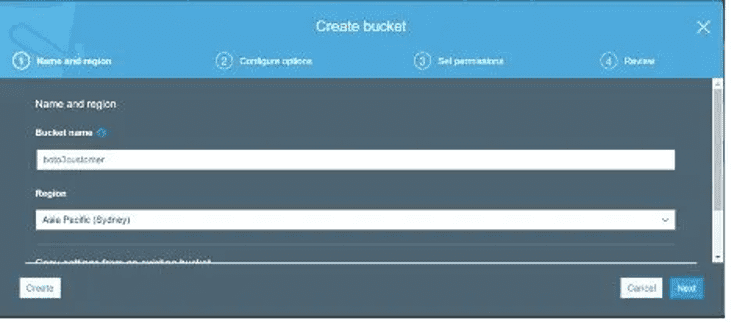
Let’s now create an S3 Bucket to which the JSON file will be uploaded. Let’s call it Boto3 Lambda customer for now. For this example, we’ve created a bucket with all of the default features:
Step 3: Make a DynamoDB Table
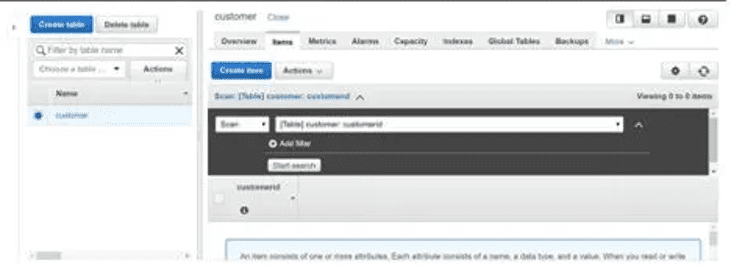
Let’s make a DynamoDB table (customer) to store the JSON file. Customer-id should be marked as a partition key. We must ensure that our data is accurate. This field must be present in the JSON file before it can be inserted into the table; otherwise, the table will complain about a missing key.
Step 4: Construct a Lambda Function
To interact with these services, we must first create an IAM role with access to CloudWatch Logs, S3, and DynamoDB. Then, we’ll write code in boto3 to download, parse, and save the data to the customer’s DynamoDB table. Then, create a trigger that connects the S3 bucket to Boto3 Lambda so that when we push a file into the bucket, it is picked up by the Lambda Function.
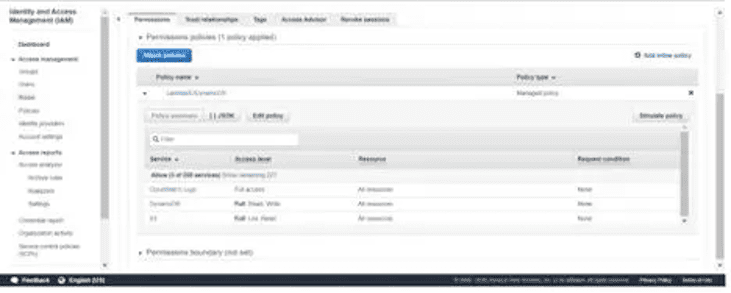
Let’s start by creating an IAM role. To log every event transaction, the IAM Role must have at least read access to S3, write access to DynamoDB, and full access to the CloudWatch Logs service:
Create a function now. Give it a unique name and choose Python 3.7 as the runtime language:
Now, select the role Boto3 Lambda S3 DyanamoDB that we created earlier and press the Create function button.
Now, for the Boto3 Lambda Function, follow the steps below:
- To load the service instance object, write the python code using the boto3 resource API.
- An event object is used to pass the file’s metadata (S3 bucket, filename).
- Then, using S3 client action methods, load S3 file data into the JSON object.
- Save the JSON data into the DyanamoDB table after parsing it (customer)
import json
import boto3
dynamodb = boto3.resource('dynamodb')
s3_client = boto3.client('s3')
table = dynamodb.Table('customer')
def lambda_handler(event, context):
# Retrieve File Information
bucket_name = event['Records'][0]['s3']['bucket']['name']
s3_file_name = event['Records'][0]['s3']['object']['key']
# Load Data in object
json_object = s3_client.get_object(Bucket=bucket_name, Key= s3_file_name)
jsonFileReader = json_object['Body'].read()
jsonDict = json.loads(jsonFileReader)
# Save date in dynamodb table
table.put_item( Item=jsonDict)Evaluating the Boto3 Lambda Function
Let’s put this Boto3 Lambda function customer update to the test.
- To begin, we must upload a JSON file to the S3 bucket boto3customer.
- The customer is updated as soon as the file is uploaded to the S3 bucket.
- It will run the code that receives the file’s metadata via the event object and loads the file’s content using boto3 APIs.
- The content is then saved to the customer table in DynamoDB.
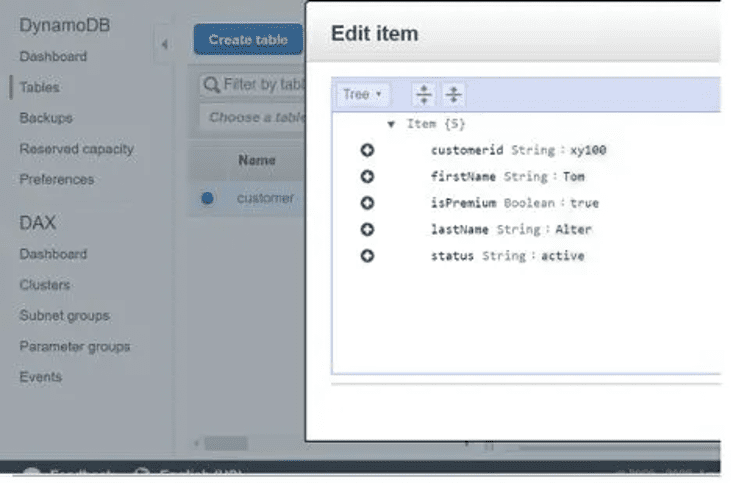
The file content was saved in the DyanamoDB table, This concludes our implementation of a serverless application with Python runtime using the boto3 library.
Limitations of Boto3 Lambda Application
Here are some limitations you need to watch out for before using Boto3 Lambda:
- Extensive Unit Testing: Given the distributed nature of serverless functions, having verification in place is important for peace of mind when deploying functions that run infrequently. While unit and functional testing cannot fully protect against all issues, it can provide you with the assurance you need to deploy your changes.
- Time Limits: AWS Lambda functions have built-in time limits for execution. These can be set to as many as 900 seconds, but the default is 3. If your function is likely to require long run times, make sure this value is properly configured.
- Third-party Resources: It’s powerful to have complete control over everything, but it can also be distracting and time-consuming.
Conclusion
Here are the key takeaways from this blog:
- AWS Lambda is ideal for event-driven and intermittent workloads, allowing you to create and iterate on functionality quickly without worrying about infrastructure or scaling.
- Python brings a powerful and robust environment to serverless applications, especially when best practices are followed.
- To manage databases efficiently, it’s helpful to integrate them with tools that handle data integration and management seamlessly.
- Hevo Data, a cloud-based ETL tool, simplifies data integration and management without the need for coding.
- Hevo Data supports over 150 data sources and enables quick data transfers to warehouses like Amazon Redshift in just minutes.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand. Hevo offers plans & pricing for different use cases and business needs, check them out!
Share your experience of Working with Boto3 Lambda (AWS) in the comments section below!
FAQs
1. What is Boto3 in Lambda?
Boto3 is the AWS SDK for Python, commonly used in AWS Lambda to interact with AWS services like S3, DynamoDB, and EC2. It simplifies API calls, making it easy to perform tasks like reading from S3 buckets or updating a DynamoDB table directly within your Lambda functions.
2. Is Boto3 preinstalled in Lambda?
Yes, Boto3 is preinstalled in AWS Lambda by default, so you don’t need to include it in your deployment package. However, it may not always be the latest version, so if you need a specific version, you can package it with your function code.
3. How to invoke Lambda using Boto3?
You can invoke a Lambda function using Boto3’s invoke method from the Lambda client. Simply specify the function name and include the payload (if needed) in JSON format. For example, you can use boto3.client(‘lambda’).invoke(FunctionName=’MyFunction’, Payload=json.dumps(payload)) to trigger the function programmatically.
4. What is Boto3 used for?
Boto3 is the AWS SDK for Python, used to interact with AWS services like S3, DynamoDB, EC2, and more. It simplifies tasks like managing cloud resources, automating infrastructure, and handling data operations programmatically.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





