

Companies regularly need to update their applications for smooth functioning and implementation of new features. Developers continuously work on making the applications fast, smooth and secure. Modern applications use serverless and Cloud technologies For this, it is essential to have hands-on versatile programming languages such as Java.
Java is a high-level programming language widely used in the majority of enterprise applications and backend services for running business activities. Using serverless computing services in applications such as AWS Lambda improves applications’ performance significantly. AWS Lambda Java projects are easy to build and manage.
AWS Lambda Java functions can be created on Eclipse IDE and run via uploading it to the AWS Lambda. In this article, you will learn about the steps to create, upload and invoke the AWS Lambda Java functions with an example.
Table of Contents
Introduction to AWS Lambda

AWS Lambda is the computing service offered by Amazon Web Services that allows you to do so without managing any server. It is an event-driven and serverless computing platform that runs code in response to events. AWS Lambda officially supports Python, Node.js, Java, Go, Ruby, and C# language.
AWS Lambda uses a serverless computing service that executes Lambda functions to perform any computing task, from serving web pages to processing data streams. A well-configured AWS Lambda pipeline streamlines task execution, ensuring smooth data processing and integration with other AWS services.
Key Features of AWS Lambda
Some of the main features of AWS Lambda are listed below:
- Fault-tolerance: AWS Lambda helps users protect their code against individual machine or data center facility failures by maintaining compute capacity across multiple Availability Zones.
- Auto-Scaling: AWS Lambda can automatically scale for supporting the rate of incoming requests and invoking the code only when needed.
- Flexible Resource Model: Users can choose the amount of memory they want to allocate to functions and it will CPU power, network bandwidth, and disk input/output (I/O) proportionally.
- Automated Administration: AWS Lambda is capable of managing all the infrastructure for you to run your code and help you focus more on building backend services.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate and load data from 150+ different sources (including 60+ free sources) to a Data Warehouse such as Amazon Redshift and S3 or Destination of your choice. Ensure seamless data migration using features like:
- Seamless integration with your desired data warehouse, such as Redshift.
- Transform and map data easily with drag-and-drop features.
- Real-time data migration to leverage Redshift’s AI/ML features.
Still not sure? See how Postman, the world’s leading API platform, used Hevo to save 30-40 hours of developer efforts monthly and found a one-stop solution for all its data integration needs.
Get Started with Hevo for FreeRunning AWS Lambda Java Funcion
Now that you have understood the AWS Lambda and Java language. In this section, you will learn about the procedure and steps to create, upload and invoke an AWS Lambda Java function. For creating AWS Lambda Java functions you need to have an AWS account and AWS Toolkit for Eclipse installed. The following steps for working with the AWS Lambda Java function are listed below:
- Step 1: Creating an AWS Lambda Project
- Step 2: Implementing the Handler Method
- Step 3: Creating an IAM Role for AWS Lambda Java Project
- Step 4: Creating AWS S3 Bucket
- Step 5: Uploading the AWS Lambda Java Code
- Step 6: Invoking the AWS Lambda Java Function
Step 1: Creating an AWS Lambda Project
- Use the IDE such as Eclipse, IntelliJ, or Visual Studio Code with the AWS SDK installed.
- Create a new Maven or Gradle project.
- Add the dependencies for AWS Lambda under your project’s pom.xml or build.gradle.
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-core</artifactId>
<version>1.2.3</version> <!-- Replace with the latest version -->
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-events</artifactId>
<version>3.11.0</version> <!-- Optional, for pre-defined event types -->
</dependency>Step 2: Implementing the Handler Method
- Now, let’s implement the AWS Lambda Java function in the “HelloLambda” project created.
- In the “Project Explorer” of Eclipse, open up the “Hello.java” file.
- It has the similar code given below.
package com.example.lambda.demo;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
public class Hello implements RequestHandler<Object, String> {
@Override
public String handleRequest(Object input, Context context) {
context.getLogger().log("Input: " + input);
// TODO: implement your handler
return "Hello from Lambda";
}
}- Now, replace the contents of the “handleRequest” function with the code given below.
@Override
public String handleRequest(String input, Context context) {
context.getLogger().log("Input: " + input);
String output = "Hello, " + input + "!";
return output;
}


Step 3: Creating an IAM Role for AWS Lambda Java Project
- Sign in to your AWS Management Console here.
- Now, open the “IAM Console” from the “Services” menu.
- From the navigation panel, choose the “Roles” option and select the “Create role” option.
- Now, in the “Select type of trusted entity” drop-down menu, choose the “AWS service” option.
- Then, choose the “Lambda” option for the service that will use this role.
- Click on the “Next: Permissions” option.
- From the “Attach permissions policy” drop-down menu, choose the “AWSLambdaBasicExecutionRole” option.
- Then, click on the “Next: Review” button.
- Now, add a name for the role like for this AWS Lambda Java project, the name is “hello-lambda-role” and describe the role.
- Next, click on the “Create role” button to create an IAM role for the AWS Lambda Java project.
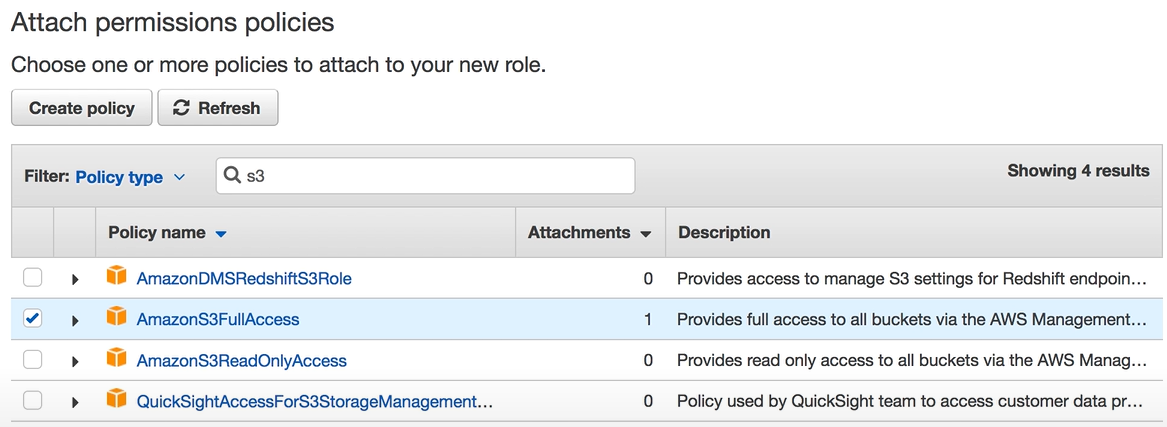
Step 4: Creating AWS S3 Bucket
- To store your AWS Lambda Java project, you need AWS S3 Bucket for uploading.
- If you already have an AWS S3 bucket then you can use that or create a new one, especially for the AWS Lambda Java function.
- Go to AWS Management Console and there open the “S3 Console” from the “Services” menu.
- Click on the “Create bucket” option.
- Now, provide the valid details to create an S3 bucket for your AWS Lambda Java project such as bucket name, region, etc.
- Click on the “Create” button to create an AWS S3 Bucket.
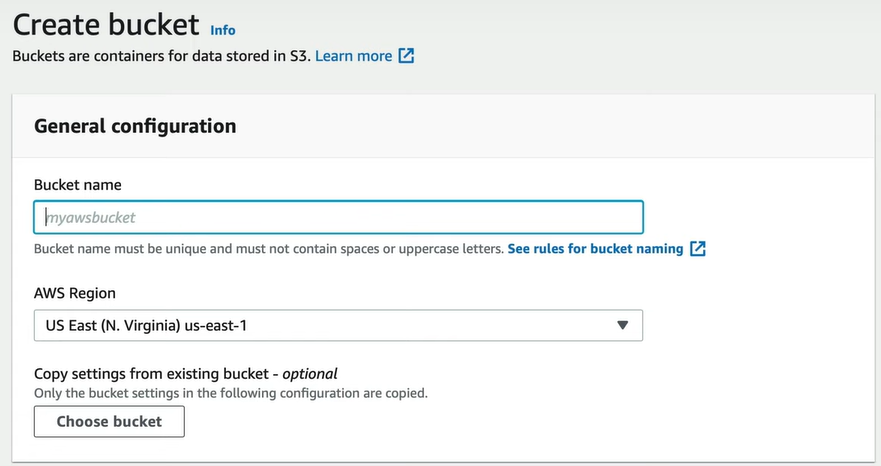
Step 5: Uploading the AWS Lambda Java Code
- Open Lambda Console.
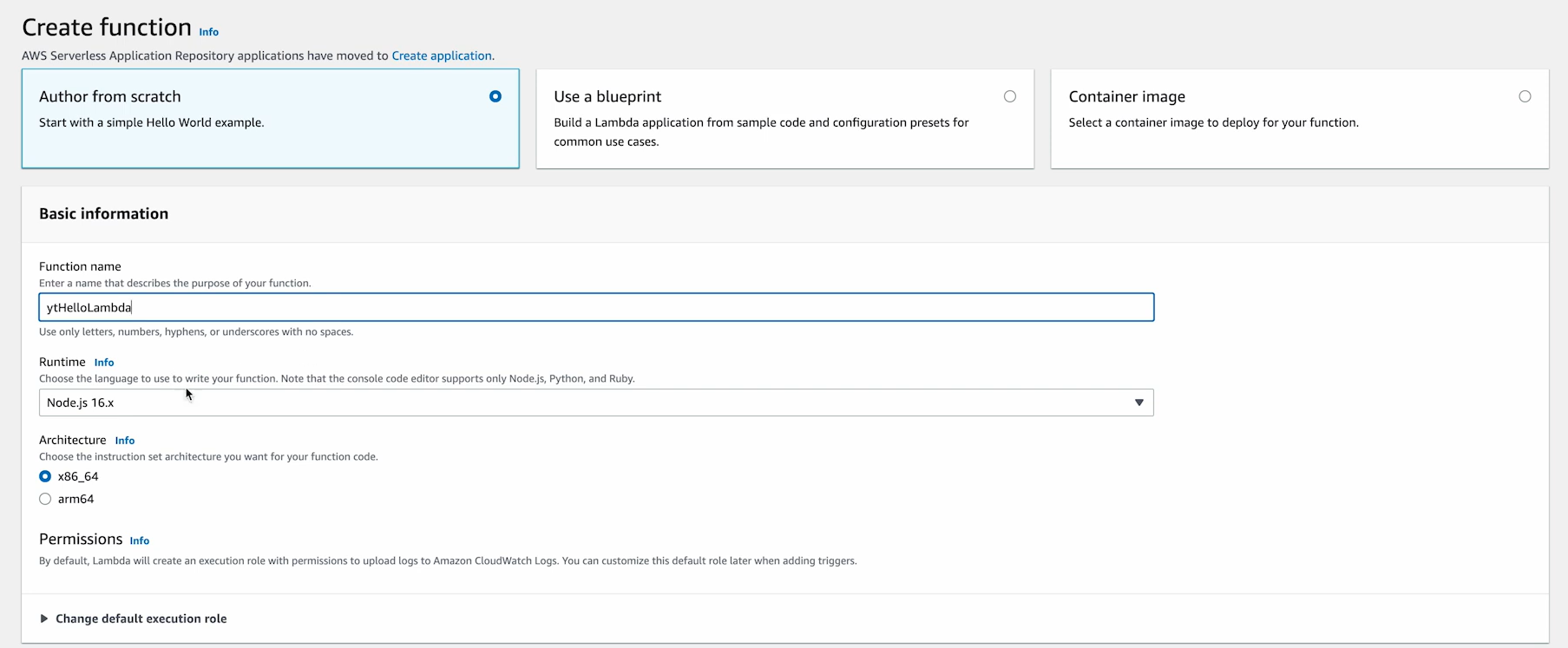
- Choose the “Create a new Lambda function” option and provide a name for your function, such as HelloLambda.
- Click on the “Next” option.
- Describe your target AWS Lambda Java function on the “Function Configuration” page, as shown in the image below.
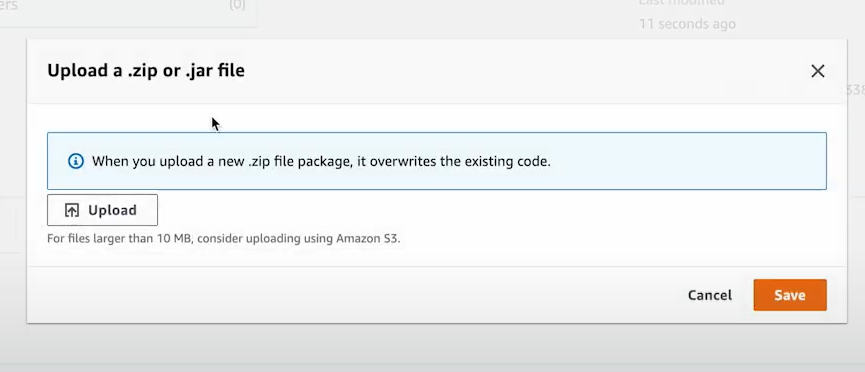
- Select Upload from .zip/.jar file.
- Assign the previously created IAM role.
Step 6: Invoking the AWS Lambda Java Function
- Use the Test option in the Lambda Console.
- Make a sample payload matching your function’s input.
import com.amazonaws.services.lambda.AWSLambdaClientBuilder;
import com.amazonaws.services.lambda.model.InvokeRequest;
import com.amazonaws.services.lambda.model.InvokeResult;
public class LambdaInvoker {
public static void main(String[] args) {
InvokeRequest request = new InvokeRequest()
.withFunctionName("FunctionName")
.withPayload("\"Test Input\"");
InvokeResult result = AWSLambdaClientBuilder.defaultClient().invoke(request);
System.out.println(new String(result.getPayload().array()));
}
}That’s it! You have successfully created, uploaded, and invoked your AWS Lambda Java function.
Conclusion
In this article, you learned about AWS Lambda and went through the steps to create, upload, and invoke AWS Lambda Java functions. You used AWS S3 Bucket to upload the AWS Lambda Java code from Ecplise and manage IAM roles for your AWS Lambda Java project. AWS Lambda helps Developers automatically manage the computing resources required by the code. AWS S3 Bucket is widely used as a storage space for data needed by applications and backend services.
Companies need to analyze their business data stored in multiple data sources. Data needs to be loaded from data sources such as AWS S3 Bucket to the Data Warehouse to get a holistic view of the data. Hevo Data is a No-code Data Pipeline solution that helps to transfer data from 150+ data sources to the desired Data Warehouse. It fully automates the process of transforming and transferring data to a destination without writing a single line of code.
Want to take Hevo for a spin? Sign Up here for a 14-day free trial and experience the feature-rich Hevo.
Share your experience of learning about running AWS Lambda Java Functions in the comments section below!
FAQs
1. Why use Lambda functions in Java?
Java lambdas simplify code by allowing you to write small inline methods; they tend to create concise and readable code. Especially for use cases like iterating through collections or defining behavior on the fly, Java lambdas are convenient.
2. How to deploy Java code in AWS Lambda?
Package your Java code into a JAR file with all dependencies. Upload the JAR to AWS Lambda via the console, AWS CLI, or Infrastructure-as-Code tools. Configure the runtime as Java, set the handler (e.g., com.example.Handler::method), and allocate resources like memory. Test it using the AWS Lambda interface.
3. What is the disadvantage of the lambda expression?
Lambda expressions may make your code harder to debug because they don’t have names and are inline. Using lambdas too much can damage readability, particularly if the logic is complex. They may also use more memory if references to external variables-closures-are accidentally kept alive and cause a potential memory leak.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




