

In this blog, we will explore how to build a data pipeline using AWS Glue S3. We will go through every step of the process, and by the end, you will see how straightforward it can be.
AWS Glue is a tool that makes building and managing your data pipelines easier. It’s fully managed, so we don’t have to worry about the nitty-gritty of infrastructure. Plus, it integrates seamlessly with AWS S3, which is perfect for storing all our data. Together, they’re a dynamic duo that can transform how you handle your data.
Ready? Let’s get started!
Table of Contents
What is AWS Glue?
Before jumping into the step-by-step, let’s quickly talk about AWS Glue. AWS Glue is a service that helps you prepare and load your data for analytics. It’s a managed ETL (Extract, Transform, Load) service, which means it can extract data from various sources, transform it into an easy-to-analyze format, and then load it where you need it.
Why Use AWS S3?
AWS S3, on the other hand, is a storage service that lets you store and retrieve any amount of data at any time. It’s highly durable, secure, and scalable. When we pair S3 with Glue, we get a powerful combination that allows us to manage large volumes of data effortlessly.
The Pipeline We’re Building
Here’s a high-level overview of what we’re going to do:
- Set up an S3 bucket where we’ll store our raw data.
- Create a Glue Data Catalog to organize and manage our data.
- Set up a Glue ETL job to transform the data.
- Store the transformed data back in S3 for further analysis or querying.
Connect S3 with Hevo to streamline your data integration. Our no-code platform makes it easy to automate data pipelines, ensuring seamless data flow from S3 to your desired destinations.
- Effortlessly perform both Pre and Post Load Transformation.
- No-code data integration for faster setup
- Real-time data processing and transformations
Join the 2000+ satisfied customers who prefer Hevo for their data integration needs. Experience Hevo’s simplicity and efficiency today.
Get Started with Hevo for FreeStep 1: Setting Up Your S3 Bucket
First things first, we need a place to store our data. AWS S3 is perfect for this because of its scalability and reliability. Let’s create one if you don’t already have an S3 bucket.
- Log into your AWS Management Console and search for S3.
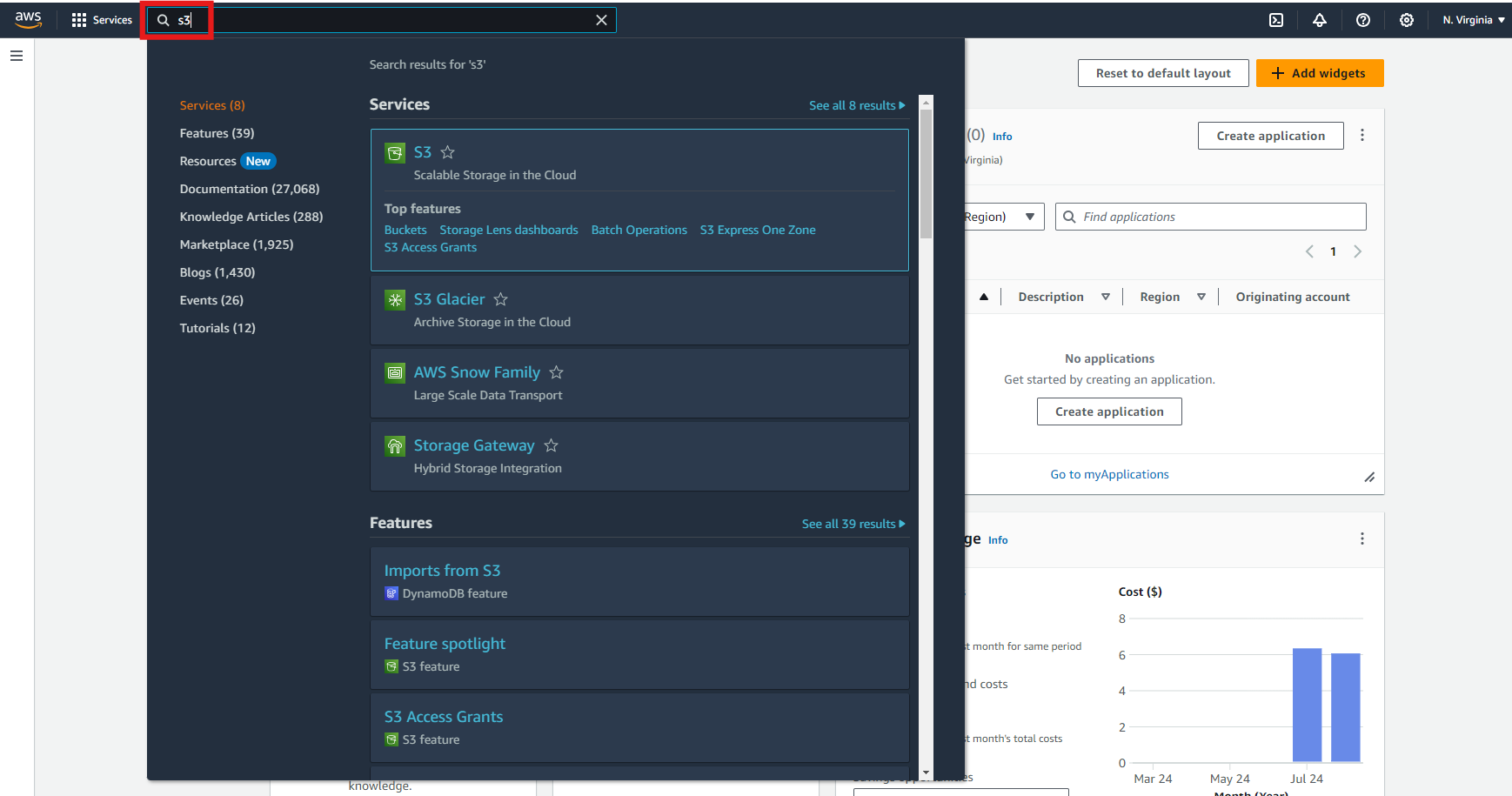
- Click on “Create Bucket”.
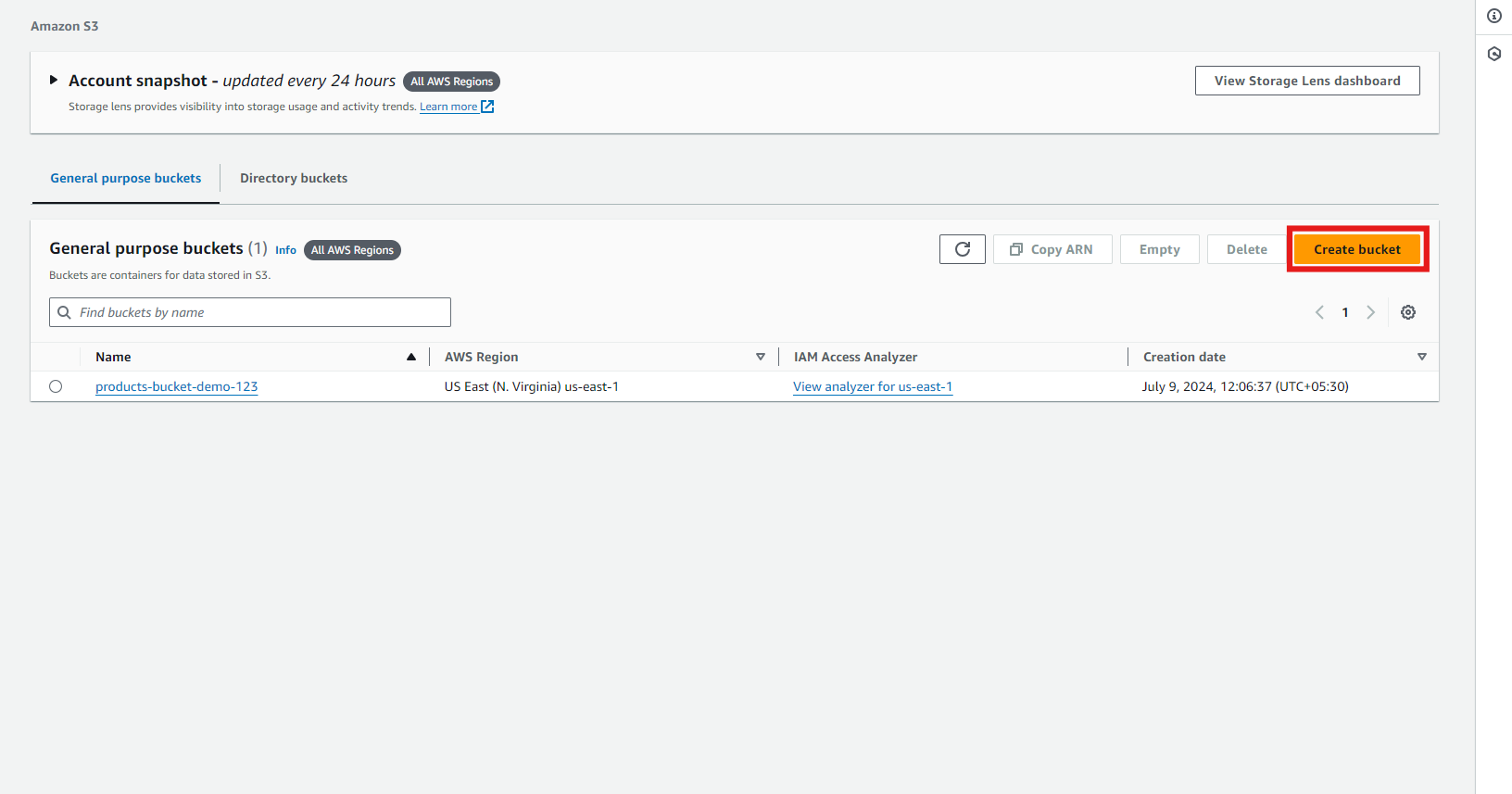
- Give your bucket a unique name. Remember, bucket names must be globally unique, so you might need to get creative!
- Choose the region where you want your bucket to be hosted. To minimize latency, it’s usually best to select a region close to you or your users.
- Configure additional settings (like versioning or encryption), then click “Create Bucket.”
Now, we’ve got our S3 bucket ready to go. This is where we’ll upload our raw data, which AWS Glue will process.
Step 2: Uploading Data to S3
Next, we’ll upload some data to our S3 bucket. This could be any dataset you have—CSV, JSON, or even logs.
- Go to your newly created S3 bucket and click on “Upload.” You can click on any one of the highlighted buttons to upload your file.
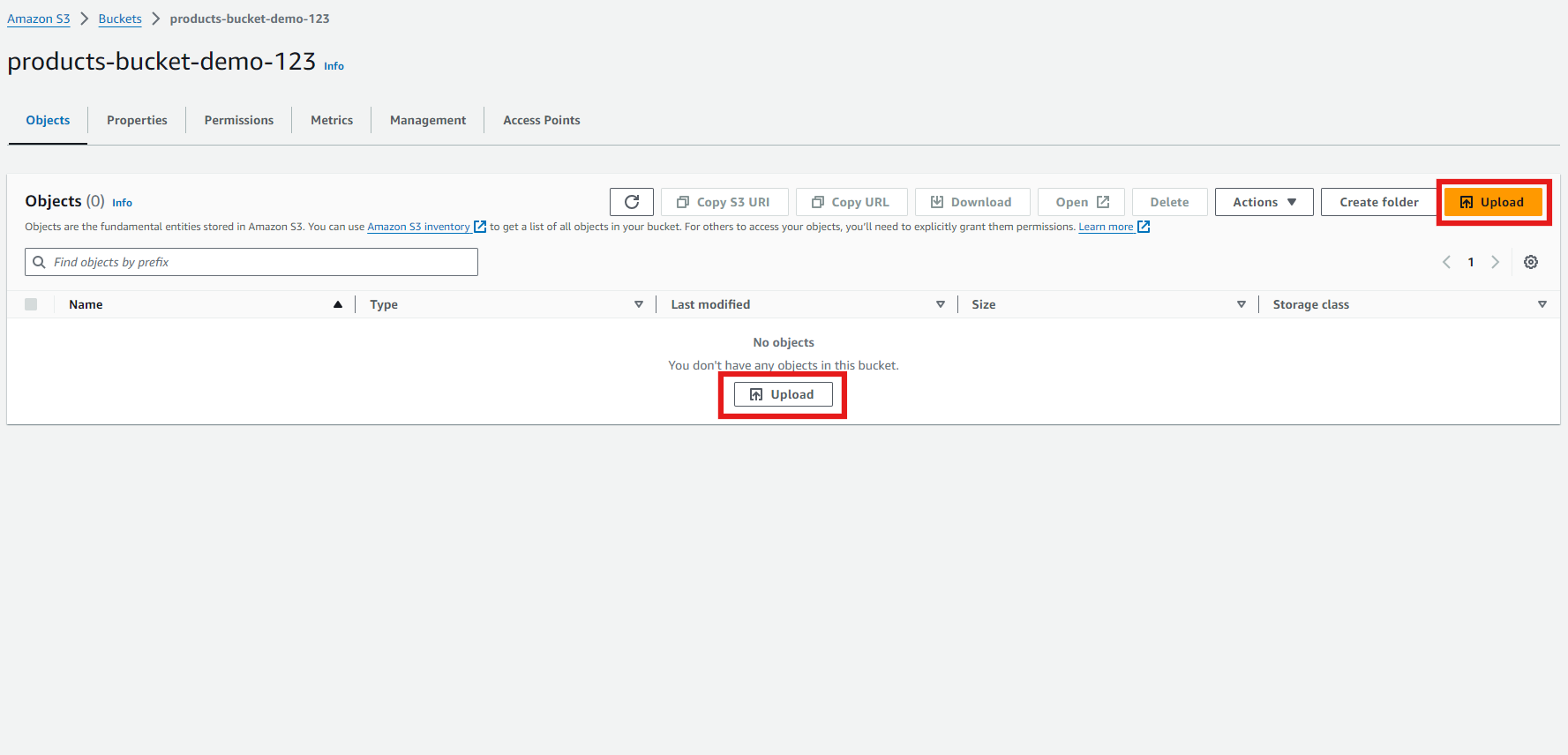
- Click on “Add files.” Choose the files you want to upload. We’re uploading a CSV file containing product sales data for this example.
Note: To upload multiple files, select “Add Folder,” all files inside that folder will automatically be uploaded to your Bucket.
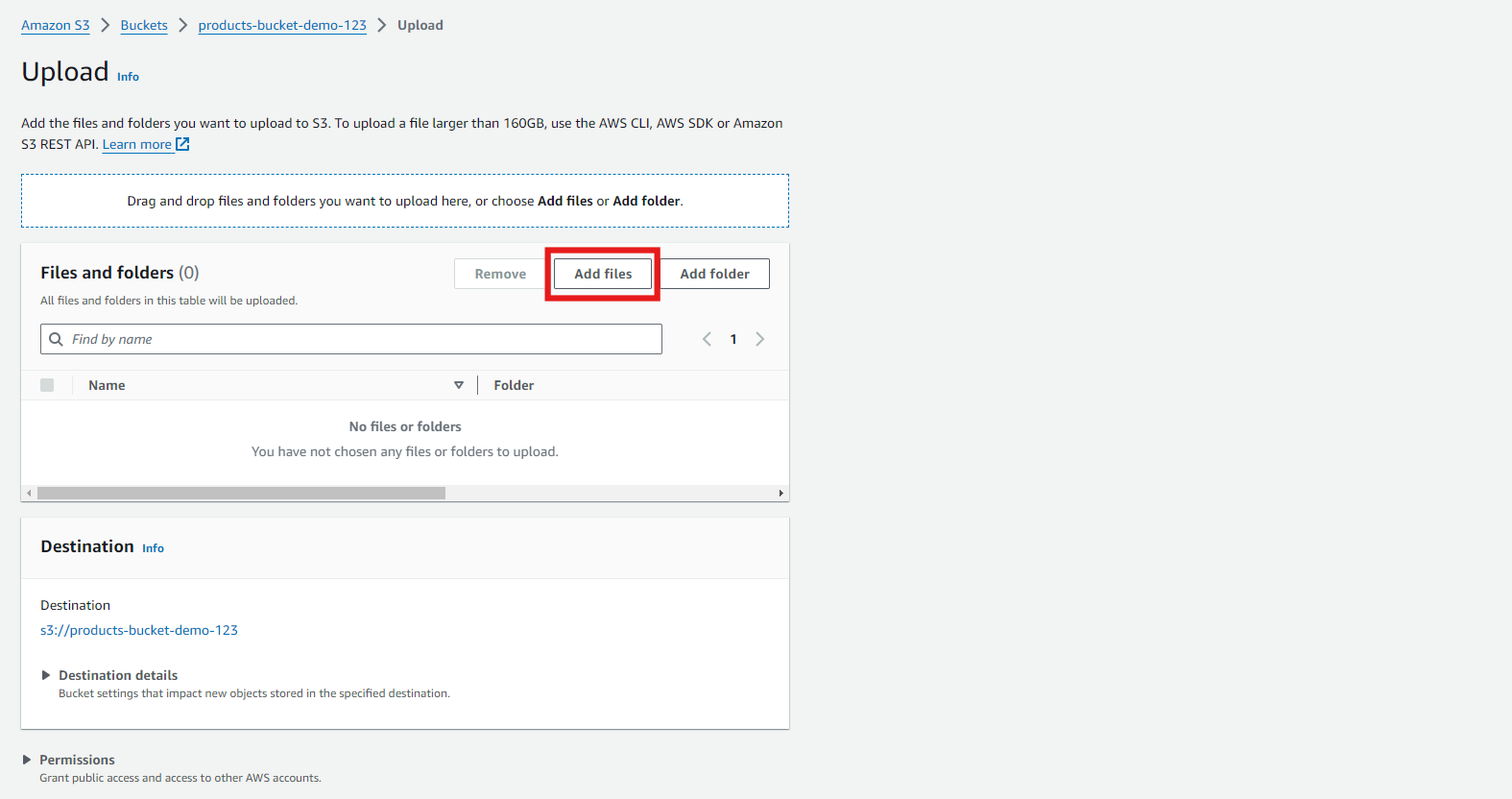
After uploading, scroll down and click on “Upload.”
- You’ll see the files listed in your bucket once they are uploaded.
Your raw data is sitting in S3 and ready to be processed.
Step 3: Creating the AWS Glue Data Catalog
With our data safely stored in S3, the next step is to create a Glue Data Catalog. This catalog will help us organize and manage our data.
- Navigate to the AWS Glue service in your AWS Console and search for “Data Catalog.”
- In the left panel, click on “Databases.”
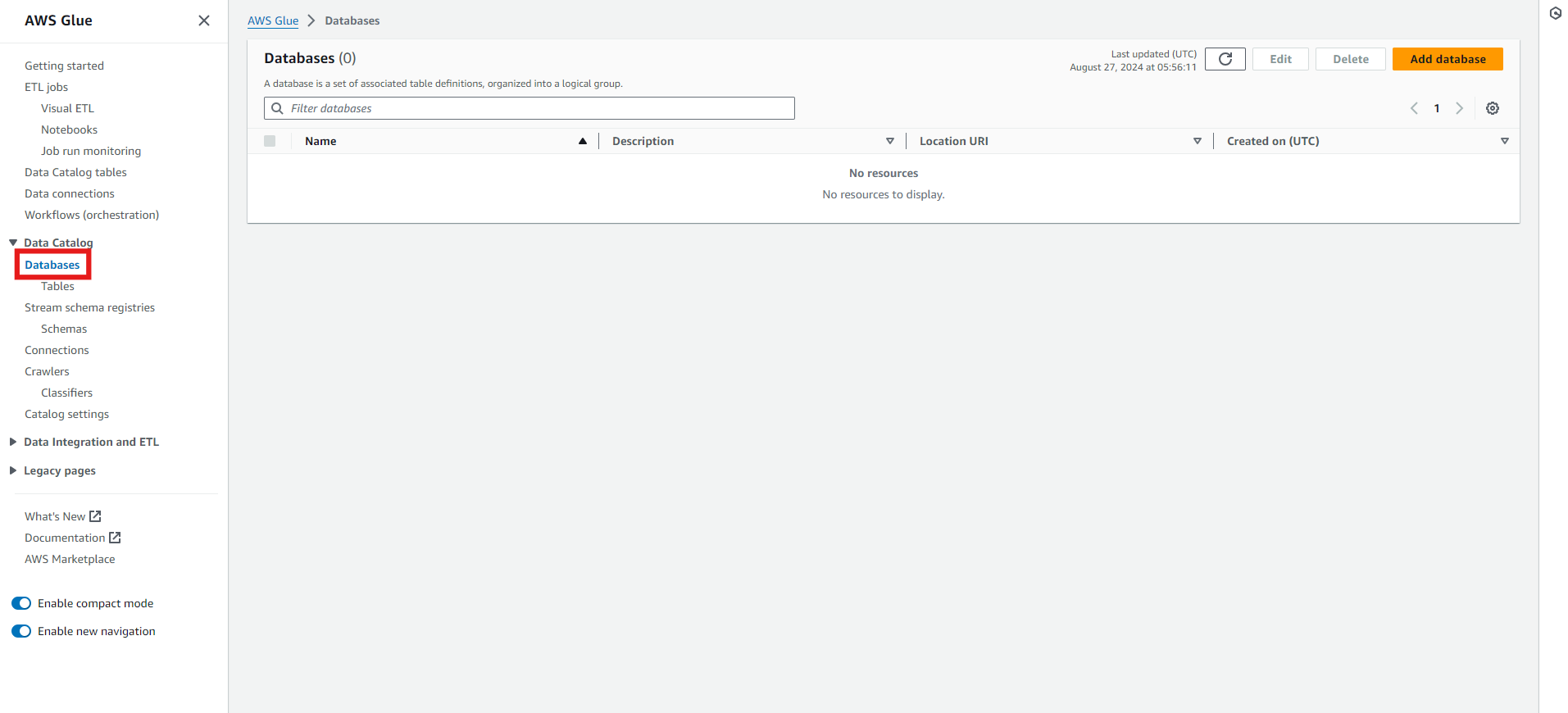
- Click on “Add Database.” Give your database a name, like product_sales. You can also provide a database description and set your URI location. Finally, click on “Create database.”
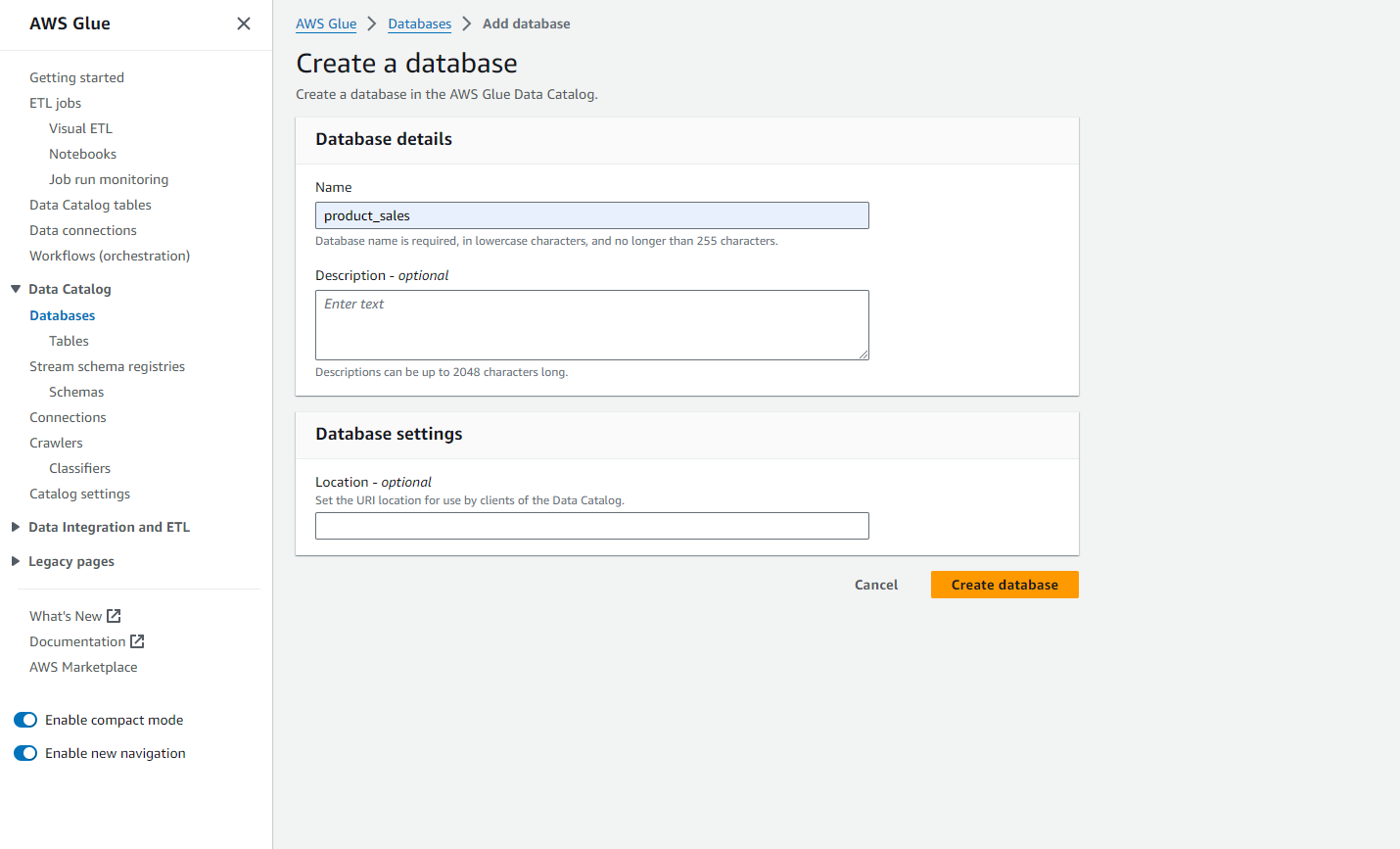
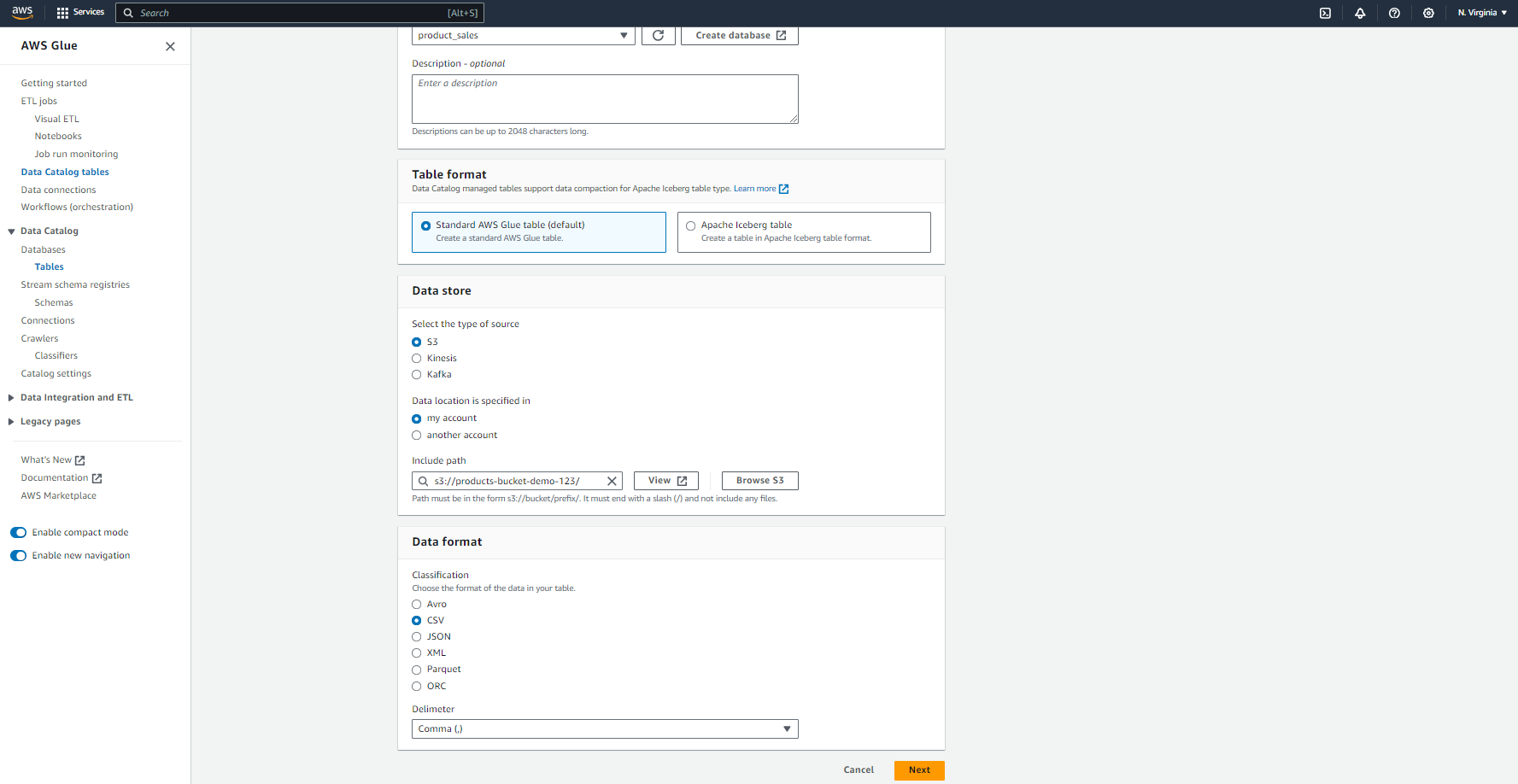
- Now, let’s create a table that points to the data in S3. Go to “Tables” and click “Add Table.”
- Provide the necessary details, like the table name (prod_table). Select your newly created Database. Set your Table format to Standard AWS Glue. Specify the S3 path where your data is located. Also, select your Data format—in my case, it is CSV with a comma delimiter. Click “Next.”
- Now, you need to define and manage your Schema. You need to manually add your schema as a JSON file. Then click on “Next.”
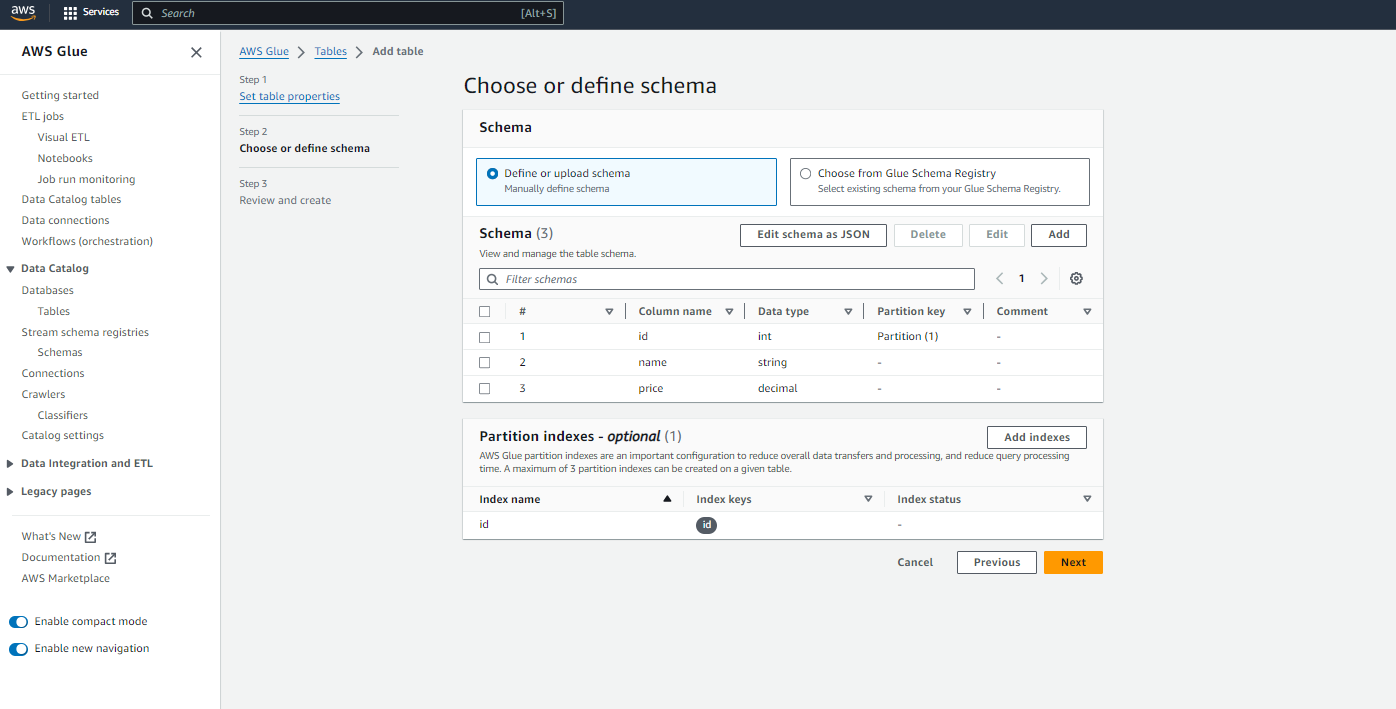
Note: This schema is according to my CSV file uploaded into my S3 bucket, and I want all of my data into my Glue table.
- For the final step, “Review” your details, change anything if necessary, and click “Create.”
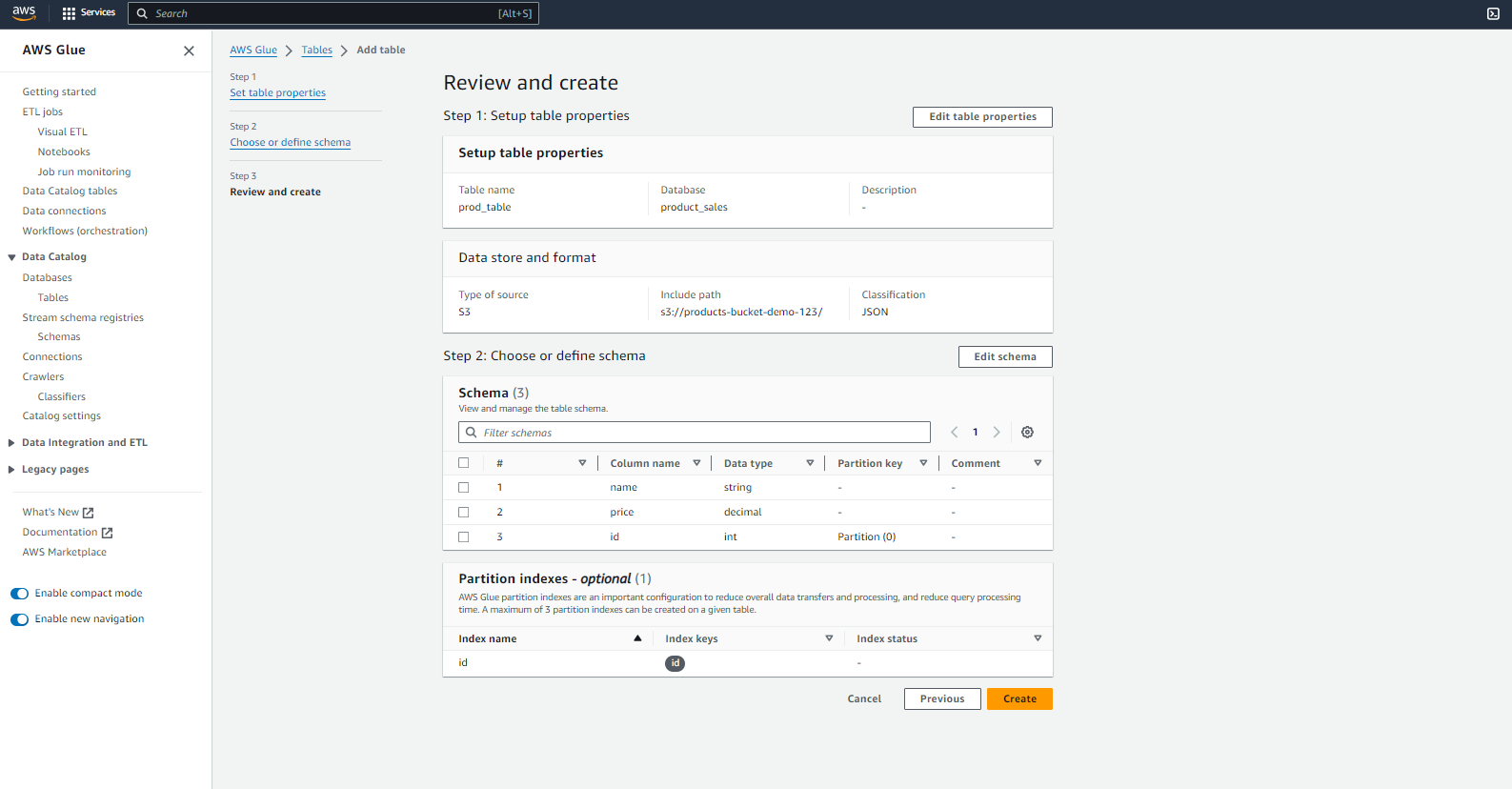
What we’ve done here is create a catalog that AWS Glue will use to understand the structure of our data. It’s like a blueprint that tells Glue where to find the data and how it’s structured.
Step 4: Creating a Glue ETL Job
Now that our data catalog is set up, it’s time for the fun part—creating an ETL job in Glue.
- In the Glue Console, click “ ETL Jobs” in the left-hand menu.
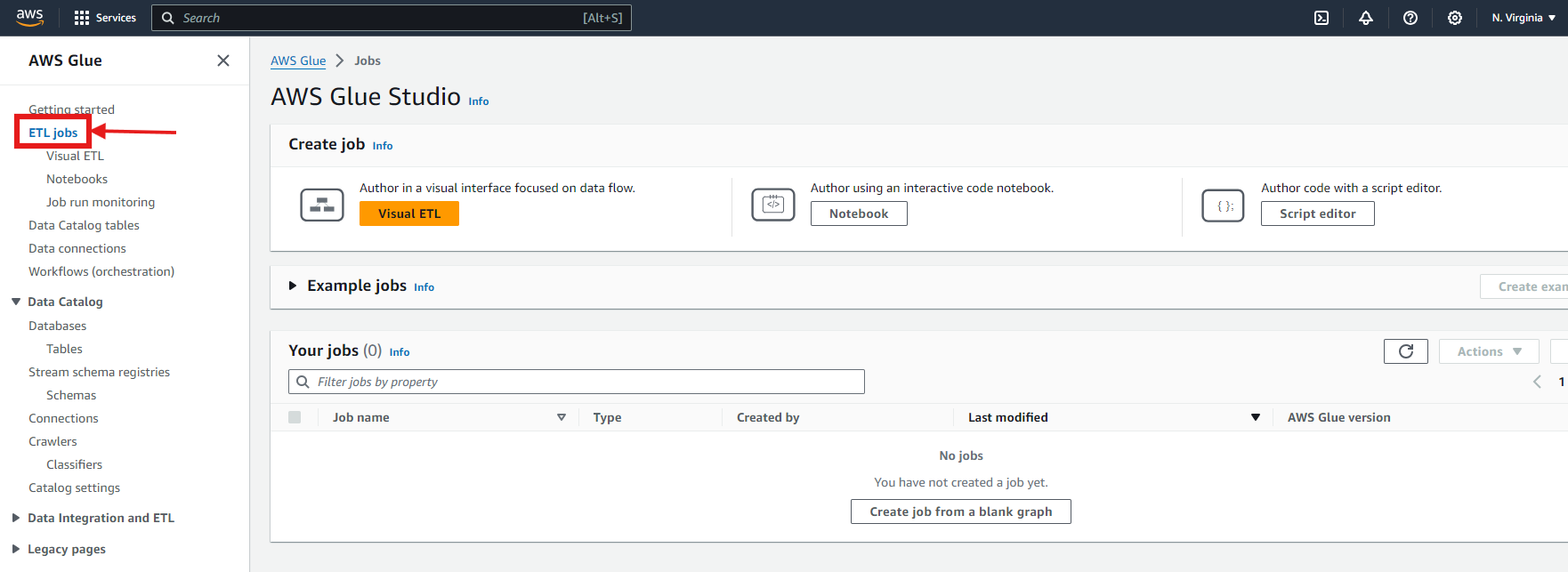
- You can now “Create Job” by a visual drag-and-drop interface, or you can upload your notebook or write your own script in Spark, or Ray, or Python.
For our case, I’ll be selecting the “Visual ETL.” - Fill out the necessary details. Give your job a name (etl_job).
- Select S3 as the Source.
- Provide your S3 object URL
- Specify your Data Format as CSV and select your delimiter.
- Select your Transformation type
- Select AWS Glue as your Target.
- Choose your Database
- Select your Table
- Select S3 as the Source.
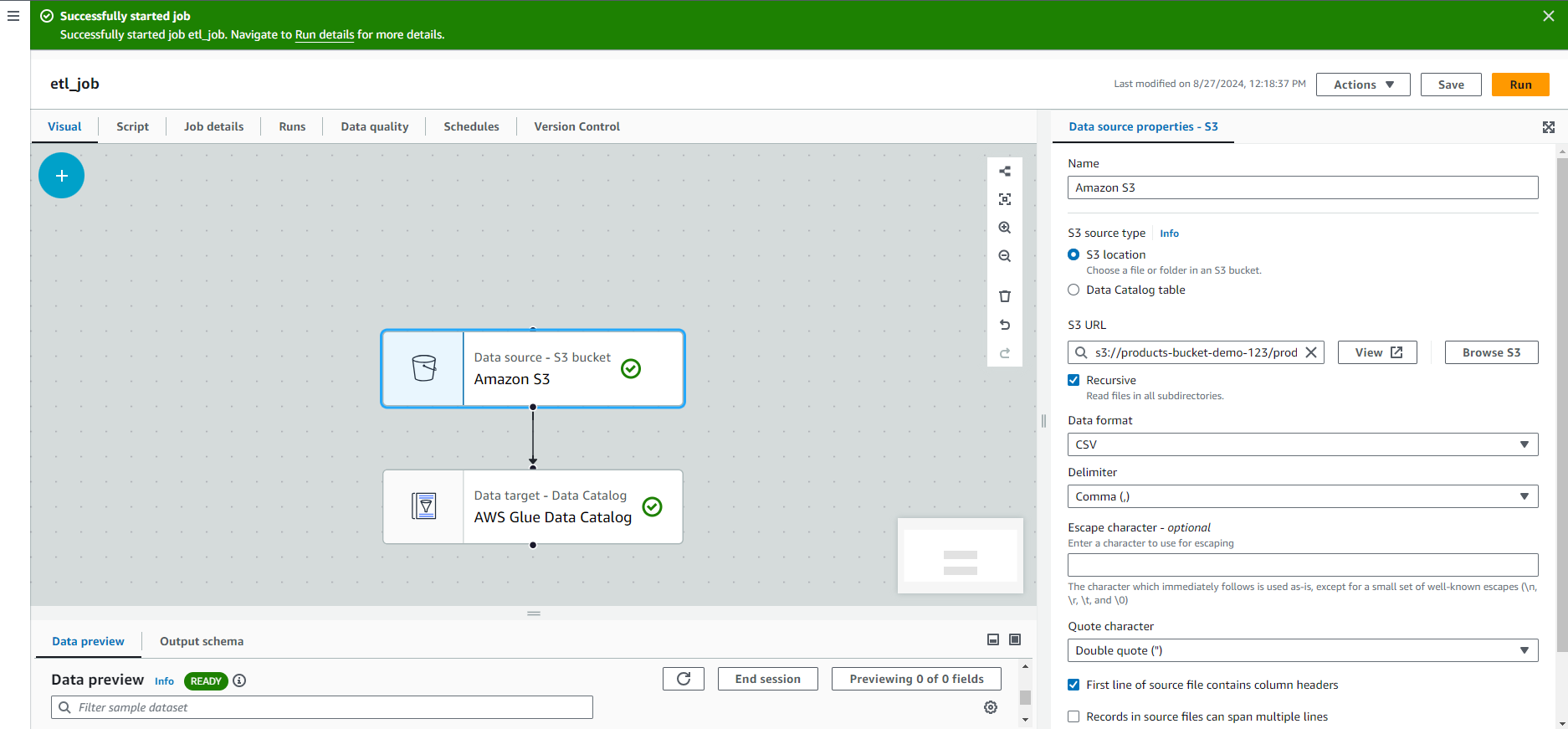
If everything is correct, you will see a green tick at the side of your source and target. And it everything goes well, the end result will look like the following:
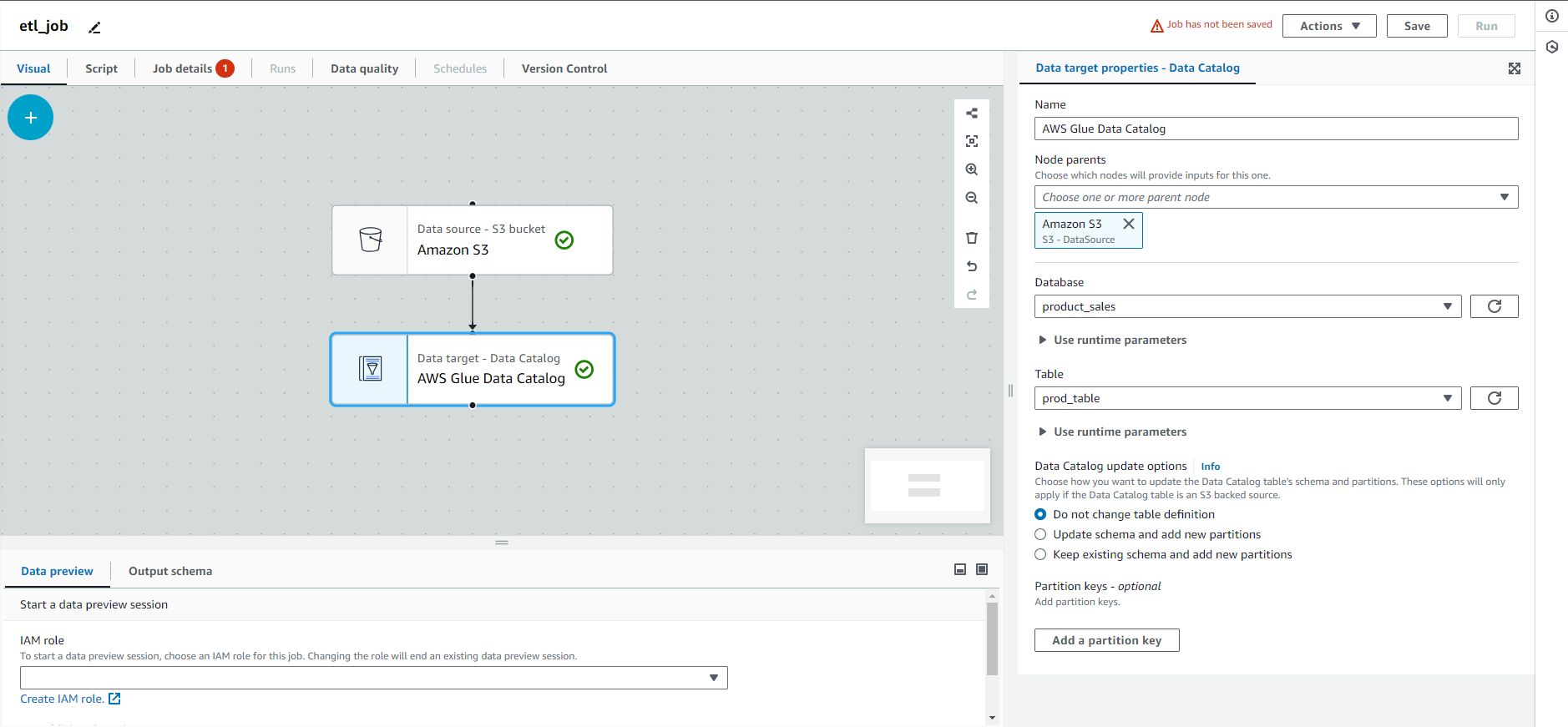
- At the bottom section, you will see Data Preview, where you need to select an IAM role with AWSGlueServiceRole.
- Once your ETL job is ready, save and Run. Glue will start processing the data according to the logic you’ve defined.
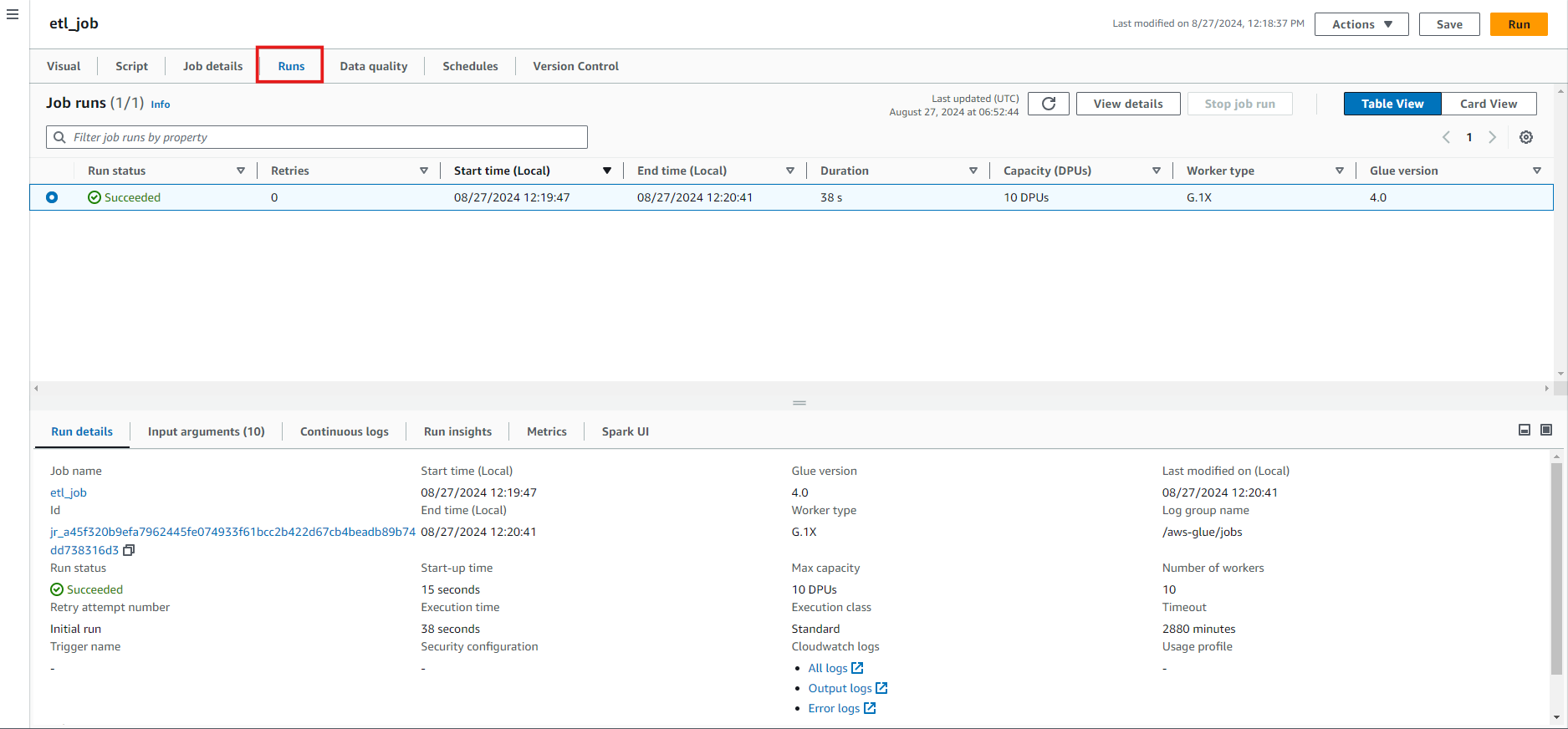
To check your Run Details, click on the “Runs” section. It should show “Succeeded.”
Step 5: Querying the Data with Athena (Optional)
If you want to query your transformed data, AWS Athena is a great tool. Athena allows you to run SQL queries directly on your data stored in S3.
- Navigate to the Athena service in your AWS Console.
- Set up a query using the database and table we created earlier in the Glue Data Catalog.
- Write and run your SQL query. For example, you might want to find the updated price of a product.
Athena is serverless, so there’s no need to manage any infrastructure. Plus, it integrates seamlessly with Glue, making it easy to query your data without any additional setup.
Limitations of Using AWS Glue and AWS S3
While AWS Glue and S3 make a powerful combo for building data pipelines, it’s important to be aware of some limitations:
- Learning Curve: AWS Glue, especially when working with custom transformations in PySpark, can have a steep learning curve if you’re new to data engineering. Although Glue provides a visual interface, more complex transformations often require you to write and debug Python scripts, which can be challenging for beginners.
- Cost Management: While AWS Glue and S3 are cost-effective for large-scale operations, the costs can add up, especially with frequent ETL jobs and large datasets. Monitoring and optimizing your Glue jobs is essential to avoid unexpected expenses.
- Latency: Since Glue is a fully managed service, there can be some latency when starting jobs. If you need real-time processing, Glue might not be the best fit. Other tools like AWS Kinesis might be more appropriate for near real-time or real-time data processing.
- Limited Customization: Although Glue is powerful, it might not offer the same level of customization as running your own ETL processes on EC2 instances or using other ETL tools. You might encounter limitations when performing very specific or highly customized data transformations.
- Data Catalog Limitations: While helpful, AWS Glue’s Data Catalog might not scale well with extremely large datasets or very complex schemas. Sometimes, you might need to manage metadata outside Glue for better performance or flexibility.
- Vendor Lock-In: As with any cloud service, relying heavily on AWS Glue and S3 can lead to vendor lock-in. While these services are robust and feature-rich, moving your data and ETL processes to another platform could be complex and time-consuming.
- Dependency on Network Performance: The performance of your Glue jobs and the interaction with S3 can be heavily dependent on network performance. Network bottlenecks could become a concern if you have large volumes of data and complex ETL processes.
Understanding these limitations will help you better plan and optimize your data pipelines, ensuring you make the most of AWS Glue and S3’s offerings.
To overcome these limitations, you can opt for Hevo.
How Hevo Can Overcome the Limitations of AWS Glue
- Simplified Schema Mapping
Challenge: Manual schema mapping in AWS Glue can be time-consuming and complex, especially when dealing with intricate or non-standard data formats.
Hevo’s Solution: Hevo provides an intuitive, user-friendly interface for schema mapping, which simplifies the process of defining how data fields should be transformed and loaded. With Hevo, you can easily map fields between your source and target systems without needing extensive manual configuration, making schema management more efficient and less error-prone. - Cost Management
Challenge: AWS Glue can incur high costs, particularly with frequent ETL jobs and large datasets.
Hevo’s Solution: Hevo offers a transparent and predictable pricing model to help you manage and optimize costs better. Its efficient data processing and streamlined integration capabilities can reduce the overall expenses of managing and transforming data. - Real-Time Data Processing
Challenge: AWS Glue can experience latency in job execution, which might not be suitable for real-time data processing needs.
Hevo’s Solution: Hevo supports real-time data replication and streaming, allowing you to process and analyze data as it arrives. This real-time capability ensures that you have up-to-date insights without the delays associated with batch processing. - Customization Flexibility
Challenge: AWS Glue might have limitations in customization for very specific or complex transformations.
Hevo’s Solution: Hevo provides greater flexibility in data transformations with its wide range of built-in connectors and transformation features. This flexibility allows you to handle complex data transformations and custom logic without the constraints of predefined schemas. - Scalability and Performance
Challenge: Managing performance and scalability with AWS Glue can become challenging as data volume grows.
Hevo’s Solution: Hevo is designed to scale effortlessly with your data needs. Its architecture ensures high performance even with large datasets, allowing you to handle increasing volumes of data efficiently without worrying about performance bottlenecks. - Ease of Use
Challenge: AWS Glue can have a steep learning curve, especially for users new to data engineering.
Hevo’s Solution: Hevo’s user-friendly interface and straightforward setup process make it easier for users of all skill levels to build and manage data pipelines. Its no-code platform enables quick deployment and management of data integrations without deep technical knowledge.


Connect AWS S3 with Hevo
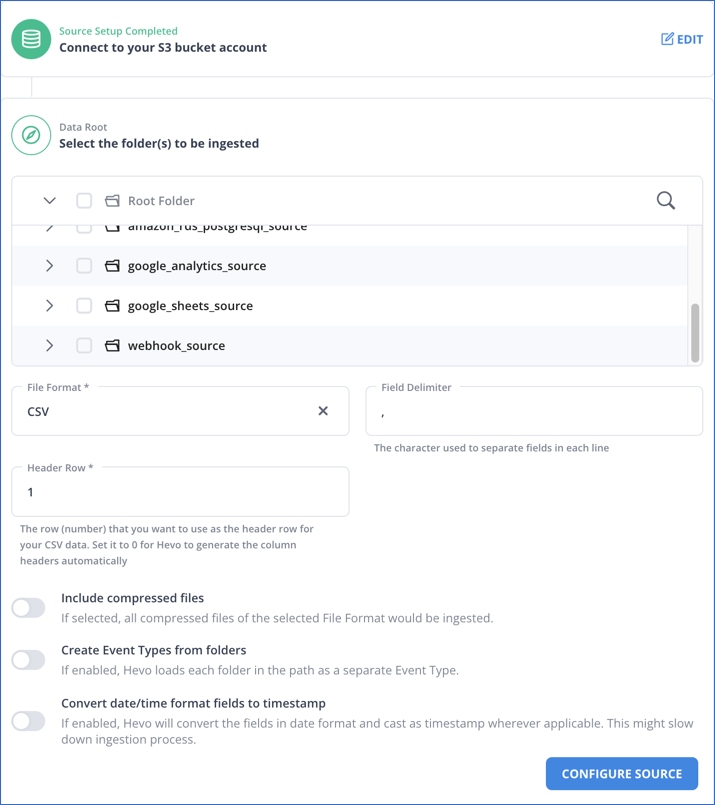
- After logging into your Hevo account, click on “Create Pipeline.”
- Search for Amazon S3 and click on it to configure it as your source.
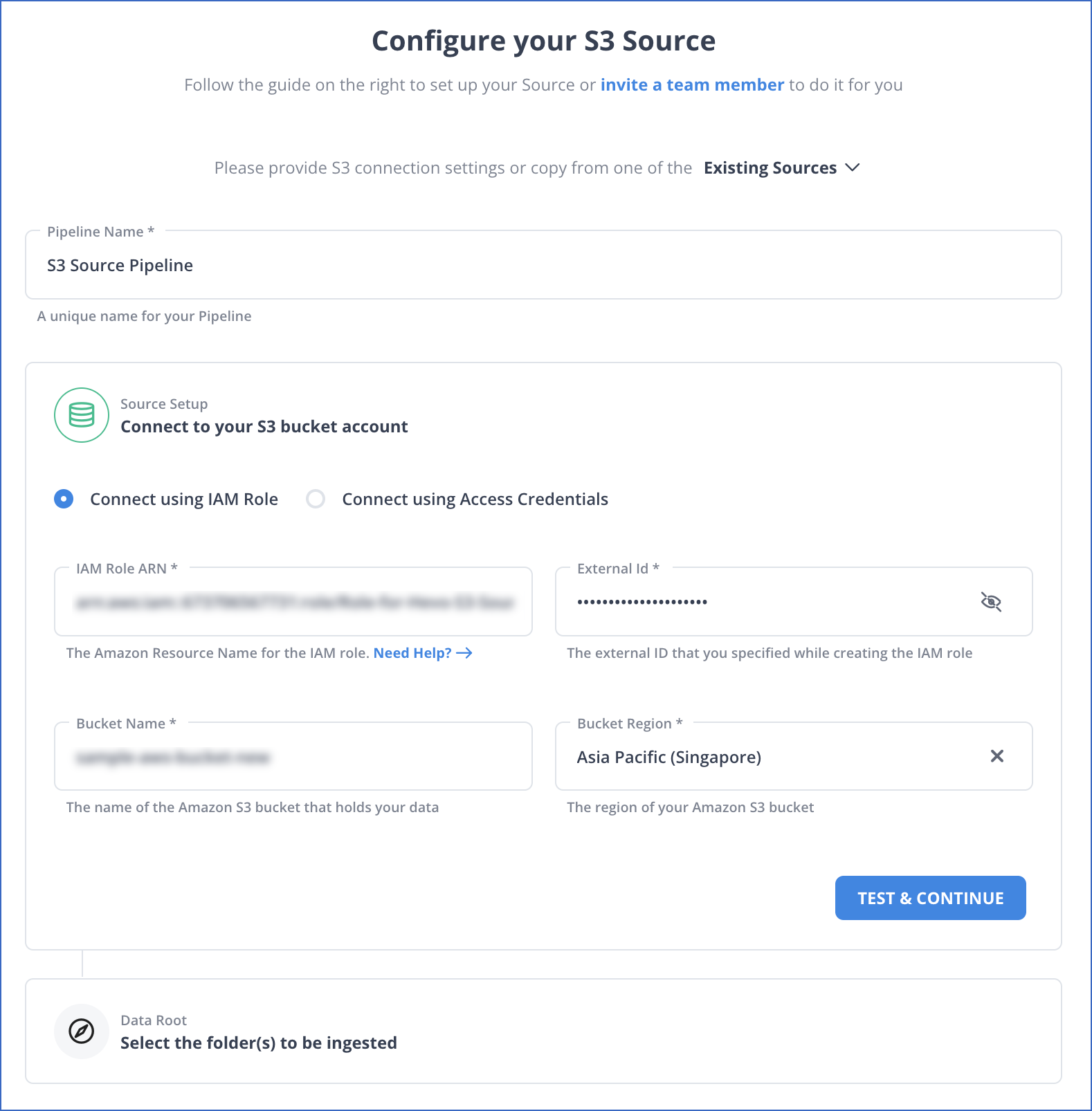
- Click on “Test & Continue,” select your files to be ingested, and click on “Configure Source.”
Wrapping Up
And there you have it! We’ve built a data pipeline from scratch using AWS Glue and AWS S3. Along the way, we’ve learned how to store data in S3, create a Glue Data Catalog, set up an ETL job, and even query the transformed data using Athena.
If you think AWS Glue is a bit complicated and would like to explore other options, check out Hevo for a free personalized demo.
FAQ on AWS Glue S3
Can AWS Glue connect to S3?
Yes, AWS Glue can connect to Amazon S3. It can read data from and write data to S3 buckets as part of its ETL workflows, making S3 a common source and destination for data processing.
What is the difference between S3 and Glue?
Amazon S3 is a scalable object storage service for storing and retrieving data. AWS Glue, on the other hand, is an ETL service that automates data preparation and transformation. Glue can use S3 as a data source or destination but performs complex data processing tasks beyond simple storage.
What is the purpose of AWS Glue?
AWS Glue is designed to simplify and automate the ETL process. It helps discover data, prepare it for analysis, and combine data from different sources. Glue automates data cataloging, transformation, and loading into data stores for analysis.
How to read an S3 file in AWS Glue?
You create a Glue job or crawler to read an S3 file in AWS Glue. Configure a source to point to the S3 bucket and file path for a job, then specify the data format and schema. The job can then extract the data from the S3 file for further processing or transformation.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





