

Building a data lake for reporting, analytics, and machine learning needs has become general practice.
Data lakes allow us to ingest data from multiple sources in their raw formats in real time. This will enable us to scale any data size and save time in defining its schema and transformations.
This blog describes a simpler way to build a data lake in Apache Iceberg with MySQL CDC.
Supercharge your data lakehouse with Hevo’s native Apache Iceberg integration—built for speed, flexibility, and efficiency.
Why Apache Iceberg?
- Blazing-Fast Queries – Hevo processes only the required data, reducing scan times.
- Schema & Partition Evolution – Modify your data structure without downtime.
- ACID Transactions & Time Travel – Ensure data consistency and access historical records instantly.
Build a scalable, high-performance data lakehouse with Hevo and Apache Iceberg. Try it free today.
Get Started with Hevo for FreeTable of Contents
What is CDC?

Change Data Capture is the process of identifying and capturing all the changes happening to data in the database and delivering these changes to the downstream system in real-time.
Why is it needed?
Capturing real-time transactions happening on source databases and moving them to the target system keeps the systems in sync and provides data replication and zero-downtime migrations.
In today’s modern cloud architectures, CDC is the most efficient way to move data across a wider network. As the CDC moves data in real time, it supports real-time data analytics, too.
Common use cases
- Syncing data from on-prem to cloud
- To build an audit log
- Real-time data loading to data warehouse
- In the telecommunication industry, organizations use CDC to capture network events and call details records.
How to Enable CDC in MySQL
CDC in MySQL is enabled by MySQL’s Binary Log. It’s like MySQL’s automatic recorder for all changes made to data, keeping a running log of every edit or update, hence for all data manipulation activities.
To enable binary log on the MySQL server, make the below changes in MySQL server configuration and restart the server.
[mysqld]
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
binlog-format = row
After running MySQL with the above config, we should see the following values set for log_bin and binlog_format.
What is the Apache Iceberg?
Apache Iceberg is an open table format for a huge size of datasets. This layer sits between your actual data files and the way they are organized to create a table structure.
Iceberg was designed by Netflix to solve data inconsistency and performance issues while using Hive. Hive scans data at the folder level, which includes costly file listing operations when working with data in the table, which degrades performance. Also, there can be missing file issues while listing files over eventually consistent object stores like S3.
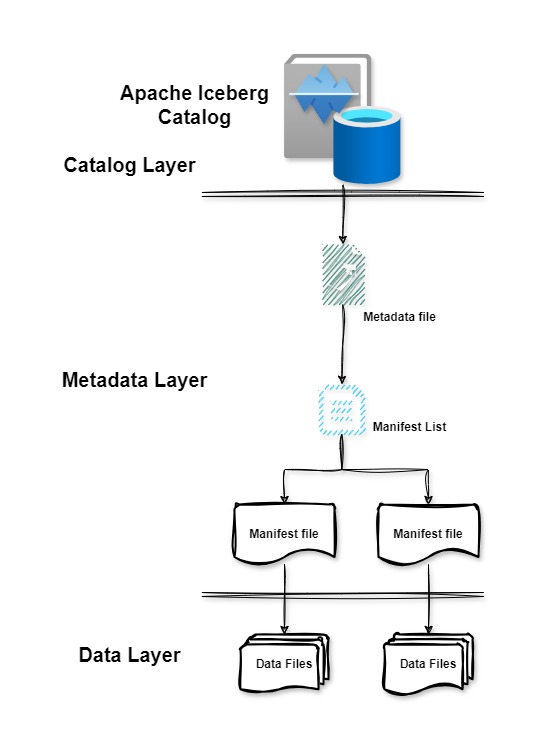
As shown in the above diagram, Iceberg avoids these issues by keeping track of all data files and not folders using metadata in manifest files. Its metadata contains information about schemas and partitions.
It provides ACID inserts and row-level updates and deletes.
Debezium Iceberg Consumer
Debezium is an open-source distributed platform for Change Data Capture, which extracts CDC transactions from the databases and delivers them to consumers.
Most of the time Debezium is used with Kafka and Kafka Connect. However, we can also use a Debezium server to cater to the need for other messaging systems like Apache Pulsar, Kinesis, RabbitMQ, etc. Here are the supported destinations.
Debezium provides SPI to implement new sink adapters as required and this is the extension point for creating Apache Iceberg Consumer. Apache Iceberg consumers will convert CDC to data files and commit them to the destination table using Java API. Each Debezium source topic is mapped to one Iceberg table.

Follow the instructions given on Debezium Server & Iceberg to build the Debezium server.
Steps to run Debezium-Server-Iceberg
- Clone the repo.
git clone https://github.com/memiiso/debezium-server-iceberg.git- Build it and unzip.
mvn -Passembly -Dmaven.test.skip package
Unzip debezium-server-iceberg-dist/target/debezium-server-iceberg-dist*.zip -d appdist
cd appdist- Edit the application.properties.Here is the configuration for using the Debezium server with the Iceberg Adapter in application.properties.
debezium.sink.type=iceberg
# run with append mode
debezium.sink.iceberg.upsert=false
debezium.sink.iceberg.upsert-keep-deletes=true
debezium.sink.iceberg.table-prefix=debeziumcdc_
debezium.sink.iceberg.table-namespace=debeziumevents
debezium.sink.iceberg.fs.defaultFS=s3a://S3_BUCKET);
debezium.sink.iceberg.warehouse=s3a://S3_BUCKET/iceberg_warehouse
debezium.sink.iceberg.type=hadoop
debezium.sink.iceberg.catalog-name=mycatalog
debezium.sink.iceberg.catalog-impl=org.apache.iceberg.hadoop.HadoopCatalog
# enable event schemas
debezium.format.value.schemas.enable=true
debezium.format.value=json
# complex nested data types are not supported, do event flattening. unwrap message!
debezium.transforms=unwrap
debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
debezium.transforms.unwrap.add.fields=op,table,source.ts_ms,db
debezium.transforms.unwrap.delete.handling.mode=rewrite
debezium.transforms.unwrap.drop.tombstones=true
# mysql source
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.offset.flush.interval.ms=0
debezium.source.database.hostname=localhost
debezium.source.database.port=3306
debezium.source.database.user=mysql
debezium.source.database.password=mysql
debezium.source.database.dbname=test
debezium.source.database.server.name=mysql80
debezium.source.database.server.id=1234
debezium.source.schema.include.list=employees
debezium.source.topic.prefix=dbz_
Before running the debezium server we will create database and table as follows.
CREATE DATABASE company;
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL
);
INSERT INTO orders (customer_id, order_date, total_amount) VALUES (1, '2023-01-15', 150.50);
INSERT INTO orders (customer_id, order_date, total_amount) VALUES (2, '2023-02-20', 200.00);
INSERT INTO orders (customer_id, order_date, total_amount) VALUES (3, '2023-03-25', 320.75);
INSERT INTO orders (customer_id, order_date, total_amount) VALUES (4, '2023-04-10', 450.00);
INSERT INTO orders (customer_id, order_date, total_amount) VALUES (5, '2023-05-05', 500.25);- Execute run.sh.
- We should see the output change logs in the configured s3 bucket for any change in the database. For e.g. for dropping employees’ table it will generate event as below.

- Output: We should see the parquet files generated for CDC.

Upsert Mode
By default, consumer runs with debezium.sink.iceberg.upsert set as true. It means whenever the record in the source table is updated, the destination table is also updated. If records are deleted, the changes will be propagated to the destination table. Hence Data is identical in both source and destination table.
For each update, the delete files are created using the primary key of the source table. This is the Iceberg equality delete feature. To avoid data deduplication, it is handled per batch, for example, if we have received multiple versions of the same records, only the last version of the record in a batch is stored in the Iceberg table.
Append Mode
By setting this debezium.sink.iceberg.upsert setting to false we can run the consumer in append mode. All received records are appended to Iceberg tables no data deduplication or deletion happens. It enabled us to audit all the changes that happened to the source table.
Additional Data Compaction
At this point, we’ve successfully loaded the raw data into our data lake, taking care of data deduplication and maintaining a near real-time pipeline. Now, creating curated or analytics layers on top of this raw data becomes straightforward.
We prepare the raw data in the analytics layer to meet specific analytical needs. This usually involves reorganizing, cleaning, versioning, aggregating the data, and applying business logic. We commonly use SQL and scalable processing engines to transform the data in this way. Here’s an example to show this process:
MERGE INTO dwh.orders t
USING (
-- new data to insert
SELECT order_id, customer_id, order_date, total_amount, TO_DATE('9999-12-31', 'yyyy-MM-dd') AS end_date
FROM debezium.orders
UNION ALL
-- update existing records to close the end_date
SELECT t.order_id, t.customer_id, t.order_date, t.total_amount, s.order_date AS end_date
FROM debezium.orders s
INNER JOIN dwh.orders t ON s.order_id = t.order_id AND t.current = true
) s
ON t.order_id = s.order_id AND t.order_date = s.order_date
-- close last records/versions
WHEN MATCHED THEN
UPDATE SET t.current = false, t.end_date = s.end_date
-- insert new versions and new data
WHEN NOT MATCHED THEN
INSERT (order_id, customer_id, order_date, total_amount, current, end_date)
VALUES (s.order_id, s.customer_id, s.order_date, s.total_amount, true, s.end_date);Additional layers in the data lake might require periodic updates with new data. The simplest method for this is to use SQL update or delete statements.
Conclusion
Building a data lake using MySQL Change Data Capture (CDC) and Apache Iceberg offers a streamlined and efficient approach for handling real-time data replication and analytics. CDC enables the capture of real-time transactions from MySQL, ensuring that the data lake is always in sync with the source database. Apache Iceberg provides a robust table format that addresses performance and data consistency issues, making it an ideal choice for large datasets.
By leveraging Debezium with Apache Iceberg via Debezium Server Iceberg, we can create a scalable data pipeline that avoids the complexity of traditional Kafka setups.
The ability to periodically update and maintain these layers with simple SQL commands further simplifies the data management process. This solution is still evolving, and contributions to improve its functionality are welcome. Ultimately, this approach facilitates the creation of a scalable, low-latency data lake that meets modern data processing and analytical needs.
Sign up for a 14-day free trial with Hevo to meet all your data integration needs.
FAQs
1. Is Debezium open source?
Debezium is an open-source project that provides a low-latency data streaming platform for change data capture (CDC).
2. When to use the iceberg table?
Iceberg is designed for use with substantial analytical data sets. It offers multiple features designed to increase querying speed and efficiency.
3. Why is Iceberg better than Hive?
Apache Iceberg is an open table format designed with modern cloud infrastructure. It was created at Netflix to overcome the limitations of Apache Hive and includes key features like efficient updates and deletes, snapshot isolation, and partitioning.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




