
In today’s information era, companies collect tons of data online. Whether your task is to scrape data from the internet, conduct statistical analyses, or create dashboards and visualizations, you’ll have to manipulate the raw information in some way to create useful data. And that’s where Data Wrangling comes in.
Data Wrangling is the process of transforming raw data into formats that are easier to use. It’s a prerequisite for successful data analysis and involves six distinct steps that we’re going to look at below. When done right, data wrangling will help you properly and efficiently analyze data so you can make good business decisions.
Table of Contents
What is Data Wrangling?
Data Wrangling is the process of cleaning, organizing, structuring, and enriching the raw data to make it more useful for analysis and visualization purposes. With more unstructured data, it is essential to perform Data Wrangling for making smarter and more accurate business decisions. Data Wrangling usually involves manually converting and mapping data from its raw state to another format that can be used for business purposes and is convenient for the consumption and organization of the data.
With Hevo, transform and integrate data from multiple sources into your data warehouse, streamlining data wrangling processes to deliver clean, analysis-ready datasets.
Why Use Hevo for Data Wrangling and Warehouse Integration?
- Seamless Transformation: Automatically clean, enrich, and transform raw data into a consistent format using Hevo’s built-in transformation features.
- Broad Source and Destination Support: Connect to over 150+ sources, including databases, SaaS applications, and more, and load clean data into your preferred data warehouse.
- Real-Time Data Sync: Ensure your data wrangling workflows and warehouse stay aligned with up-to-date data for timely insights.
- No-Code Platform: Simplify complex data wrangling tasks with Hevo’s intuitive, no-code interface no technical expertise needed!
What are the Benefits of Data Wrangling?
Data professionals spend as much as 80% of their time in the data-wrangling process.
Only 20% is spent on exploration and Marketing, which begs the question “Is Data Wrangling worth the effort?“
Well, considering the many benefits Data Wrangling provides, it’s certainly worth putting in the time.
Here are some of the benefits Data Wrangling offers your business:
- Easy Analysis: Once raw data is wrangled and transformed, Business Analysts and Stakeholders are empowered to analyze the most complex data quickly, easily, and efficiently.
- Simple Data Handling: The Data Wrangling process transforms raw, unstructured, messy data into usable data arranged in neat rows and columns. The process also enriches the data to make it more meaningful and provide deeper intelligence.
Better Targeting: When you’re able to combine multiple sources of data, you can better understand your audience which leads to improved targeting for your Ad Campaigns and Content Strategy. Whether you’re trying to run Webinars to showcase what your company does for your desired customers, or use an online course platform to develop a training course for your own company, having the proper data to understand your audience is crucial to your success. - Efficient Use of Time: The Data Wrangling process allows analysts to spend less time struggling to organize unruly data and more time on getting insights to help them make informed decisions based on data that is easy to read and digest.
- Clear Visualization of Data: Once the data is wrangled, you can easily export it to any Analytics Visual Platform of your choice so you can begin to summarize, sort, and analyze the data.
What are the Steps to Perform Data Wrangling?
Below, we are going to take a look at the six-step process for data wrangling, which includes everything required to make raw data usable.

Step 1: Data Discovery
The first step in the Data Wrangling process is Discovery. This is an all-encompassing term for understanding or getting familiar with your data. You must take a look at the data you have and think about how you would like it organized to make it easier to consume and analyze.
So, you begin with an Unruly Crowd of Data collected from multiple sources in a wide range of formats. At this stage, the goal is to compile the Disparate, Siloed data sources and configure each of them so they can be understood and examined to find patterns and trends in the data.
Step 2: Data Structuring
When raw data is collected, it’s in a wide range of formats and sizes. It has no definite structure, which means that it lacks an existing model and is completely disorganized. It needs to be restructured to fit in with the Analytical Model deployed by your business, and giving it a structure allows for better analysis.
Unstructured data is often text-heavy and contains things such as Dates, Numbers, ID codes, etc. At this stage of the Data Wrangling process, the dataset needs to be parsed.
This is a process whereby relevant information is extracted from fresh data. For example, if you are dealing with code scrapped from a website, you might parse HTML code, pull out what you need, and discard the rest.
This will result in a more user-friendly spreadsheet that contains useful data with columns, classes, headings, and so on.
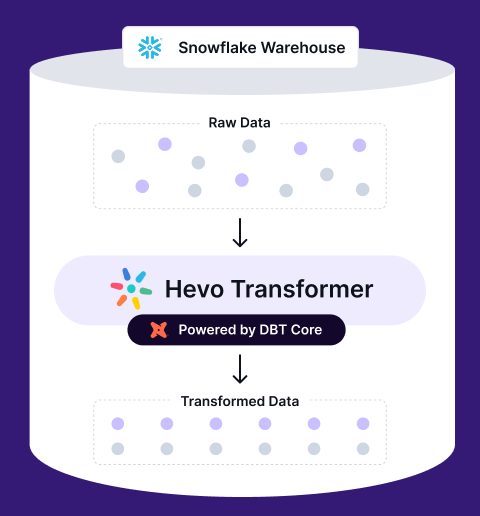
Easily manage and transform your data on Snowflake with Hevo Transformer—automate dbt workflows, track versions via Git, and validate in real time.
- Quick Data Integration – Connect your warehouse in a snap and auto-fetch tables
- No-Hassle dbt Automation – Build, test, and deploy with ease
- Version Control with Git – Track changes effortlessly with Git integration
- Instant Data Transformation – Preview and push changes instantly
Step 3: Data Cleaning
Most people use the words Data Wrangling and Data Cleaning interchangeably. However, these are two very different processes. Although a complex process in itself, Cleaning is just a single aspect of the overall Data Wrangling process.
For the most part, raw data comes with a lot of errors that have to be cleaned before the data can move on to the next stage. Data Cleaning involves Tackling Outliers, Making Corrections, Deleting Bad Data completely, etc. This is done by applying algorithms to tidy up and sanitize the dataset.
Cleaning the data does the following:
- It removes outliers from your dataset that can potentially skew your results when analyzing the data.
- It changes any null values and standardizes the data format to improve quality and consistency.
- It identifies duplicate values and standardizes systems of measurements, fixes structural errors and typos, and validates the data to make it easier to handle.
You can automate different algorithmic tasks using a variety of tools such as Python and R (more on that later).
Step 4: Data Enriching
At this stage of the Data Wrangling process, you’ve become familiar with, and have a deep understanding of the data at hand.
Now the question is, do you want to embellish or enrich the data? Do you want it augmented with other data?
Combining your raw data with additional data from other sources such as internal systems, third-party providers, etc. will help you accumulate even more data points to improve the accuracy of your analysis. Alternatively, your goal might be to simply fill in gaps in the data. For instance, combining two databases of customer information where one contains customer addresses, and the other one doesn’t.
Enriching the data is an optional step that you only need to take if your current data doesn’t meet your requirements.
Step 5: Data Validating
Validating the data is an activity that services any issues in the quality of your data so they can be addressed with the appropriate transformations.
The rules of data validation require repetitive programming processes that help to verify the following:
- Quality
- Consistency
- Accuracy
- Security
- Authenticity
This is done by checking things such as whether the fields in the datasets are accurate, and if attributes are normally distributed. Preprogrammed scripts are used to compare the data’s attributes with defined rules.
This is a great example of the overlap that sometimes happens between Data Cleaning and Data Wrangling – Validation is the Key to Both.
This process may need to be repeated several times since you are likely to find errors.
Step 6: Data Publishing
By this time, all the steps are completed and the data is ready for analytics. All that’s left is to publish the newly Wrangled Data in a place where it can be easily accessed and used by you and other stakeholders.
You can deposit the data into a new architecture or database. As long as you completed the other processes correctly, the final output of your efforts will be high-quality data that you use to gain insights, create business reports, and more.
You might even further process the data to create larger and more complex data structures such as Data Warehouses. At this point, the possibilities are endless.
What are the Best Practices for Data Wrangling?
Data Wrangling can be performed in a variety of ways. But, there are several tools that can help to facilitate the process. Depending on Who the data is presented for (an individual, organization, etc.), the specific Data-Wrangling approach can vary.
- For instance, an online store owner might want to simply organize the data into a form that is easy for them to understand.
- On the other hand, a professional in a large-scale consulting firm might require the Wrangled Data to be presented more comprehensively so they can glean deeper insights from it.
Regardless of your data-wrangling objectives, some best practices apply in every case. I’ve listed some of them below:
1. Understand Your Audience
As previously stated, specific goals or needs for data wrangling can vary by organization. But, what’s important is knowing who will access and interpret that data, as well as what they hope to achieve, so you can include all the relevant information to help them get those insights.
For instance, if multiple stakeholders make it clear that the company will begin to use Webinar Software to drive more leads, it would make sense to make a view from within the data that gives them all demographic information about current customers so that the Marketing team understands who to target in their promotional material.
2. Pick the Right Data
As any analyst will tell you, it’s not about having lots of data, it’s about having the Right Kind of data.
That’s why Data Selection is so important. It will help you pick the data that is required right now for a specific purpose, as well as make it easier to find the data later should a similar need arise.
Here are some tips for picking the right data:
- Avoid data with many nulls, same, or repeated values.
- Steer clear of Derived or Calculated values and choose ones close to the source.
- Extract data across a variety of platforms.
- Filter the data to choose a subject that meets the conditions and rules.
3. Understand the Data
This is a very important part of assessing the quality and accuracy of your data. You must be able to see how the data fits within the governance rules and policies of your organization. When you understand the data you’ll be able to determine the right level of quality to suit the data’s purpose.
Here are some key points to remember:
- Learn the data, database, and file formats.
- Utilize visualization capabilities to explore the current state of the data.
- Make use of profiling to generate Data Quality Metrics.
- Be aware of the data’s limitations.
4. Reevaluate Your Work
Although a business may have strict instructions for Data Wrangling, professionals may notice room for improvement upon completion of the process. Furthermore, the Wrangler may come across operations errors.
After completing the project, it’s a good idea to reevaluate the Wrangled Data to ensure that it is of the highest quality and organized as efficiently as possible. This will help to reduce inefficiencies and errors in the future.
5. Learn More About Data
For successful Data Wrangling to take place, analysts must have a firm grasp of the full scope of the resources and tools at their disposal. They must also have an in-depth understanding of the audience for whom they are wrangling the data.
Since the audience may grow, and the different tools and services may expand, data professionals need to adapt to these changes and stay up-to-date on breakthroughs and new technologies in analytics so they are always ready to provide effective data wrangling services.
What are the Use Cases of Data Wrangling?
Some of the common use cases of Data Wrangling are listed below:
1. Financial Insights
Data Wrangling is widely used by financial institutions to discover the insights hidden in data and uncover the numbers to predict trends and forecast the markets. It helps in answering the questions to make informed investment decisions.
2. Improved Reporting
Various departments in an organization need to generate reports of their activities or to get some specific information. But it becomes difficult to create reports with unstructured data. Data Wrangling improves the data quality and helps in fitting information in the reports.
3. Unified Format
Different departments of the company use different systems to capture the data which is in different formats. Data Wrangling helps in unifying the data and transforms data into a single format to get a holistic view.
4. Understanding Customer Base
Each customer has different personal data and behavior data. Using Data Wrangling, you can identify the patterns in the data and similarities between different customers.
5. Data Quality
Data Wrangling greatly helps in improving the quality of data. Data is an essential need of every industry to derive insights from it and make better data-driven business decisions.
6. Better Decision-Making and Communication
Data wrangling software has Improved accuracy and clarity and cut down on the time it takes for others to comprehend and analyze data, which promotes greater team understanding and communication. Better decisions, more cooperation, and transparency may result from this advantage.
Tools and Techniques for Data Wrangling
What tools do Data Wranglers use? There are tons of tools and techniques for Data Wrangling professionals to choose from, including Programming Languages, Software, and Open-Source Data Analytics platforms.
The tools you choose will depend on your needs for:
- Processing and organizing data
- Cleaning and consolidating
- Extracting insights from data
Some tools facilitate data Processing while others help to make data more organized and easier to consume and interpret. Yet others offer all-in-one Data Wrangling solutions. You must choose the best tool that will help you Wrangle Data efficiently to benefit your organization.
Here’s a list of Data Wrangling tools that will help you uncover valuable insights from raw information:
- Python and R
- MS Excel
- KNIME
- Excel Spreadsheets
- OpenRefine
- Tabula
- CSVKit
- PythonPandas
- Plotly
- Dplyr
- Purrr
- Splitstackshape
- JSOnline
You’ll also find some Visual Data Wrangling tools like OpenRefine and Trifecta that are designed for beginners. Such tools aim to make it easier for non-programmers to Wrangle Data. They can also help experienced data professionals by speeding up the process.
A word of caution about these tools: Although these visual tools are more intuitive and effective for helping you transform your data into well-structured formats, they are also less flexible. Since their functionality is more generic, they don’t always perform as well when dealing with complex datasets.
Explore our guide on data wrangling tools to find the best tools for cleaning and preparing your data for analysis.
Conclusion
This is the end of this article on the Six Steps for Data Wrangling. Use it as a guide to help you create useful data so end-users like Data Analysts, Engineers, Data Scientists, and other stakeholders can glean actionable insights from all the information you collect.
Curious about data wrangling vs ETL? Discover the key differences in our detailed guide to enhance your data strategy.
Extracting complex data from a diverse set of data sources to carry out an insightful analysis can be challenging, and this is where Hevo saves the day! Optimize your data operations with OAC. Learn how seamless integration and intuitive tools can make data management easier.
Hevo Data offers a faster way to move data from Databases or SaaS applications to be visualized in a BI tool for free. Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs.
Want to take Hevo for a spin? Sign Up for the 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
FAQ
What is Data Wrangling?
Data wrangling is the process of cleaning, organizing, and transforming raw data into a usable format for analysis. It ensures data quality by handling inconsistencies, gaps, and errors for effective decision-making.
What are the Six Steps of Data Wrangling?
Discovery: Explore and understand data sources, formats, and attributes to identify patterns or potential issues.
Structuring: Reorganize raw data into a defined format suitable for analysis or integration tasks.
Cleaning: Remove duplicates, handle missing values, and correct errors to ensure consistency and accuracy.
Enriching: Combine datasets, add derived values, or include external data to enhance the dataset’s value.
Validating: Verify data correctness and consistency by applying validation rules and resolving discrepancies.
Publishing: Prepare and deliver the wrangled data for analysis, storage, or further processing.
What is Data Wrangling vs. ETL?
Data wrangling is a manual or semi-automated process focused on preparing data for immediate analysis. ETL (Extract, Transform, Load) is a structured pipeline for moving, transforming, and storing data in target systems.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





