
BigQuery is a Google Data Warehouse with built-in Geographic Data Intake, Storage, and Analysis tools. To handle complex data and examine massive datasets, it uses ordinary SQL Queries. Google DataStore is a highly scalable NoSQL Database that can be leveraged for your mobile and web applications. DataStore can tackle replication and sharding. This helps provide you with a highly durable and available database that can scale automatically to handle the requisite application load. Firestore is the next upgrade to DataStore.
Are you looking for simple ways to set up DataStore BigQuery migration? Seems like you’ve found your way to the right place. Today, we are going to talk about two easy methods to load data from DataStore to BigQuery. However, before discussing the steps in detail, let’s provide you with a primer on each.
Now, without further ado, let’s dive into the rest of the article!
Table of Contents
What is Google BigQuery?

Google BigQuery was developed as a flexible, fast, and powerful Data Warehouse that’s tightly integrated with the other services offered by the Google Platform. It offers user-based pricing, is cost-efficient, and has a Serverless Model. Google BigQuery’s Analytics and Data Warehouse platform leverages a built-in Query Engine on top of the Serverless Model that allows it to process terabytes of data in seconds.
Google BigQuery’s column-based storage service provided impetus for the data warehouse’s speed and ability to handle huge volumes of data. Since Column-based Storage allows you to process only the columns of interest, it enables you to obtain faster answers and use resources more efficiently. Therefore, for analytical databases, it is more beneficial to store data by column.
Key Features of Google BigQuery
Here are a few key features of Google BigQuery:
- Serverless Service: Generally, in a data warehouse environment, organizations need to commit and specify the server hardware on which computations will run. Administrators then have to provision for performance, reliability, elasticity, and security. A Serverless Model helps overcome this constraint. In a Serverless Model, the processing is automatically distributed across a large number of machines working in parallel. By using Google BigQuery’s Serverless model, Database Administrators, and Data Engineers focus less on infrastructure and more on provisioning servers. This allows them to gain more valuable insights from data.
- SQL and Programming Language Support: Users can access Google BigQuery through Standard SQL. Apart from this, Google BigQuery also has client libraries for writing applications that access data using Python, C#, Java, PHP, Node.js, Ruby and Go.
- Tree Architecture: Google BigQuery and Dremel can easily scale to thousands of machines by structuring computations as an Execution Tree. A Root Server obtains incoming queries and relays them to branches called Mixers. These branches then modify the incoming queries and deliver them to Leaf Nodes, also known as Slots. The Leaf Nodes then take care of filtering and reading the data while working in parallel. The results are moved back down the tree, followed by Mixers accumulating the results and finally sending them to the root as the answer to the query.
- Multiple Data Types: Google BigQuery offers support for a vast array of data types, including strings, numeric, boolean, struct, array, and a few more.
- Security: Data in Google BigQuery is automatically encrypted either in transit or at rest. Google BigQuery can also isolate jobs and handle security for multi-tenant activity. Since Google BigQuery is integrated with other GCP products’ security features, organizations can take a holistic view of Data Security. It also allows users to share datasets using Google Cloud Identity and Access Management (IAM). Administrators can establish permissions for individuals and groups to access tables, views, and datasets.
Hevo Data is a No-code Data Pipeline that offers a fully managed solution to set up data integration from 150+ Sources(including 50+ Free Data Sources) and will let you directly load data to a Data Warehouse like Google BigQuery or the destination of your choice. Let’s look at some of Hevo’s salient features.
- Data Transformation: It provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Real-Time: Hevo offers real-time data migration. So, your data is always ready for analysis.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
What is Google DataStore?

Google DataStore provides its users with a vast array of capabilities like indexes, SQL-like queries, ACID transactions, and much more. Google DataStore’s RESTful interface allows data to be easily accessed via any deployment target. It also allows you to build solutions that span across Compute Engine and App Engine while relying on Google DataStore as the point of integration.
With Google DataStore, you can focus on unfolding your applications without having to worry about Load Anticipation and Provisioning. Since Google DataStore scales automatically and seamlessly with your data, it allows applications to maintain high performance while handling high traffic. Google DataStore is a Schemaless Database, so it allows you to worry less about making changes to your underlying data structure alongside the evolution of your application.
Key Features of Google DataStore
Here are a few key features of Google DataStore:
- Fully Managed: Google DataStore is fully managed; therefore, it can automatically handle replication and sharding to offer a highly consistent database.
- Diverse Access Methods: You can access your data through Google DataStore’s JSON API and ORMs like NDB and Objectify, which are meticulously maintained by the Google DataStore community or open-source clients.
- Rich Admin Dashboard: Google DataStore allows you to query your database, view entry statistics, back up or restore your data, and view indexes.
- Multiple Data Types: Google DataStore provides support for a large variety of data types. This includes customary data types like Strings, Integers, Floating-point Numbers, Binary Data, and Dates, among others.
- ACID Transactions: You can easily ensure the integrity of your data by carrying out multiple datastore operations in a single transaction armed with ACID characteristics. Due to this, either all the grouped transactions will succeed or all of them will fail.
How to Export Data from DataStore to Google BigQuery?
Google BigQuery supports loading data from Google DataStore exports. These exports can be created through the Datastore-managed Export and Import Service.
You can even use the managed export and import service to migrate DataStore components into a Cloud Storage bucket. These exported components can then be loaded into Google BigQuery in a tabular format.
You can decide which properties you wish to load for transferring data from DataStore to BigQuery by either using the –projection_fields flag in the bq command-line tool or by setting the ‘projectionFields’ property in the API.
Here are the ways you can follow to migrate data from Google DataStore to BigQuery:
- DataStore to BigQuery: Loading DataStore Export Service into BigQuery
- DataStore to BigQuery: Appending/Overwriting DataStore Data into an Existing Table
DataStore to BigQuery: Loading DataStore Export Service into BigQuery
There are two primary ways in which you can load the Google DataStore export service into Google BigQuery: using the Google Cloud Console or the bq command line. In this section, you will be taking a look at both the methods for this DataStore to BigQuery migration step.
Method 1: Using Console
- Step 1: Go to the Google Cloud Console page and open up Google BigQuery. From the Explorer Panel, you can expand your project and supply a dataset.
- Step 2: Next, expand the Actions option from the menu and click on Open.
- Step 3: The previous step brings you to the Details panel in Google Cloud Console. Here, click on the Create Table button (it resembles a plus sign). This will open up a Create Table page for you.
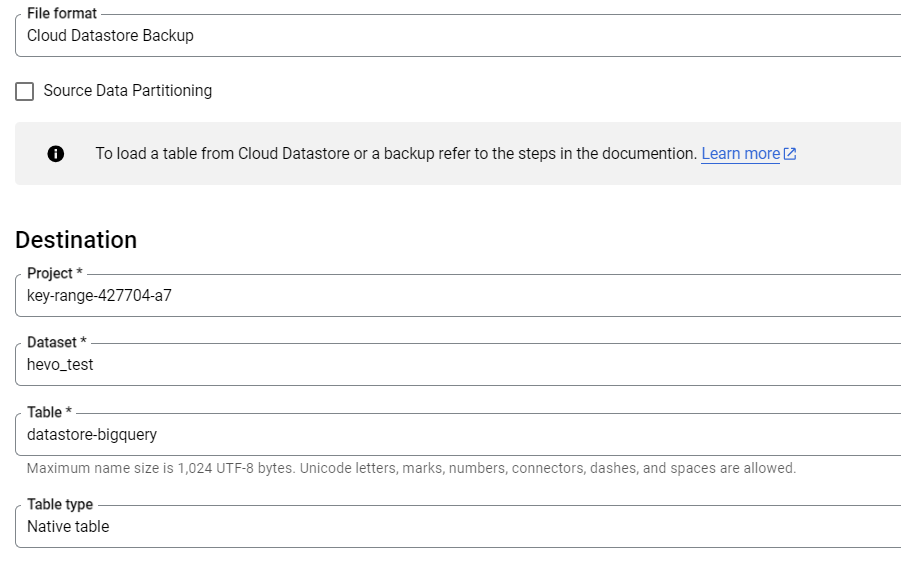
- Step 4: On the Create Table page, you need to change three parameters in the Source section.
- For the Create Table From parameter, opt for Cloud Storage.
- Enter the Cloud Storage URI in the source field. You need to make sure that the Cloud Storage bucket is in the same place as the dataset that consists of the table you’re creating. Remember that the URI for your Google DataStore export file should end with [KIND_NAME].export_metadata or export[NUM].export_metadata.
- Choose Datastore Backup for the File Format, and you’re done setting the parameters for the source section.

- Step 5: On the Create Table page, you also need to change three parameters in the Destination section.
- First, you need to choose the correct dataset for the Dataset Name.
- Enter the name of the table you’re creating in Google BigQuery in the Table Name field.
- Finally, you need to verify that the Table Type has been set to Native Table.
- Step 6: You don’t need to do anything in the Schema section as the schema has been taken from the Google DataStore export. Select the applicable items mentioned in the Advanced options section and then click on the Create Table option.
Method 2: Using bq Command Line
Here, you need to use the bq load command. Set the source_format to DATASTORE_BACKUP and provide the –location flag while setting the value to your location.
bq --location=LOCATION load
--source_format=FORMAT
DATASET.TABLE
PATH_TO_SOURCEYou need to replace the following fields in this DataStore to BigQuery migration step:
- FORMAT: This field needs to be set to DATASTORE_BACKUP.
- TABLE: This field refers to the table where the Google DataStore data is getting exported. In case this table does not exist, it gets created.
- DATASET: This field consists of the table where you’re loading your Google DataStore data.
- PATH_TO_SOURCE: This field refers to the Cloud Storage URI.
Here is an example after replacing the fields for DataStore to BigQuery migration:
bq --location=US load
--source_format=DATASTORE_BACKUP
mydataset.book_data
gs://mybucket/20180228T1256/default_namespace/kind_Book/default_namespace_kind_Book.export_metadata


DataStore to BigQuery: Appending/Overwriting DataStore Data into an Existing Table
There are two primary ways in which you can overwrite/append the Google DataStore data into an existing Google BigQuery table: using the Google Cloud Console or the bq command line. In this section, you will be taking a look at both the methods for this DataStore to BigQuery migration step.
Method 1: Using Console
- Step 1: Go to the Google Cloud Console page, and open up Google BigQuery. From the Explorer Panel, you can expand your project and supply a dataset.
- Step 2: Next, expand the Actions option from the menu and click Open.
- Step 3: The previous step brings you to the Details panel in Google Cloud Console. Here, click on the Create Table button (it resembles a plus sign). This will open up a Create Table page for you.
- Step 4: On the Create Table page, you need to change three parameters in the Source section.
- For the Create Table From parameter, you can opt for Cloud Storage. Then, enter the Cloud Storage URI in the source field.
- You need to make sure that the Cloud Storage bucket is in the same place as the dataset that consists of the table you’re creating.
- You need to keep in mind that the URI for your Google DataStore Export File should end with [KIND_NAME].export_metadata or export[NUM].export_metadata.
- Choose Datastore Backup for the File Format and you’re done with setting the parameters for the source section.
- Step 5: On the Create Table page, you also need to change three parameters in the Destination section.
- First, you need to choose the correct dataset for the dataset name.
- Enter the name of the table you’re creating in Google BigQuery in the Table name field.
- Finally, you need to verify that the Table Type has been set to Native Table.
- Step 6: You don’t need to do anything in the Schema section since the schema has been taken from the Google DataStore export. Choose Overwrite Table for Write Preference in the Advanced options section.

Method 2: Using bq Command Line
Here for this step in DataStore to BigQuery migration, you need to use the bq load command coupled with the –replace flag. Set the source_format to DATASTORE_BACKUP and provide the –location flag while setting the value to your location.
bq --location=LOCATION load
--source_format=FORMAT
--replace
DATASET.TABLE
PATH_TO_SOURCEYou need to replace the following fields in this DataStore to BigQuery migration step:
- FORMAT: This field needs to be set to DATASTORE_BACKUP.
- TABLE: This field refers to the table that is being overwritten.
- DATASET: This field represents the table where you’re loading your Google DataStore data.
- PATH_TO_SOURCE: This field refers to the Cloud Storage URI.
Here is an example demonstrating this DataStore to BigQuery migration step:
bq load --source_format=DATASTORE_BACKUP
--replace
mydataset.book_data
gs://mybucket/20180228T1256/default_namespace/kind_Book/default_namespace_kind_Book.export_metadataLimitations of Loading Data from a DataStore Export
Here are a few limitations you should keep in mind when loading data from a DataStore export for DataStore to BigQuery migration:
- You can mention only one Cloud Storage URI when loading data from DataStore exports.
- You cannot use a wildcard in the Cloud Storage URI while mentioning a Google DataStore export file for DataStore to BigQuery migration.
- The highest field size for Google DataStore exports is 64 KB. If you try loading a Google DataStore export field that is larger than 64 KB it gets truncated.
- Google DataStore doesn’t allow you to append DataStore export data to an existing table that has a defined schema.
- Components in the Google DataStore need to share a consistent schema with less than 10,000 unique property names for a Google DataStore export to correctly load.
- If an entry filter has not been mentioned for the exported data, it won’t be loaded into Google BigQuery. The export request needs to include one or more kind names in the entity filter for DataStore to BigQuery migration.
Conclusion
This blog discusses the steps you can follow to seamlessly integrate DataStore to BigQuery after a brief introduction to Google DataStore and Google BigQuery. It also discusses the limitations of loading data from a DataStore export to BigQuery.
Hevo Data provides its users with a simpler platform for integrating data from 150+ sources (including 50+ Free Sources) for Analysis. It is a No-code Data Pipeline that can help you combine data from multiple sources. You can use it to transfer data from multiple data sources into your Data Warehouse, Database, or a destination of your choice like Google BigQuery. It provides you with a consistent and reliable solution to managing data in real-time, ensuring that you always have Analysis-ready data in your desired destination.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. You can also have a look at our unbeatable pricing that will help you choose the right plan for your business needs!
FAQ on DataStore to BigQuery
1. What is Google Datastore used for?
Google Datastore is a NoSQL document database service provided by Google Cloud Platform. It is designed for storing, managing, and querying semi-structured data. Datastore is used primarily for:
– Application Data
– Content Management
– Meta Data Storage
2. Is BigQuery a database or data warehouse?
BigQuery is primarily categorized as a data warehouse rather than a traditional database. Here’s why:
– Analytics and Querying
– Columnar Storage
– Scalability
– Storage and Compute
3. Is BigQuery a data store?
While BigQuery is primarily a data warehouse designed for analytical queries and data processing, it does provide some characteristics of a data store:
– Storage of Data
– Data Formats
– Data Lifecycle Management
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




