

It is essential to keep track of the modifications in data at the source to create a single source of truth with centralization. However, updating and adding data to the target table is not straightforward. It often requires big data tools to scan billions of records to track changes and transform the data. Consequently, organizations use dbt to expedite determining the changes to transform the data. One of the best features of dbt is that it helps transform the data within the data warehouse. In this article, you will learn about dbt Incremental BigQuery model and transformations.
Table of Contents
What is dbt?
dbt is a command-line tool that allows analysts and engineers to transform data in the data warehouse by simple SQL queries. The ETL Transform step is just an area of focus; so it gives clean, structured, and organized data without having to deal with extraction or loading processes. It also allows versioning, testing, and documentation of the transformations of data in which makes data work more efficient and reliable. Over 280 companies, such as The Telegraph, currently employ dbt in production to simplify their data operations.
Struggling with manual SQL and scattered workflows? Hevo Transformer, powered by dbt Core™, lets you connect to a warehouse in minutes, automate dbt workflows, and collaborate effortlessly with Git version control.
- Quick Data Integration – Connect your warehouse in a snap and auto-fetch tables
- No-Hassle dbt Automation – Build, test, and deploy with ease
- Version Control with Git – Track changes effortlessly with Git integration
- Instant Data Transformation – Preview and push changes instantly
Types of Transformation in dbt
Businesses can transform data and make it accessible to downstream processes by using various data-handling tools in the market. However, dbt makes data transformation simple and fast. dbt is an open-source command line tool often used by data engineers to transform data in warehouses effectively.
With dbt transformation, you have the option to choose how dbt models are materialized. Materialization is just a strategy for data models in the data warehouse. And data models in dbt are SQL SELECT statements that are used to run the query for transformation.
- Table: When materialization is set to table, it runs the transformation once. As a result, the downstream process will have stale transformation data until the dbt model is refreshed.
- View: When materialization is to view, it updates the transformation as the data keeps changing. As a result, the downstream process will always have near real-time data.
- Incremental: When materialization is set to incremental, dbt keeps updating the row-level data to update the target table. As a result, this transformation allows updated data to the downstream processes.
- Ephemeral: When materialization is set to ephemeral, the model interpolates code with another dependent model as a common table expression. Since it can get complex, it is advised to use lightweight transformation with ephemeral.
Incremental Models
Incremental models allow dbt to insert or update records into a target table without leaving the data warehouse. It is usually embraced while working with event-style data. With incremental models, businesses can reduce the build time by transforming new/updated data, where only the latest records will be processed. Based on the complexity and volume of data, updating or appending with incremental models can be processed in a few seconds or minutes.
Suppose a company has a source database consisting of 1 billion records. Any change in the source data would require hours to append or update the target table. This is because the entire data is scanned. However, companies can index and transform only the changed rows using the incremental model to save computational time and resources.
Building an Incremental Model using dbt and BigQuery
Businesses often use dbt with incremental models to either append or update data into tables. Businesses often use dbt with incremental models to append or update data into tables. It reduces the cost of scanning hundreds of GB or TB. To avoid scanning such vast volumes of data, even for a slight change in information, they can use dbt incremental in BigQuery.
Setting up BigQuery for dbt
- Navigate to BigQuery Console and create a BigQuery account (considering you are setting up BigQuery for the first time).
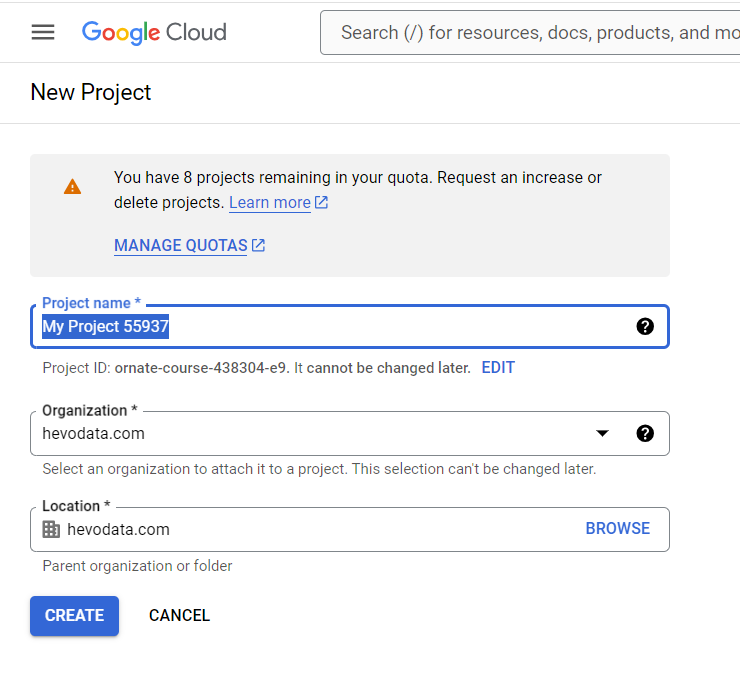
- Click on New Project on the top right to create a project.
- Prove project name and other details like Organization and Location, if necessary. Click Create.
Load Data in BigQuery
- Go to BigQuery Console and copy the below code in the Query Editor to fetch data from public datasets supported by BigQuery.
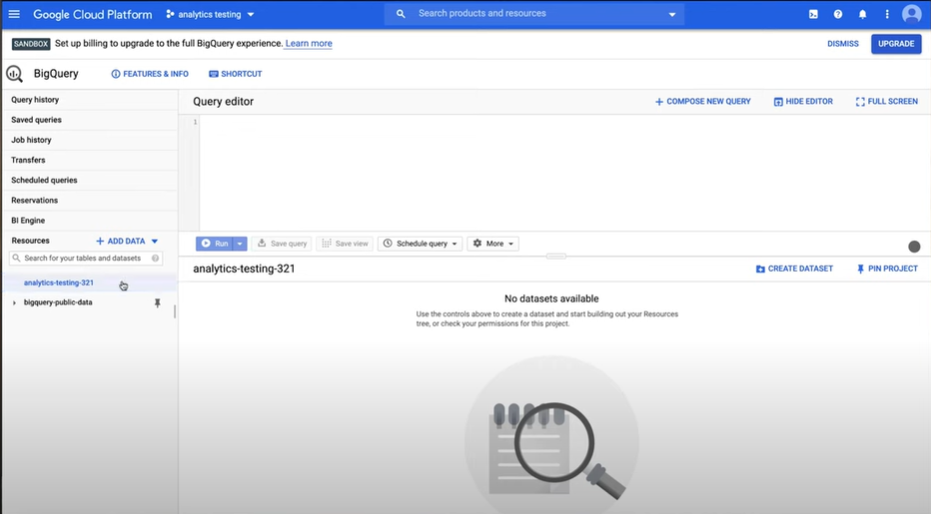
- Find the project in the picker and click on the three dots to select create dataset.
- Provide a valid Dataset ID to reference the database objects. Create Dataset ID for jafffle_shop and stripe. For now, you can just use the name jaffle_shop as the Dataset ID
- Click on Create Dataset.
- Now, repeat the entire steps (1 to 4) to create a Dataset ID with stripe.
Create a Starter Project
- Create a GitHub repository and name it dbt-tutorial.
- Go to the command line and start version control for jaffle_shop project with the command: dbt init jaffle_shop.
- With any IDE, open the project directory. It includes .sql and .yml files created as a result of the previous step.
- Update the dbt_project.yml file by changing the values of name, profile, and models to “jaffle_shop.”
Connect to BigQuery
The yml file contains all the necessary details to connect with data warehouses like Google BigQuery.
- Create a file in the ~/.dbt/ directory named profiles.yml.
- Move the BigQuery keyfile into the directory.
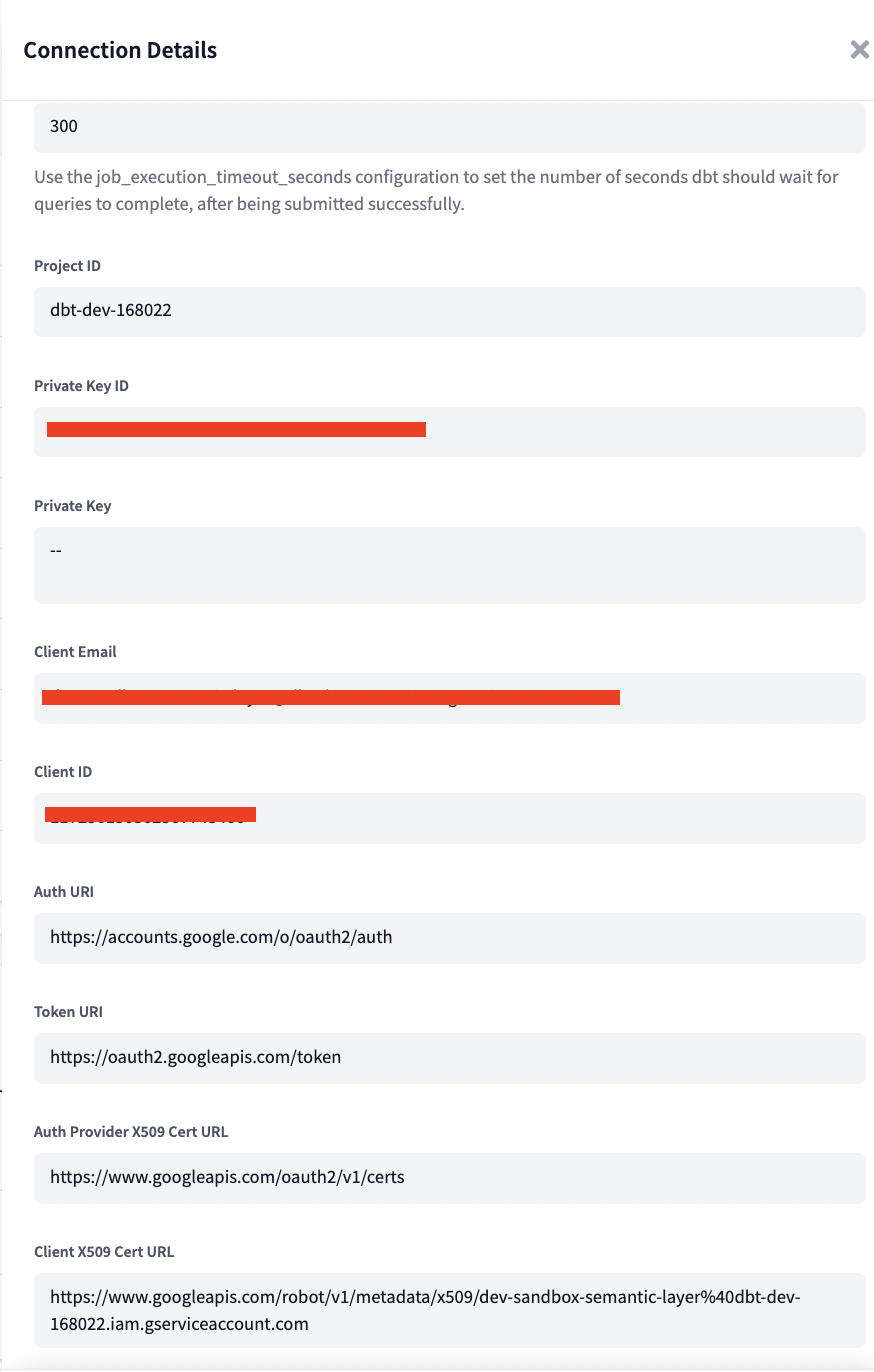
- Debug to check the connection with:
$ dbt debug
> Connection test: OK connection ok
You can read our article for a more detailed guide to connecting dbt to BigQuery.
Commit Changes to the GitHub Repository
- Execute a run command with dbt run and commit the changes.
Build the First Model
- Open the project in any IDE.
- In the models directory, create a new SQL file named models/customers.sql.
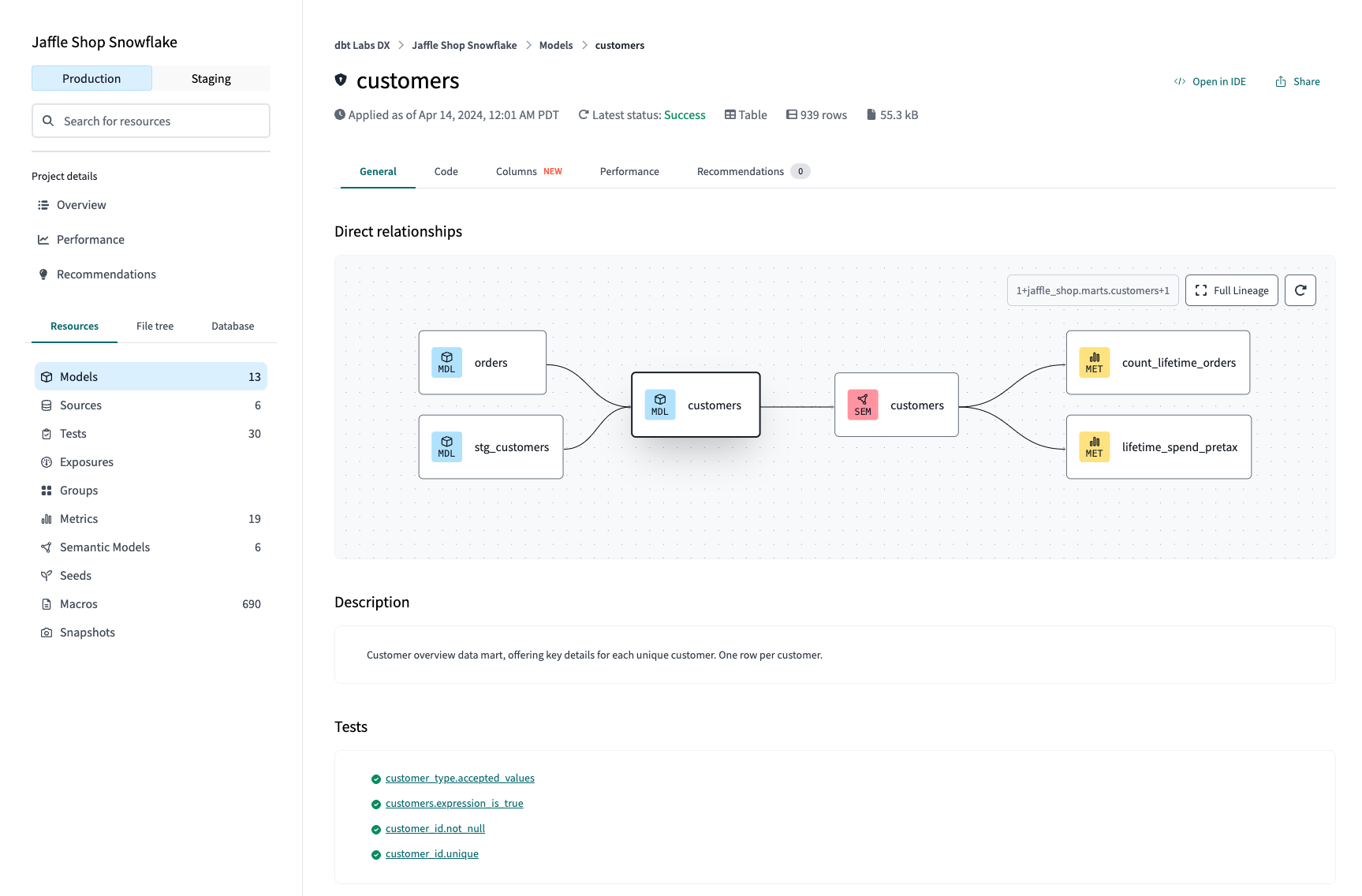
As the dbt materialization is by default in view, the above model generates an output as view. However, to obtain dbt BigQuery incremental transformation, you need to change the materialization to incremental while building the model in a .sql file.
Incremental Transformation of Data in BigQuery
Similar to the view materialization, a dbt BigQuery incremental transformation is a SELECT statement. But, for the SELECT statement to work as an incremental transformation, you must add the following code snippet before the SQL statement.
WITH
using_clause AS (
SELECT
ride_id,
subtotal,
tip,
max(load_timestamp) as load_timestamp
FROM {{ ref('rides_to_load') }}
{% if is_incremental() %}
WHERE load_timestamp > (SELECT max(load_timestamp) FROM {{ this }})
{% endif %}
),
updates AS (
SELECT
ride_id,
subtotal,
tip,
load_timestamp
FROM using_clause
{% if is_incremental() %}
WHERE ride_id IN (SELECT ride_id FROM {{ this }})
{% endif %}
),
inserts AS (
SELECT
ride_id,
subtotal,
NVL(tip, 0, tip),
load_timestamp
FROM using_clause
WHERE ride_id NOT IN (SELECT ride_id FROM updates)
)
SELECT * FROM updates UNION inserts
While using incremental transformation, you would mainly have to use two types of technique: is_incremental() and {{this}}.
- is_incremental(): It is mainly used to transform the recently updated records. For this, you would need to set a unique key that allows you to identify and avoid duplicates. is_incremental() checks whether the record has already been transformed since the last dbt run.
- {{this}}: It is used to query the target table to check for the timestamp of the last modification. This is beneficial while appending new rows to the target table.
Type 1: Incremental Model(Events-Style Data)
- Data is present in the data warehouse
- You have event-style data
Dbt incremental BigQuery can be used to calculate the daily active users (DAU) with event stream data. You can identify the DAU of the dbt last run and DAU since the last run.
{{
config(
materialized='incremental',
unique_key='date_day'
)
}}
select
date_trunc('day', event_at) as date_day,
count(distinct user_id) as daily_active_users
from {{ ref('app_data_events') }}
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
-- (uses >= to include records arriving later on the same day as the last run of this model)
where date_day >= (select coalesce(max(date_day), '1900-01-01') from {{ this }})
{% endif %}
group by 1
Type 2: Incremental Model(Historical Tracking)
- Your data source doesn’t store metadata, but you want to start building it
- You would like to track the history of the downstream model
Suppose you want to calculate the sales of your e-commerce company. You run a query to get the income at the end of the month. After a few days, the income changed due to the return of products. In this case, you would have to get the updated income for January. Now, you have two versions of January income. Say, you fixed a bug in your query, and the updated January income is now different from the previous two. At this point, you have three different versions of the January income. What income detail would you provide to the decision-maker?
To simplify this, you can create a snapshot of the final model (fct_income). This can allow end-users to filter based on the criteria they would like to view the January income. However, a snapshot of source data is recommended over the final model as it is less complex. To address such issues, you can create an incremental model downstream of the final model to obtain all the versions of the January income.
The configuration for capturing the incremental history (let’s call it int_income_history) would look like this:
{{
config(
materialized='incremental'
)
}}
select ...
The model can be further updated with additional configurations:
- on_schema_change: handles schema change in case of addition/deletion of new columns
- schema: to setup role-based permission for historical table
- full_refresh: to help prevent accidental loss of the historical data
The final configuration block for int_income_history would be as follows:
{{
config(
materialized='table'
)
}}
WITH history AS (
SELECT
order_id,
total_income,
return_status,
load_timestamp
FROM {{ ref('int_income_history') }}
)
SELECT *
FROM history;
Ultimately, you must create a fct_income_history to determine the correct version. The new DAG would be as follows:
Source Table → int_income_history (Incremental Model) → fct_income_history (Final Historical Model)
This structure ensures that all versions of income (including updates, returns, and other changes) are tracked and available for decision-makers to review.
Rebuild the Table
In case you want to rebuild the data due to a change in the underlying logic to transform, you will have to use the —full-refresh flag in the command line. This will rebuild the table after dropping the existing target table.
$ dbt run --full-refresh --select my_incremental_model+
Conclusion
Dbt incremental BigQuery enables data engineers and database administrators to transform information without leaving the data warehouse. As a result, it is one of the simplest ways to transform data with the help of SQL queries. Dbt might not be straightforward to use as it needs technical skills to implement. But it helps you to optimize resources and speed up the transformation process. Nevertheless, to simplify the adoption of dbt, you can use dbt cloud instead of working with the command line tool.
For cases when you rarely need to replicate data, your engineering team can easily do it. Though, for frequent and massive volumes of data transfers from multiple sources, your engineering team would need to constantly monitor and fix any data leaks. Or you can simply hop onto a smooth ride with cloud-based ELT solutions like Hevo Data which automates the data integration process for you and runs your DBT projects to transform data present in your data warehouse. At this time, the dbt Core™ on Hevo is in BETA. Please reach out to Hevo Support or your account executive to enable it for your team.
Want to take Hevo for a spin?Try Hevo’s 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Share your experience of learning about Data Build Tool(dbt)! Let us know in the comments section below!
FAQs
1. How does incremental work in dbt?
In dbt, incremental models only process new or updated records rather than reprocessing the entire dataset every time. It checks for changes in data using conditions such as timestamps or unique identifiers. When a model runs incrementally, dbt loads only the new data and appends or updates the target table with these records.
2. What is the difference between dbt full load and incremental?
Full load: In a full load, dbt rebuilds the entire model from scratch, processing all the data every time the model runs. It drops and recreates the target table with fresh data.
Incremental: In an incremental load, dbt processes only new or changed data since the last run. The target table is updated with just the new records, which improves efficiency for large datasets.
3. What is the best place in dbt to specify a model to be incremental?
The best place to specify a model as incremental in dbt is in the model’s configuration block, using the materialized=’incremental’ configuration inside the model’s .sql file. This ensures that dbt treats the model as incremental when it runs.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





