




Amazon Redshift is a Data Warehousing service. Redshift is based on the Amazon Web Services (AWS) architecture and provides great performance to its consumers.
It’s a columnar database, thus it’s great for aggregating large amounts of data and Parallel processing. As a result, even huge enterprises with terabytes of data may use Redshift as a Data Warehouse platform.
Elasticsearch is a distributed, free, and open search and analytics engine for textual, numerical, geographic, structured, and unstructured data.
Elasticsearch is the key component of the Elastic Stack, a suite of free and open tools for Data intake, enrichment, storage, analysis, and visualization.
Table of Contents
What is Amazon Redshift?
- Amazon Redshift is a petabyte-scale cloud Data Warehouse tool for storing and analysing large Data Sets that is completely managed.
- Large-scale database migrations are also performed with it. The column-oriented database in Redshift is built to link to SQL-based clients and business intelligence (BI) tools, allowing users to access data in real-time.
What is AWS Elasticsearch?
- Elasticsearch is a Java-based, decentralized, open-source search and analytics engine based on Apache Lucene.
- Elasticsearch allows users to easily store, search, and analyze large amounts of data in near real-time, with results arriving in milliseconds. Because it searches an index rather than the text directly, it can produce quick search results.
Amazon Redshift vs Elasticsearch Differences
Architecture
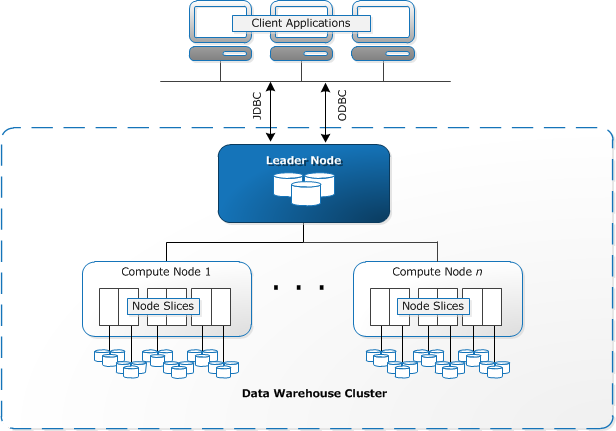
- The first difference between Redshift vs Elasticsearch is in the architecture.
- The Data Tables should be stored across multiple nodes because Redshift is a decentralized and clustered service. The type of node instance determines the number of slices for each node.
- The number of slices for every node is determined by the type of node instance.
- The three types of instances that Redshift currently supports (ra3) are Dense Compute (dc2), Dense Storage (ds2), and Managed Storage.
In 1MB block, each slice stores many tables. This network of slices and nodes accomplishes two goals:
- Distribute data and computation across all compute nodes in a uniform manner.
- Reduce data traffic and improve join efficiency by collating data and computing among nodes.
- To call the proxy microservice, the AWS Cloud Formation template uses an Amazon API Gateway (AWS Lambda function).
- The microservice manages preprocessing settings, native indexing, and other native search features by providing the business logic.
- Then it interacts with Amazon Comprehend for textual analysis, Cloudwatch Logs for logging and monitoring, and Amazon OpenSearch Service for document indexing are later on used by the microservice.
- The proxy microservice forwards authorized requests to Amazon Comprehend for text analysis when the API gets them.
- The data is indexed and logs and metrics are published to CloudWatch via the Amazon OpenSearch Service.
- On the solution’s pre-configured Kibana dashboard, you may visualize the indexed data. The AWS Cloud environment created by deploying this solution looks like this.

Performance
- The next difference between Redshift vs Elasticsearch is in performance.
- Amazon Redshift has a speed advantage thanks to the implementation strategy of columnar storage algorithms and Data Partitioning techniques.
- By combining machine learning, massively parallel processing (MPP), and columnar storage on SSD discs, Amazon Redshift can achieve 10x the speed of comparable Data warehouses.
- Even with all of that power, it’s probable that It’ll run into issues with query performance or workload scaling.
- An MPP database, Amazon Redshift; Massively Parallel Processing (MPP) is an acronym for massively parallel processing.
- However, due to its distributed structure, AWS Elasticsearch has the ability to facilitate the concurrent processing of massive volumes of data.
- AWS Elasticsearch’s high-end performance also enables to locate the best matches quickly based on the queries provided.
- When it comes to performance between Redshift vs Elasticsearch, Elasticsearch can handle even the most complex searches with ease.
- It also caches practically all structured queries that are regularly used as a result set filter and only runs them once.
- It checks the result from the previous request for every other query containing a cached filter.
Ease of Administration
- Amazon Redshift provides functionality to help alleviate the administrative effort that comes with administering a database.
- Tooling is offered to quickly construct clusters, automate database backups, and scale up and down the Data Warehouse.
- Previously, database administrators were required for all of these tasks. Users may still do these operations with Amazon Redshift’s out-of-the-box tooling by clicking a few buttons or calling REST APIs.
- Whereas all of the services in Amazon Elasticsearch are completely managed, making it simple to utilise. Backup, failure recovery, software patching, and monitoring can all be done faster.
- Users of AWS Elasticsearch can quickly post a production-ready Elasticsearch cluster using AWS Elasticsearch.
- No worries about Elasticsearch software installation or maintenance. Kibana, a visualisation tool, is integrated with Elasticsearch.
- This programme supports reporting components in addition to visualisation.
- Elasticsearch is also connected with Logstash and Beats, making it possible to transform load and source data into an Elasticsearch cluster.
Security
- Security is another major point when it comes to Redshift vs Elasticsearch. When it comes to Amazon Redshift security, nothing can be taken for granted.
- Users can employ Amazon Redshift’s security features on top of the security implemented at the cloud services layer.
- A strong identity and access management, role-based access control (RBAC), in-transit and at-rest encryption, and SSL connections are all available.
- On the other hand, VPC makes it simple for all users to set up safe access to the Amazon Elasticsearch service.
- It also provides for flawless Amazon Elasticsearch service and VPC maintenance within the AWS network.
- It automatically deploys security patches at regular intervals to improve the domain’s performance and maintain it up to date and secure.
Scalability
- The next difference between Redshift vs Elasticsearch is in the scalability.
- One of the most crucial characteristics of a database, and Amazon Redshift is no exception, is its ability to scale. Scaling a Redshift cluster is a piece of cake in comparison to scaling an on-premise database.
- Internal issues such as hardware expansion, VM resizing, and data rebalancing among nodes are all handled by Redshift and disguised behind a UI button or a REST API call.
- Elasticsearch scalability is accomplished by natural distribution.
- Elasticsearch intelligently splits data and query load over all available nodes when computers (nodes) are added to a cluster for capacity boost.
- There’s no need to rewrite your application because Elasticsearch understands how to optimize multi-node clusters for scaling and high availability.
Pricing
- Pricing is one of the major differences between redshift vs Elasticsearch.
- There are no upfront expenses with Amazon Redshift on-demand; you essentially pay an hourly rate based on the kind and no. of nodes in your cluster.
- By committing to utilizing Amazon Redshift for a 1 or 3-year period, It could save up to 75% over on-demand prices.
- The cost for reserved instances is particular to the node type purchased and is in effect till the reservation term expires.
- Choose what’s best for your organization, with the freedom to expand storage without overprovisioning compute and the ability to expand compute capacity without bigger storage costs.
Optimization of Query
- The last but not the least difference between Redshift vs Elasticsearch is in the optimization of query.
- To interact with data and objects in Amazon Redshift queries based on structured query language (SQL) are used.
- The subset of SQL known as data manipulation language (DML) is used to examine, add, alter, and delete data. DDL (data definition language) is a subset of SQL that is used to create, modify, and destroy database objects like tables and views.
- On datasets spanning from gigabytes to exabytes, Amazon Redshift provides lightning-fast query speed.
- To reduce the amount of I/O required to run queries, Redshift employs columnar storage, Data compression, and zone maps.
- It parallelizes and distributes SQL operations to take advantage of all available resources using a massively parallel processing (MPP) Data Warehouse architecture.
- On the contrary, Elasticsearch offers a robust JSON-based DSL that allows developers to build complicated queries and fine-tune them to get the most precise search results. It also allows rating and group results.
- Uniqueness isn’t enforced. In Redshift, there is no method to ensure that entered data is unique.
- Parallel upload is only supported by S3, DynamoDB, and Amazon EMR. It’s important to know how to use the Sort and Dist keys. It’s not possible to utilize it as a live app database.
Amazon Redshift vs Elasticsearch: Limitations of Elasticsearch
- Along with its many benefits, AWS Elasticsearch has a few drawbacks, which are as follows: It allows customers to create their domain within a VPC or use a public endpoint.
- Both acts are not permitted to be performed simultaneously in it. AWS Elasticsearch offers a free tier for only 12 months; therefore, it is not free. You must pay to use it after the first 12 months of signing up.
Curious about how Amazon EMR and Redshift stack up against each other? Check out our detailed guide to learn the key distinctions and decide the best option for your data processing requirements.
Understand which solution suits your needs—Redshift for big data or PostgreSQL for diverse applications. Find out more at Redshift vs PostgreSQL.
Conclusion
- Elasticsearch is an elastic co-product that AWS can install and configure for you.
- Redshift is an Amazon Web Services database system based on PostgreSQL and tailored for extremely large data collections.
- Its fundamental function is search-oriented, as its name implies. It’s designed to conduct complicated logical queries against data in “Data Warehouse” applications.
You can also have a look at our unbeatable Hevo Pricing that will help you choose the right plan for your business needs!


Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link


