

Unlock the full potential of your Drip data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Have a lot of data from Drip and not sure where to store it? Don’t worry, we’ve got you covered. In this article, you will:
- Learn what Drip and BigQuery are and how they work.
- Seamlessly connect Drip to BigQuery for efficient data management.
- Eliminate the hassle of managing your Drip data once and for all.
Table of Contents
What is BigQuery?
BigQuery is a serverless, fully managed, and highly scalable Data Warehouse offered by Google for Data Management and Analysis. It provides a Platform as a Service (PaaS) that executes large-scale SQL commands and delivers real-time data.
The built-in features of BigQuery, such as geospatial analysis, advanced Machine Learning algorithms, and Business Intelligence, help you make effective business decisions.
Key Features of BigQuery
- Functionality: BigQuery supports Data Analysis across multiple cloud platforms, which is advantageous compared to other Data Warehousing solutions. The User Selling Point (USP) of BigQuery is that it provides an effortless way to analyze data present in different clouds.
- Machine Learning: BigQuery ML implements Machine Learning algorithms in BigQuery with simple SQL commands. You can quickly solve your business problems with Machine Learning models like linear regression, binary logistic regression, time series analysis, matrix factorization, and deep neural networking.
- Automated Data Transfer: BigQuery Data Transfer enables the automatic movement of data into BigQuery that can be set at regular intervals or scheduled at a particular time. BigQuery Data Transfer lets you import data from a wide range of Google-owned services like Google Play, Google Ads, and YouTube channels.
What is Drip?

Drip is an Automated Marketing Platform that helps e-commerce businesses and brands take their email marketing strategies to a higher level. It enables users to curate personalized emails and provides engagement tools like popups, forms, etc.
Companies can execute marketing campaigns without any hassle or coding knowledge. Along with increasing sales, you will be able to monitor the company’s progress and receive essential insights into the customer’s purchases.
Key Features of Drip
- Lead Management: Drip has pre-built playbooks such as welcome series and post-purchase campaigns that assist you in building a lead database just in a few clicks. A Marketing Lead Database is essential as it stores your leads’ most crucial data and their contact information.
- Online Marketing: Drip focuses mainly on email marketing campaigns, it provides its users with engagement tools like dynamic onboard forms. You can personalize these templates according to your choice without running a single line of code.
- Effective Analysis: Understanding your customers’ behavior is essential for company growth. Drip offers an analytical solution that helps you check the customers’ activity, campaign performance, etc.
Method 1: Connecting Drip to BigQuery Manually
Method 1: Connecting Drip to BigQuery Manually
To replicate your data from Drip to BigQuery, you must first export data from Drip. The data must then be manually loaded into your BigQuery Data Warehouse. Drip BigQuery integration using the manual method may be complicated and take a long time.
Method 2: Automated Data Replication From Drip to BigQuery Using a No Code Solution
Hevo Data, an Automated Data Pipeline, provides a hassle-free solution to connect Drip (Free Source Connector with Hevo) to BigQuery within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of not only loading data from Drip but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
Hevo offers a 14-day free trial, allowing you to explore real-time data processing and fully automated pipelines firsthand. With a 4.3 rating on G2, users appreciate its reliability and ease of use—making it worth trying to see if it fits your needs.
GET STARTED WITH HEVO FOR FREEConnecting Drip to BigQuery Manually has two steps – exporting the data from Drip and uploading it to BigQuery for safekeeping and further analysis. Follow the below-given instructions to connect Drip to BigQuery efficiently.
Step 1: Exporting Data from Drip
To export data from Drip, you must go under the analytics section and get a report in a CSV file format. You will automatically get a mail of the CVS file on the email address you have used to register with Drip. You can export three lists: customer list, analytics, and account information.
Follow these steps to export data from Drip:
- From the top menu bar, visit the Analytics Section.
- Go to Email Metrics.
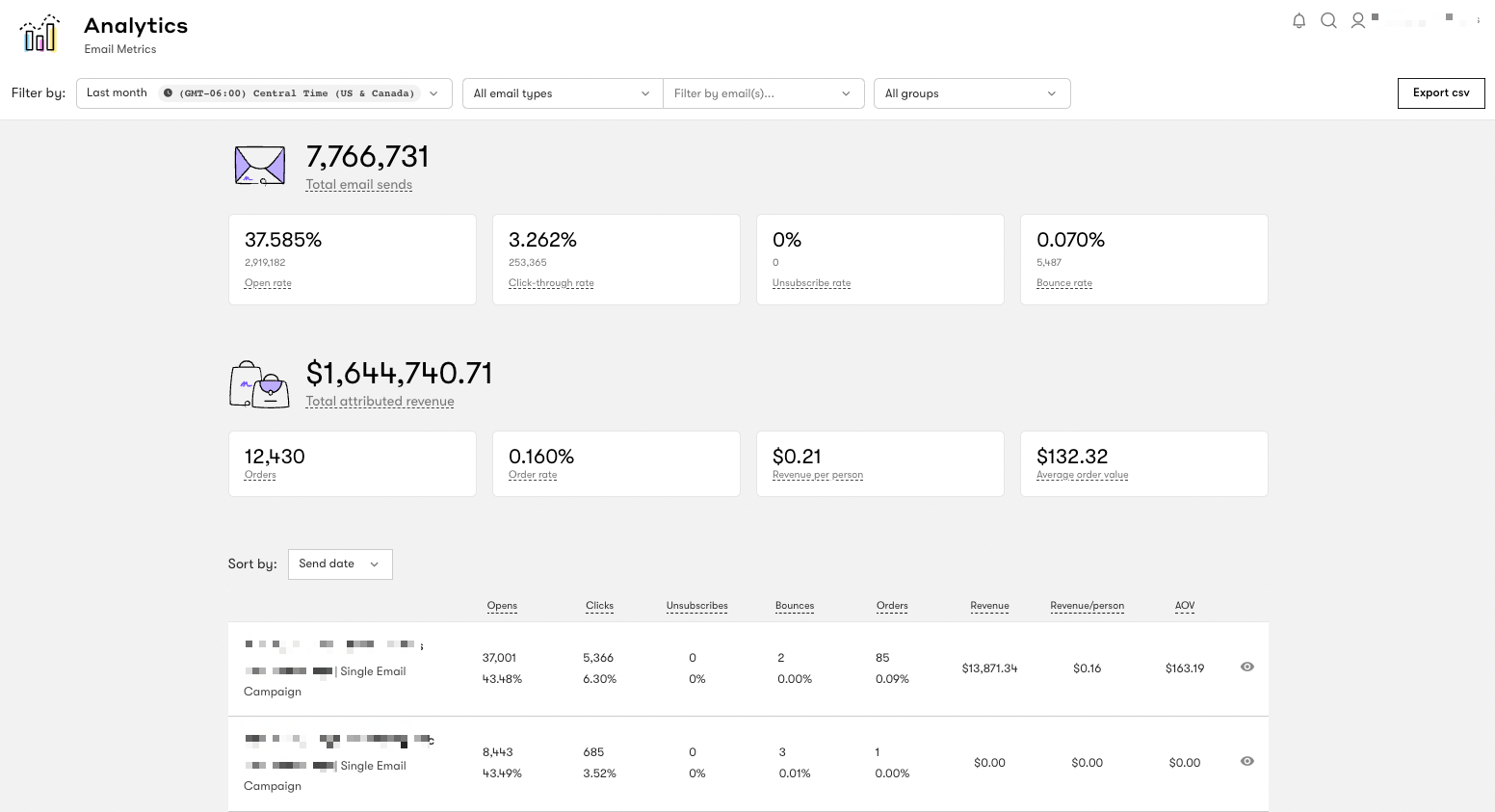
- Click on the Bulk Download tab.
- Select the desirable workflow email type.
- Enter the Start Date using the calendar.
- Enter the End Date using the calendar.
- Click on the Download Report button.
The CSV file contains details of customer ID, subject, delivery count, open count, etc. Note that you will not get the email address of your customers in a bulk download of email metrics.
You need to export the people list if you want a list of the email addresses. To download the people list CSV file from Drip, follow these steps:
- Under People, go to the Active section.
- To create a segment of your data, use the filter option (optional).
- Go to the Actions section.
- Click on the Export to CSV.
- Click the Okay button.
Shortly you will receive a mail containing a link to a CSV file, including email address, id, status, tags, lead source, etc.
Step 2: Loading Data to BigQuery
You must create an empty table to load any data to Google BigQuery. Follow these given steps to upload your Drip data to BigQuery properly:
- Go to the Google BigQuery Home Page.
- Navigate to the Console.
- Select a Project and click on New Project.
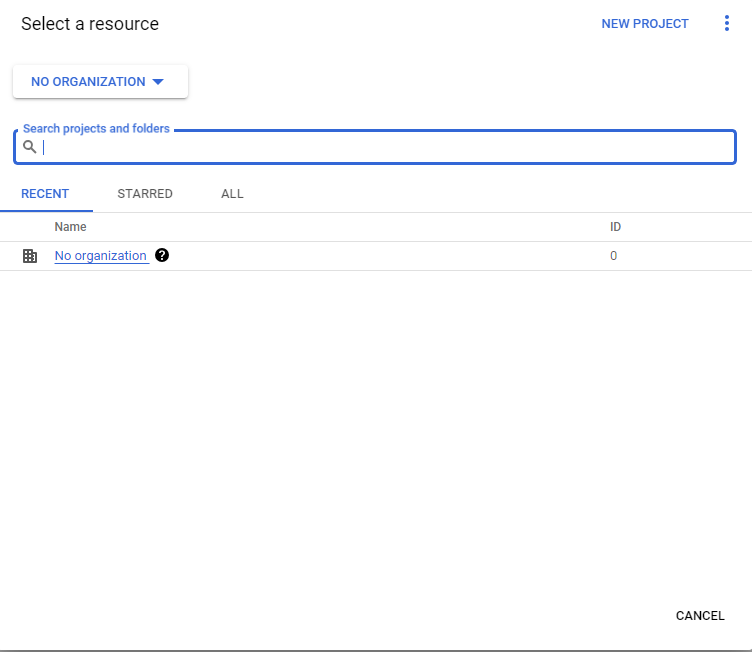
- You’ll need to fill in the details of the Project Name, Organization, and Location.
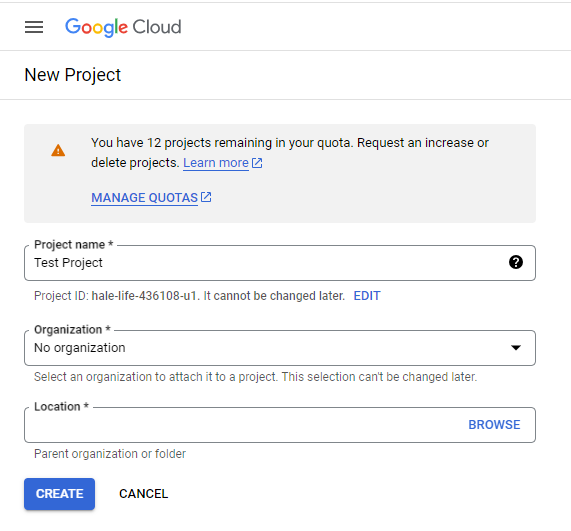
- Click on Create.
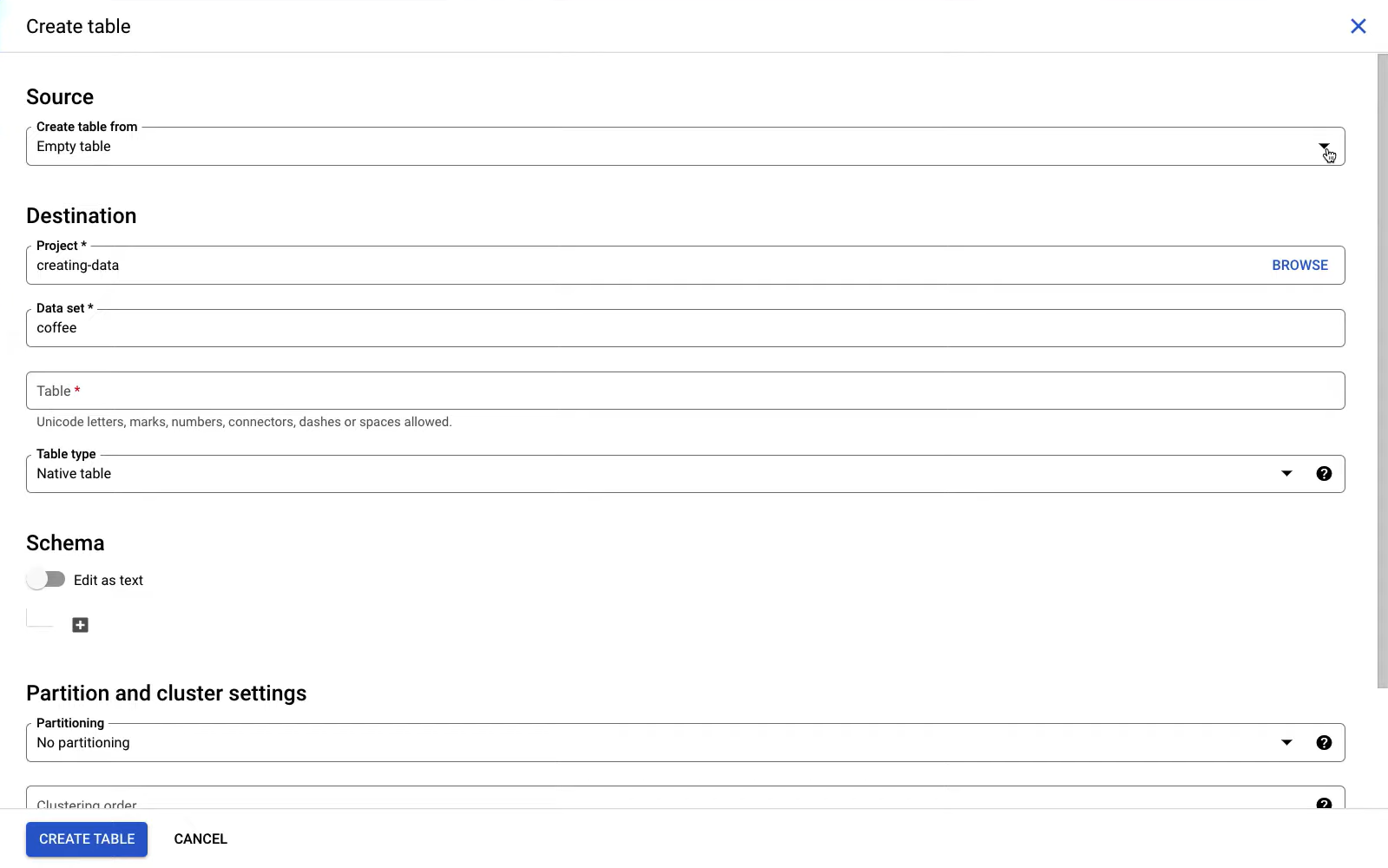
- Choose the file and the relevant file format.
- Enter the source of the data, the name of the project, and the dataset.
- Click on the Create Table button.
Now, your Drip data will get uploaded on Google BigQuery, and you can analyze it using the SQL console. Note that there are two table types in BigQuery – Native and External. BigQuery will automatically choose the table structure. However, you can manually add fields using the “+Add field” button.
Limitations of Connecting Drip to BigQuery Manually
BigQuery is a Data Warehouse that can safely store large amounts of data. It can be integrated with Drip for better analysis and insights. However, the manual process of connecting Drip to BigQuery is tedious to implement and does not support real-time data transfer.
Method 2: Automated Data Replication From Drip to BigQuery Using Hevo

Hevo Data is a No-code Data Pipeline platform that automates data transfer from 150+ Data Sources, including Drip (Free Source Connector with Hevo), to BigQuery Data Warehouse or any other chosen Destination.
Step 1: Configure Drip as a Source
To establish Drip as the Source in your Pipeline, follow these steps:
- In the Asset Palette, choose PIPELINES.
- In the Pipelines List View, click + CREATE.
- Select Drip on the Select Source Type page.
- On the Configure your Drip Source page, enter the following information:
- Pipeline Name: A unique name for your Pipeline that is no longer than 255 characters.
- Account ID: The account ID from which data will be consumed.
- API Key: Your Drip account’s API token allows Hevo to access your data.
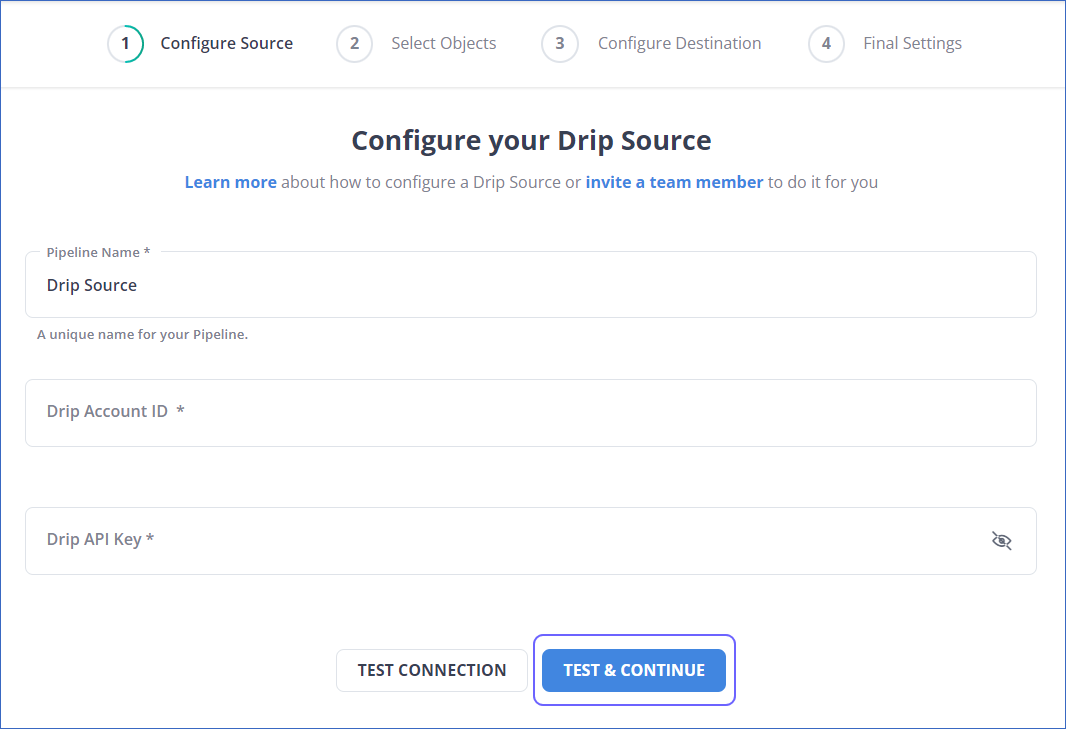
- Click on TEST & CONTINUE.
- Continue by configuring the data intake and configuring the Destination.
Step 2: Configure Google BigQuery as a Destination
To configure BigQuery as a Destination, follow these steps:
- In the Asset Palette, choose DESTINATIONS.
- In the Destinations List View, click + CREATE.
- Select Google BigQuery as the Destination type on the Add Destination page.
- Select the authentication method for connecting to BigQuery on the Configure your Google BigQuery Account page.
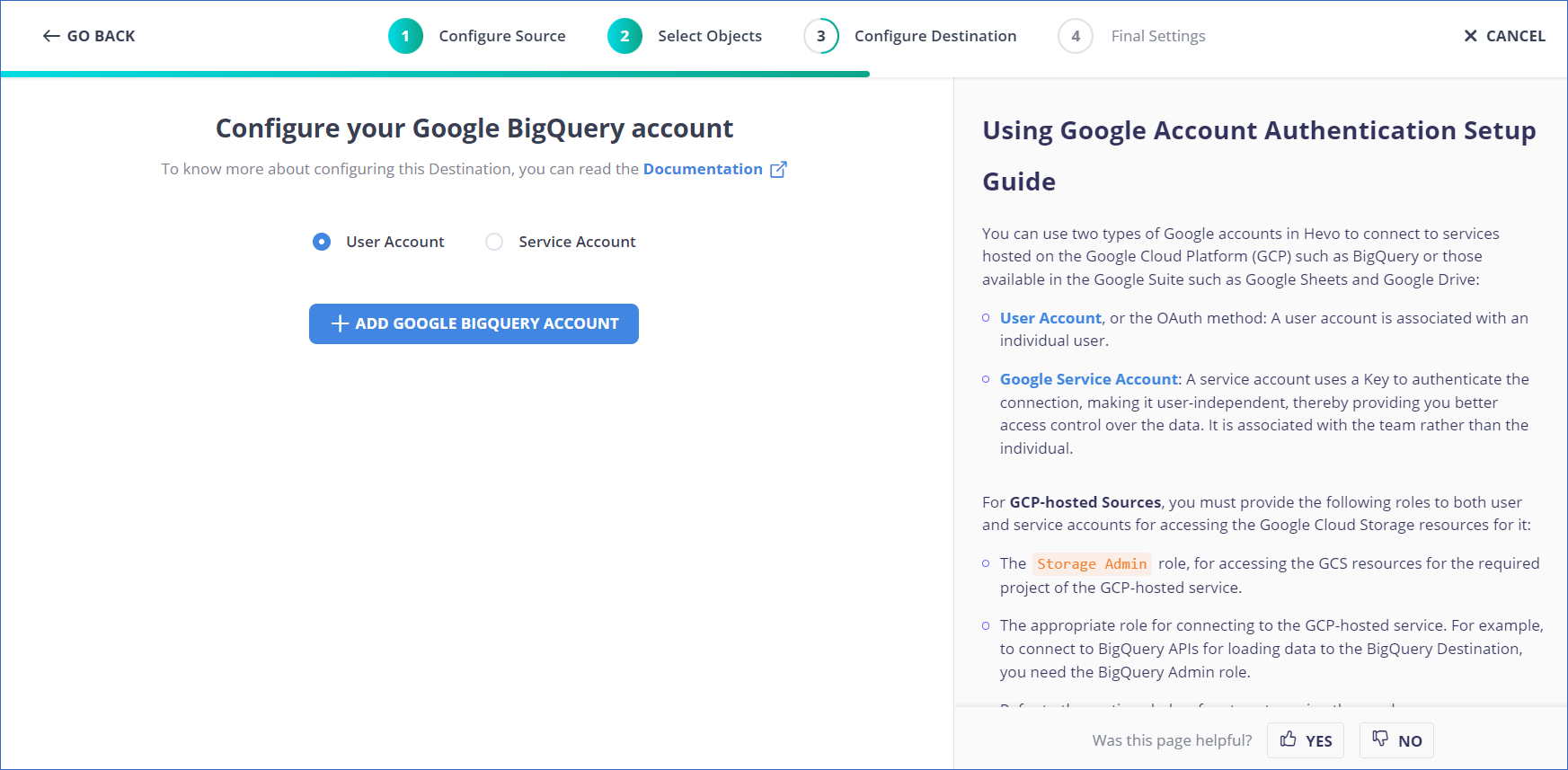
- Perform one of the following:
- To connect with a Service Account, follow these steps:
- Attach the Service Account Key file.
- Click on CONFIGURE GOOGLE BIGQUERY ACCOUNT.
- To join using a User Account, follow these steps:
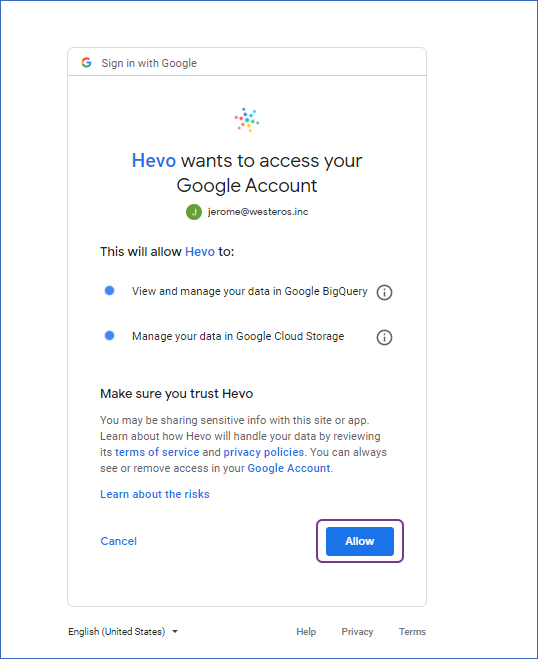
- Click on + ADD A GOOGLE BIGQUERY ACCOUNT.
- Sign in as a user with BigQuery Admin and Storage Admin permissions.
- Provide Hevo access to your data by clicking Allow.
- To connect with a Service Account, follow these steps:
- Configure your Google BigQuery Warehouse page with the following information:
- Destination Name: Give your Destination a distinctive name.
- Project ID: The BigQuery instance’s Project ID.
- Dataset ID: The dataset’s name.
- GCS Bucket: A cloud storage bucket where files must be staged before being transferred to BigQuery.
- Sanitize Table/Column Names: Select this option to replace any non-alphanumeric characters and spaces in table and column names with an underscore (_).
- Populate Loaded Timestamp: Enabling this option adds the __hevo_loaded_at_ column to the Destination Database, indicating the time when the Event was loaded to the Destination.

To test the connection, click TEST CONNECTION and then SAVE DESTINATION to finish the setup.
Why use a No-Code Drip ETL?
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insights Generation: Hevo offers near real-time Data Replication so that you can access real-time insights generation and quicker decision-making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built Integrations for 150+ Data Sources (with 60+ Free Sources) that can help you scale your data infrastructure as required.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.

Key Takeaways
- This article provides an overview of Drip and BigQuery and their features.
- It also explains the two methods for connecting Drip to BigQuery.
- Manual data replication from Drip to BigQuery would need significant time and resources, making the process time-consuming and stressful.
- On the other hand, a Data Integration solution, such as Hevo, enables you to replicate data quickly and efficiently.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines.
You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
You can share your experience connecting Drip to BigQuery in the comments below.
Frequently Asked Questions
1. How do I transfer data to BigQuery?
To upload CSV data to BigQuery, go to the Create table window, choose Upload as the data source, select your file and format, then specify the project and dataset as the Destination.
2. How to convert Oracle query to BigQuery?
Step 1: Export Data from Oracle DB to CSV Format.
Step 2: Extract Data from Oracle DB.
Step 3: Upload to Google Cloud Storage.
Step 4: Upload to BigQuery from GCS.
Step 5: Update the Target Table in BigQuery.
3. How to migrate Hive data to BigQuery?
For the initial migration, store the list of files in a tracking table, copy them to Cloud
Storage, and load them into BigQuery. After the migration, when new data is ingested in Hive only migrates the incremental data to BigQuery.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





