

Today, organizations generate huge volumes of data, across verticals, every day. This has led to an increased demand for Data Storage options. Cloud Storage was invented to meet this demand. Organizations enjoy a number of benefits when they store their data in the Cloud compared to when they use On-premise storage options. Data stored in the Cloud is easy to access from any location. At the same time, the Cloud offers massive scalability compared to On-premise storage options.
Many businesses are opting for Cloud Storage compared to other storage options. The number of Cloud Storage providers is rising at a high rate. The Firebolt Data Warehouse is a good example of one of the most highly anticipated new Cloud Storage providers. It is well-known for its ease of use and fast speed when it comes to analyzing data. The article discusses Firebolt as one of the data warehouse tools available, specifically a ‘Cloud Data Warehousing solution’
Table of Contents
What is Firebolt Data Warehouse?
Firebolt is a Cloud Data Warehousing solution that helps its users streamline their Data Analytics and access to insights. It offers fast query performance and combines Elasticity, Simplicity, Low cost of the Cloud, and innovation in Analytics. It is developed with a powerful SQL Query Engine that separates Computing and Storage, enabling users to spin up many isolated resources on a similar database.
Note:
- There are no impossible data challenges with the Firebolt Database. It is suitable for aggregating data that lacks granularity.
- If you need to make changes to your schema frequently, make your Semi-Structured data ready for analysis, or your queries are too slow even after optimizing them, choose Firebolt Cloud Data Warehouse.
- It turns all impossible data problems into easy everyday tasks.
Struggling to migrate your data to data warehouses? Hevo makes it a breeze with its user-friendly, no-code platform. Here’s how we simplify the process:
- Seamlessly pull data from 150+ other sources with ease.
- Utilize drag-and-drop and custom Python script features to transform your data.
- Efficiently migrate data to a data warehouse, ensuring it’s ready for insightful analysis.
Experience the simplicity of data integration with Hevo and see how Hevo helped fuel FlexClub’s drive for accurate analytics and unified data.
Get Started with Hevo for FreeSteps to use Firebolt Data Warehouse
A) Creating a New Database in Firebolt
To work with your data on Firebolt, you should first create a new Database and Engine. The Firebolt Engine will represent the computing resources attached to a Database for a particular workload. There are different types of engines that you can select depending on the workflow that you need to manage. The engines can be scaled either upwards or downwards even after the initial configuration.
The following steps can help you to create a new Database and Engine in Firebolt:
- Step 1: Open the Database Page
- Step 2: Create the Database and Engine
- Step 3: Start the Database Engine
- Step 4: Query the Database
Step 1: Open the Database Page
- Open the Database Page in Firebolt and click “+ New Database”.
- Give the Database the name “Tutorial” and select the region.
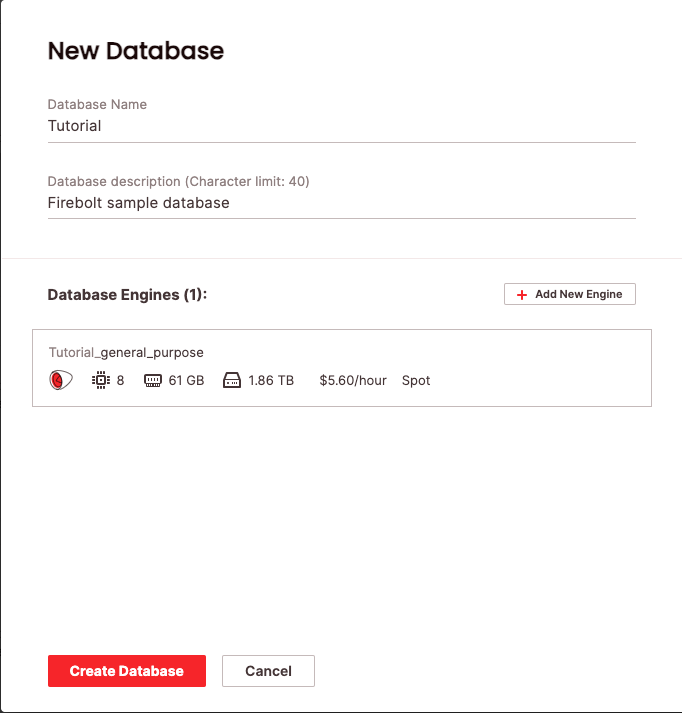
Step 2: Create the Database and Engine
- Click the “Create Database” button.
- This will create both the Database and the Engine.
Step 3: Start the Database Engine
- Open the Engines’ page and find the “Tutorial_ingest” Engine from the list of available Engines.
- Click “Start” to start the Engine. When the Engine starts running, the status will change to “On”.
Step 4: Query the Database
- Open the SQL Workspace Page. You will be prompted to select the Database that you need to perform the query on.
B) Importing Data into Firebolt Database
To use your data in Firebolt, you must establish a connection with your data sources and then ingest the data. Follow the steps given below to do so:
Step 1: Create an External Table
You should now connect to a public Amazon S3 bucket (data source) where your Parquet Files are stored. Use the Firebolt Demo Bucket which has tables from the TPC-H benchmark.
But first, create an External Table, which is a virtual table that establishes a direct connection to an external data source from the Amazon S3 bucket without the need to load the data into a Firebolt Table.
Paste the command given below into the SQL Workspace page to create an External Table:
CREATE EXTERNAL TABLE IF NOT EXISTS ex_lineitem
( l_orderkey LONG,
l_partkey LONG,
l_suppkey LONG,
l_linenumber INT,
l_quantity LONG,
l_extendedprice LONG,
l_discount LONG,
l_tax LONG,
l_returnflag TEXT,
l_linestatus TEXT,
l_shipdate TEXT,
l_commitdate TEXT,
l_receiptdate TEXT,
l_shipinstruct TEXT,
l_shipmode TEXT,
l_comment TEXT
)
URL = 's3://firebolt-publishing-public/samples/tpc-h/parquet/lineitem/'
-- CREDENTIALS = ( AWS_KEY_ID = '******' AWS_SECRET_KEY = '******' )
OBJECT_PATTERN = '*.parquet'
TYPE = (PARQUET);The command will create an External Table named ex_lineitem which will be shown in the Object Panel of the Database.
Step 2: Import the Data into External Table
It’s now time to load the data into the Firebolt Database. For that, you need to create a Fact Table named lineitem and load it with data so as to work with the data from the ex_lineitem table.
Use the code given below to create a new Fact Table:
CREATE FACT TABLE IF NOT EXISTS lineitem
( l_orderkey LONG,
l_partkey LONG,
l_suppkey LONG,
l_linenumber INT,
l_quantity LONG,
l_extendedprice LONG,
l_discount LONG,
l_tax LONG,
l_returnflag TEXT,
l_linestatus TEXT,
l_shipdate TEXT,
l_commitdate TEXT,
l_receiptdate TEXT,
l_shipinstruct TEXT,
l_shipmode TEXT,
l_comment TEXT
) PRIMARY INDEX l_orderkey, l_linenumber;The table will be created and shown in the Object Panel of the Database.
We can now use the INSERT INTO command to copy data from the external table into the Fact Table:
INSERT INTO lineitem
SELECT *
FROM ex_lineitem;When you query the lineitem table, it should have data in it.
Limitations of using Firebolt Cloud Data Warehouse
The following are the limitations of the Firebolt Data Warehouse:
- Steep Learning Curve: It is a complex Data Warehouse. Hence, it may take a long time for one to learn how to use it.
- Technical knowledge is Required: Using this complex Data Warehouse requires you to write and run SQL queries. This means that knowledge of SQL will be needed.
- Real-time Data Transfer: Firebolt users encounter challenges when they need to transfer data from and to the Firebolt Database in real-time.
Conclusion
In this article, you learned about the key concepts associated with Firebolt Data Warehouse. You also learned about the necessary steps required to use this new Data Warehouse for your data and analytical needs.
In case you want to integrate data from data sources into your desired Data Warehouse/destination, then Hevo Data is the right choice for you! It will help simplify the ETL and management process of both the data sources and destinations.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at our unbeatable pricing that will help you choose the right plan for your business needs!
Share your experience of learning about Firebolt Data Warehouse in the comments section below.
Frequently Asked Questions
1. What is Firebolt data warehouse?
Firebolt is a cloud-native, high-performance data warehouse designed to handle large-scale data processing and analytics.
2. Is Firebolt better than Snowflake?
Whether Firebolt is better than Snowflake depends on your specific needs and use cases.
3. What is Firebolt used for?
Big data analytics
Real-time analytics
Business intelligence
Data warehousing
Data integration
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




