




 Quick Takeaway
Quick TakeawayMigrating data from an FTP server to an Amazon S3 bucket can be achieved using several methods, including using S3FS, FTP/SFTP clients, or using tools like Hevo Data.
- Method 1: FTP S3 Integration using S3FS allows you to mount S3 as a filesystem, enabling interaction with it using standard file transfer tools.
- Method 2: FTP S3 Integration using FTP/SFTP Clients involves using FTP/SFTP clients like FileZilla or Cyberduck to manually transfer files from the FTP server to S3.
- Method 3: Using Hevo Data automates the entire process, providing a no-code solution for seamless, real-time data transfer from FTP to S3 with minimal setup.
An array of beneficial features can be harnessed with Amazon S3 transfers made using FTP. The FTP S3 combination enhances data availability and improves access without any system limitations. This article deals with a detailed guide describing how to transfer data from FTP to S3 using two alternate solutions.
This article aims at providing you with a step-by-step guide to help you set up the FTP S3 integration with ease to help you transfer your data to Amazon S3 for a fruitful analysis securely. Upon a complete walkthrough of the content, you’ll be able to connect the FTP server to Amazon S3 easily. It will further help you build a customized ETL pipeline for your organization. Through this article, you will get a deep understanding of the tools and techniques & thus, it will help you hone your skills further.
Table of Contents
What is FTP [File Transfer Protocol]?

FTP Working Mechanism
FTP is a robust and fast network protocol that allows large file transfers based on a client-server model. Features like block storage, Storage Area Networks, NAS, etc. can be used to optimize file transfer and storage strategies. This protocol, when used with Amazon S3, can greatly improve system performance.
What is Amazon S3?

Amazon’s Simple Storage Service renders a range of comprehensive and simple-to-implement services over the Internet. With a set of dedicated features for the storage, movement, security, configuration, and analytics of data, it is a popular choice among different businesses.
Creating an S3 FTP file transfer mechanism can present several significant benefits. The file storage can be minimized while also increasing the planning administration capacity. Using S3 FTP object storage as a file system you can carry out interactions at the application level but directly mounting S3 is not possible. For efficient management of objects at scale, S3 Batch Operations can perform actions on millions of items at once, each identified by its unique S3 key.
Hevo Data, an Automated No-code Data Pipeline, helps you directly transfer data from various sourceslike FTP to a data warehouse or a destination of your choice in a completely hassle-free & automated manner. What’s more, the in-built transformation capabilities and the intuitive UI means even non-engineers can set up pipelines and achieve analytics-ready data in minutes.
Why Hevo is the Best:
- Minimal Learning Curve: Hevo’s simple, interactive UI makes it easy for new users to get started and perform operations.
- Connectors: With over 150 connectors, Hevo allows you to seamlessly integrate various data sources into your preferred destination.
- Schema Management: Hevo eliminates the tedious task of schema management by automatically detecting and mapping incoming data to the destination schema.
- Live Support: The Hevo team is available 24/7 and offers exceptional support through chat, email, and calls.
- Cost-Effective Pricing: Transparent pricing with no hidden fees, helping you budget effectively while scaling your data integration needs.
- Live Monitoring: Advanced monitoring gives you a one-stop view of all the activities within data pipelines.
Try Hevo today and experience seamless migration.
Get Started with Hevo for FreeMethods to Implement FTP S3 Integration
Method 1: FTP S3 Integration using S3FS
S3FS – Fuse is a FUSE-based file system that facilitates fully functional file systems, an S3 bucket can be directly mounted as a local filesystem. Read and write access is made available for the same along with fundamental file management commands for manipulation.
Procedure for FTP S3 Integration using S3FS
To install and setup S3FTP and carry out S3 transfer using FTP, you can implement the following steps:
- Step 1: Create an S3 Bucket
- Step 2: Create an IAM Policy and Role for S3 bucket
- Step 3: Proceed to Launch FTP Server
- Step 4: Installation and Building of S3FS
- Step 5: User Account and Home Directory Configuration
- Step 6: Installation and Configuration of FTP
- Step 7: Run a Test with FTP Client
- Step 8: Initiate S3FS and Mount Directory
- Step 9: Run S3 FTPS to Perform File Transfer
Step 1: Create an S3 Bucket
The first thing to get started is to create an S3 bucket using the AWS console. This will serve as the final location for all files transferred through FTP.
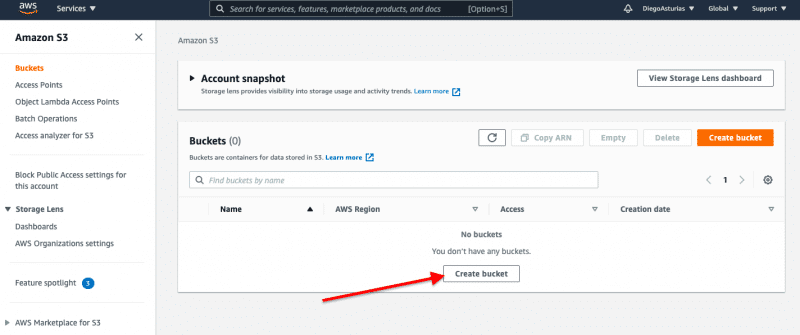
Step A: Create a Bucket
The first thing to get started is to create an S3 bucket.
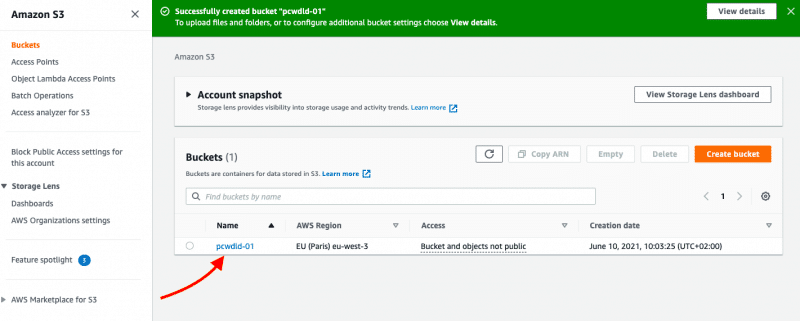
Step B: Configure your Bucket
Set up your bucket. Give it a name and choose the AWS region, as well as access, versioning, and encryption options. After that, your S3 bucket should be ready to use.
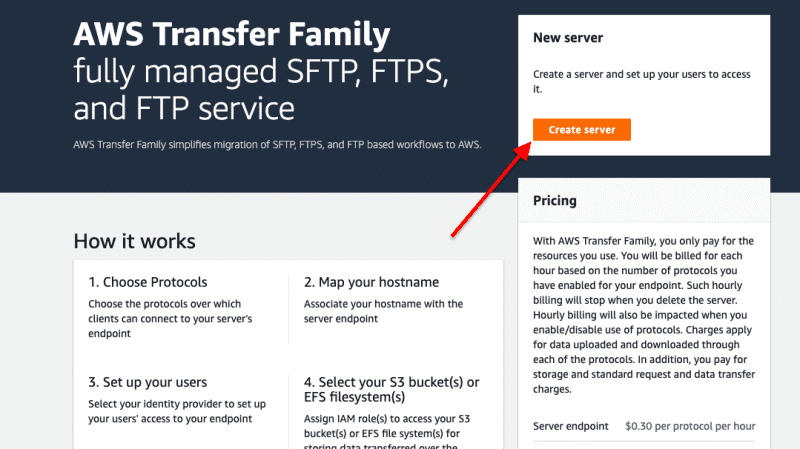
Step C: Create a New Server
Open AWS Transfer for SFTP and Create a New Server in your AWS interface.
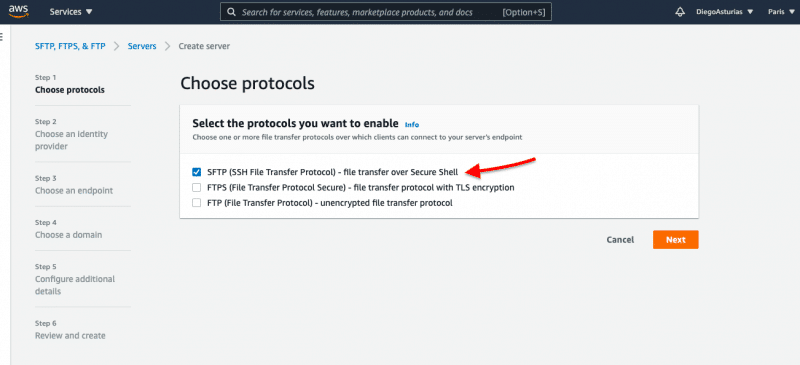
Step D: Choose a Protocol
Choose the protocol when configuring your new server (SFTP, FTPS, or FTP).
Step 2: Create an IAM Policy and Role for S3 Bucket
Proceed to create an IAM [Identity and Access Management] Policy and Role that can facilitate read/write access to all previous S3 buckets. This can be done by running the following command:
aws iam create-policy
--policy-name S3FS-Policy
--policy-document file://s3fs-policy.jsonReplace the bucket name “ca-s3fs-bucket” with the S3 bucket that you will be using within your own environment as shown below:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::ca-s3fs-bucket"]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": ["arn:aws:s3:::ca-s3fs-bucket/*"]
}
]
}Finally, you need to create the S3FS role and attach the S3FS policy using the AWS console. This can be created using the AWS IAM console.
Step 3: Proceed to Launch FTP Server
In this step, you need to launch an EC2 instance on Amazon Linux 2 for hosting the FTP service.
Run the following command to launch the instance with the attached S3FS role:
aws ec2 run-instances
--image-id ami-0d1000aff9a9bad89
--count 1
--instance-type t3.micro
--iam-instance-profile Name=S3FS-Role
--key-name EC2-KEYNAME-HERE
--security-group-ids SG-ID-HERE
--subnet-id SUBNET-ID-HERE
--associate-public-ip-address
--region us-west-2
--tag-specifications
'ResourceType=instance,Tags=[{Key=Name,Value=s3fs-instance}]'
'ResourceType=volume,Tags=[{Key=Name,Value=s3fs-volume}]'Within this command, you will use the –associate-public-ip-address parameter to temporarily assign a public IP address to the instance. A production-based environment would use an EIP address and facilitate the launch of the attached S3FS role.
Step 4: Installation and Building of S3FS
Install S3 FTP using the s3ftp.install.sh script. Update local OS packages and install additional packages required for the build and compilation as shown:
sudo yum -y update &&
sudo yum -y install
jq
automake
openssl-devel
git
gcc
libstdc++-devel
gcc-c++
fuse
fuse-devel
curl-devel
libxml2-develUse the following code to ensure the complete and correct installation of S3FS:
git clone https://github.com/s3fs-fuse/s3fs-fuse.git
cd s3fs-fuse/
./autogen.sh
./configure
make
sudo make install
which s3fs
s3fs --helpStep 5: User Account and Home Directory Configuration
Create a user account for the authentication of the FTP service by using the following command:
sudo adduser ftpuser1
sudo passwd ftpuser1Consequently, create a home directory that will be configured for use with the created user account. You can use the following command to create the same:
sudo mkdir /home/ftpuser1/ftp
sudo chown nfsnobody:nfsnobody /home/ftpuser1/ftp
sudo chmod a-w /home/ftpuser1/ftp
sudo mkdir /home/ftpuser1/ftp/files
sudo chown ftpuser1:ftpuser1 /home/ftpuser1/ftp/filesStep 6: Installation and Configuration of FTP
The next stage involves the installation and configuration of the actual FTP service. Install the vsftpd package and backup the default configuration as shown:
sudo yum -y install vsftpd
sudo mv /etc/vsftpd/vsftpd.conf /etc/vsftpd/vsftpd.conf.bakRegenerate the configuration file by running the following script:
sudo -s
EC2_PUBLIC_IP=`curl -s ifconfig.co`
cat > /etc/vsftpd/vsftpd.conf << EOF
anonymous_enable=NO
local_enable=YES
write_enable=YES
local_umask=022
dirmessage_enable=YES
xferlog_enable=YES
connect_from_port_20=YES
xferlog_std_format=YES
chroot_local_user=YES
listen=YES
pam_service_name=vsftpd
tcp_wrappers=YES
user_sub_token=$USER
local_root=/home/$USER/ftp
pasv_min_port=40000
pasv_max_port=50000
pasv_address=$EC2_PUBLIC_IP
userlist_file=/etc/vsftpd.userlist
userlist_enable=YES
userlist_deny=NO
EOF
exitThe following set of vsftp configuration and properties can be observed:
sudo cat /etc/vsftpd/vsftpd.conf
anonymous_enable=NO
local_enable=YES
write_enable=YES
local_umask=022
dirmessage_enable=YES
xferlog_enable=YES
connect_from_port_20=YES
xferlog_std_format=YES
chroot_local_user=YES
listen=YES
pam_service_name=vsftpd
userlist_enable=YES
tcp_wrappers=YES
user_sub_token=$USER
local_root=/home/$USER/ftp
pasv_min_port=40000
pasv_max_port=50000
pasv_address=X.X.X.X
userlist_file=/etc/vsftpd.userlist
userlist_deny=NOAdd the user account to the vsftpd file by implementing echo "ftpuser1" | sudo tee -a /etc/vsftpd.userlist . You can now initiate the FTP service by running sudo systemctl start vsftpd.
Check the status of the FTP service and verify the startup by running sudo systemctl status vsftpd.
The status can be observed as follows:
vsftpd.service - Vsftpd ftp daemon
Loaded: loaded (/usr/lib/systemd/system/vsftpd.service; disabled; vendor preset: disabled)
Active: active (running) since Tue 2019-08-13 22:52:06 UTC; 29min ago
Process: 22076 ExecStart=/usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf (code=exited, status=0/SUCCESS)
Main PID: 22077 (vsftpd)
CGroup: /system.slice/vsftpd.service
└─22077 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.confStep 7: Run a Test with FTP Client
Finally, run a test with the FTP client to test the FTP service. Start by authentication of the FTP user account using the following script:
ftp 18.236.230.74
Connected to 18.236.230.74.
220 (vsFTPd 3.0.2)
Name (18.236.230.74): ftpuser1
331 Please specify the password.
Password:
230 Login successful.
ftp>After successful authentication, switch to passive mode before performing the FTP upload and carry out the test as shown:
ftp> passive
Passive mode on.
ftp> cd files
250 Directory successfully changed.
ftp> put mp3data
227 Entering Passive Mode (18,236,230,74,173,131).
150 Ok to send data.
226 Transfer complete.
131968 bytes sent in 0.614 seconds (210 kbytes/s)
ftp>
ftp> ls -la
227 Entering Passive Mode (18,236,230,74,181,149).
150 Here comes the directory listing.
drwxrwxrwx 1 0 0 0 Jan 01 1970 .
dr-xr-xr-x 3 65534 65534 19 Oct 25 20:17 ..
-rw-r--r-- 1 1001 1001 131968 Oct 25 21:59 mp3data
226 Directory send OK.
ftp>Terminate the FTP session after removing the remote files using ftp> del mp3dataftp> quit to now proceed with the configuration of the S3FS mount.
Step 8: Initiate S3FS and Mount Directory
Implement the following script which involves bucket specifications and security specifications to initiate and launch S3FS:
EC2METALATEST=http://169.254.169.254/latest &&
EC2METAURL=$EC2METALATEST/meta-data/iam/security-credentials/ &&
EC2ROLE=`curl -s $EC2METAURL` &&
S3BUCKETNAME=ca-s3fs-bucket &&
DOC=`curl -s $EC2METALATEST/dynamic/instance-identity/document` &&
REGION=`jq -r .region <<< $DOC`
echo "EC2ROLE: $EC2ROLE"
echo "REGION: $REGION"
sudo /usr/local/bin/s3fs $S3BUCKETNAME
-o use_cache=/tmp,iam_role="$EC2ROLE",allow_other /home/ftpuser1/ftp/files
-o url="https://s3-$REGION.amazonaws.com"
-o nonemptyNow proceed with the debug process of the S3FS FUSE mounting with the following script if required:
sudo /usr/local/bin/s3fs ca-s3fs-bucket
-o use_cache=/tmp,iam_role="$EC2ROLE",allow_other /home/ftpuser1/ftp/files
-o dbglevel=info -f
-o curldbg
-o url="https://s3-$REGION.amazonaws.com"
-o nonemptyCheck the status of the S3FS process and ensure that it’s running as required. This can be done as shown:
ps -ef | grep s3fs
root 12740 1 0 20:43 ? 00:00:00 /usr/local/bin/s3fs
ca-s3fs-bucket -o use_cache=/tmp,iam_role=S3FS-Role,allow_other
/home/ftpuser1/ftp/files -o url=https://s3-us-west-2.amazonaws.comOnce verified, your system is good to go for trying out an end-to-end transfer.
Step 9: Run S3 FTPS to Perform File Transfer
Set up FTPS and proceed to carry out your file transfer. You can test the connection using clients like FileZilla. Once corroborated, you can check the configuration of your AWS S3 web console. Initiate FTP transfers from your user directory automatically to the configured Amazon S3 bucket. Thus, your connection can facilitate the upload and synchronization using FTP to Amazon S3.
Limitations of FTP S3 Integration using S3FS
- Requires significant time investment and technical knowledge to implement.
- Potential errors with manual implementation could lead to data loss.
- The lack of an update process could lead to incompatibility in long run.
Method 2: FTP S3 Integration using FTP/SFTP Clients
Using an FTP/SFTP Client that supports Amazon S3 is the final best approach to connect FTP/SFTP to Amazon S3. FileZilla, WinSCP, and Cyberduck are some instances of these clients. You will not need to configure anything on the server if the FTP client is also an S3 client.
Using FileZilla, an open-source platform
Use FileZilla, which is a free, open-source, and cross-platform FTP server/client. FTP, SFTP, and FTPS are supported by the FileZilla client, although only FTP and FTPS are supported by the server. With the Pro edition, FileZilla additionally supports AWS S3 (among other cloud storage), making it easy to FTP to Amazon S3.
You can set the host and utilize S3 as a protocol when configuring the FileZilla client.
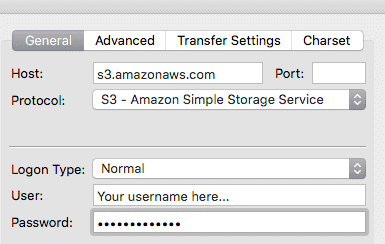
- It’s important to remember that you’re configuring a client, not a server. As a result, you’ll be able to view but not alter the data.
- Outside of public networks, FTP is not advised for file transfers. A reliable VPN for PC ensures secure data transfers and encrypted connections when accessing remote servers or cloud storage services. For security concerns, you’ll need to set up an FTP server for S3 inside a VPC (Virtual Private Cloud) or through a VPN. If you want to access files over the Internet, use FTPS (for FileZilla).
Method 3: Using Hevo
Step 1: Configure FTP as your Source

Step 2: Connect S3 as your Destination

How does Amazon S3 Transfer files?
The finest example of an object storage service is Amazon’s AWS S3 (Amazon Simple Storage Service). A single object in S3 might be anywhere from a few Kilobytes to a few Terabytes in size. Objects are categorized and stored in AWS S3 using a “buckets” structure.
S3 is a simple web services interface that allows you to store and retrieve any amount of data from anywhere at any time. The secure web-based protocol HTTPS and a REST Application Programming Interface (API), also known as RESTful API, are used to access S3.
With S3’s simple drag-and-drop tool, you may upload files, directories, or data.

Storage Units: FTP vs S3 Buckets
FTP and SFTP were created for transferring files, while Amazon S3 buckets were created for storing things. Although both are used for remotely sharing and storing data, they operate in different ways.
Files are transactional-based units for file-based storage. FTP and SFTP (SSH File Transfer Protocol) are file transfer protocols that access data in storage at the file level. They have access to files that are organized in a hierarchy of folders and files. Objects are another form of storage unit that includes the data, its associated (expandable and customizable) metadata, and a graphical user interface (GUI) (Globally Unique Identifier). A file, a subfile, or a collection of unconnected bits and bytes are all examples of objects. Objects are used in Amazon S3 buckets.

Blocks are a different sort of file format that is utilized in structured Database Storage and Virtual Machine File System (VMFS) volumes. The scope of this guide does not include blocks.
When it comes to storing large volumes of unstructured data, object storage surpasses file storage. Things are easy to access and deliver high stream throughput regardless of the amount of storage.
Cloud-based object storage, such as Amazon S3 buckets, scales significantly better than SFTP or FTP server storage in general.
Explore how to transfer data from SFTP/FTP to Redshift for enhanced integration. Our guide details the process for effective data migration.
Learn More About:
Easy Steps to SFTP S3 Integration
Conclusion
This article teaches you how to set up the FTP S3 Integration with ease. It provides in-depth knowledge about the concepts behind every step to help you understand and implement them efficiently. These methods, however, can be challenging, especially for a beginner.
What if you want to move your data from FTP to any other data warehouse? You can breathe a sigh of relief because Hevo Data is here to help. Connect with us today to improve your data management experience and achieve more with your data.
FAQ
How do I transfer data from FTP to S3?
You can transfer data from FTP to S3 by downloading the files from the FTP server to a local machine and then uploading them to S3 using the AWS CLI, AWS SDKs, or AWS Transfer for SFTP, which can automate the process.
Can you SFTP into S3?
Yes, AWS provides AWS Transfer Family, which allows you to use SFTP to transfer files directly into an S3 bucket. It provides managed file transfer capabilities into and out of S3 using SFTP, FTPS, and FTP protocols.
Which FTP client supports S3?
Several FTP clients support S3 as a protocol or destination, including Cyberduck, FileZilla Pro, and WinSCP. These clients allow you to manage and transfer files between your local machine, FTP servers, and S3.



