

Unlock the full potential of your Google Cloud Storage data by integrating it seamlessly with Redshift. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Are you looking for quick and simple methods to move data from Google Cloud Storage to Redshift? This is the article for you.
Businesses must now use their data to keep ahead of the expanding market competition and make data-driven choices. Data from multiple sources that automate processes must be stored quickly and securely. Furthermore, developing and managing a fast, versatile, and secure physical storage system is prohibitively expensive. As a result, Google Cloud storage solutions are becoming increasingly popular.
GCS provides a secure and low-cost virtual storage solution. However, consolidating numerous data silos to acquire business information is difficult. Furthermore, manual data integration is time-consuming, inconvenient, and sometimes erroneous. As a result, businesses seeking to reduce the time and effort spent reporting and analyzing many data silos combine a large number of data from numerous sheets, CSV files, and Gooogle Cloud Storage to Redshift or other such warehouses.
Table of Contents
What is Google Cloud Storage?

Google Cloud Storage is indeed an enterprise public cloud storage platform, which can hold enormous unstructured datasets. Companies might buy storage for their core or seldom-accessed data.
Customers can use a web browser or a command-line interface to access their data in Google Cloud Storage. Customers also can select the geographic region of their data.
Google Cloud Storage is a Google Cloud Platform service. It offers unified object storage for both current and archival data. Google Cloud Storage objects are classified into buckets. Buckets are cloud containers that may be allocated to different storage classes.


What are the Key Features of Google Cloud Storage?
Some key features of GCP include
- Capacity: Enough resources to allow for simple scalability as needed. Additionally, excellent resource management is required for peak performance.
- Security: Multi-level security choices for safeguarding resources such as assets, networks, and operating system components.
- Network Infrastructure: The collection of physical, logistical, and human-resource-related components that comprise a network, such as wire, routers, switches, firewalls, load balancers, and so on.
- Support: Skilled specialists for installation, maintenance, and support.
- Bandwidth: An appropriate quantity of bandwidth for peak load.
- Facilities: Other infrastructure components, such as physical equipment and power sources, are referred to as facilities.
What is Amazon Redshift?

Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It enables organizations to execute complex analytic queries against large datasets, delivering fast performance and scalability. By leveraging a Massively Parallel Processing (MPP) architecture, Redshift distributes and processes data across multiple nodes, ensuring efficient query execution. This design makes it suitable for diverse applications, including business intelligence, reporting, and data analytics.
A standout feature of Amazon Redshift is its serverless option, which allows users to run and scale analytics without provisioning and managing data warehouse clusters. With Redshift Serverless, resources are automatically provisioned, and capacity is intelligently scaled to deliver fast performance for even the most demanding and unpredictable workloads. This approach ensures that users pay only for what they use, eliminating the need for manual infrastructure management.
What are the Key Features of Amazon Redshift?
- Scalability and Performance: Redshift’s MPP architecture enables rapid scaling and high performance, allowing it to handle large datasets and complex queries efficiently.
- Managed Storage with RA3 Nodes: RA3 nodes allow users to optimize compute and storage independently, paying only for the managed storage used. This flexibility ensures cost-effective scaling based on performance requirements.
- Data Sharing: Redshift supports secure and live data sharing across different Redshift clusters, facilitating seamless collaboration and data access without the need for data movement or copying.
- Integration with Data Lakes: Redshift extends data warehouse queries to your data lake, allowing you to run analytic queries against petabytes of data stored locally in Redshift and directly against exabytes of data stored in Amazon S3.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s automated, No-code platform empowers you with everything you need to have for a smooth data replication experience.
Check out what makes Hevo amazing:
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built integrations for 100+ sources (with 40+ free sources) that can help you scale your data infrastructure as required.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Connect Google Cloud Storage to Redshift:
Method 1: Connect Google Cloud Storage to Redshift: Using Amazon EMR
1. Google Cloud Storage to Redshift: Prerequisites
The following conditions must be met before establishing the EMR cluster:
- On your PC or server, install the AWS Command Line Interface (AWS CLI). See Installing, updating, and uninstalling the AWS CLI for more.
- For SSH access to your EMR nodes, create an Amazon Elastic Compute Cloud (Amazon EC2) key pair. See Create a key pair with Amazon EC2 for details.
- Set up an S3 bucket to hold the configuration files, bootstrap shell script, and GCS connector JAR file. Create a bucket in the same Region as where you intend to deploy your EMR cluster.
- During the bootstrapping process, create a shell script (sh) to copy the GCS connector JAR file and the Google Cloud Platform (GCP) credentials to the EMR cluster’s local storage. Copy the shell script to your bucket at
s3:/S3 BUCKET>/copygcsjar.sh. An example shell script is as follows:
#!/bin/bash
sudo aws s3 cp s3://<S3 BUCKET>/gcs-connector-hadoop3-latest.jar /tmp/gcs-connector-hadoop3-latest.jar
sudo aws s3 cp s3://<S3 BUCKET>/gcs.json /tmp/gcs.json- To read files from GCS, download the GCS connector JAR file for Hadoop 3.x (if using a different version, you must obtain the JAR file for your version).
s3:/S3 BUCKET>/gcs-connector-hadoop3-latest.jaris the location where the file should be uploaded.- Create GCP credentials for a service account with access to the original GCS bucket. The credentials should be called json and should be in JSON format.
- Import the key here to
s3:/S3 BUCKET>/gcs.json. Here is an example key:
{
"type":"service_account",
"project_id":"project-id",
"private_key_id":"key-id",
"private_key":"-----BEGIN PRIVATE KEY-----nprivate-keyn-----END PRIVATE KEY-----n",
"client_email":"service-account-email",
"client_id":"client-id",
"auth_uri":"https://accounts.google.com/o/oauth2/auth",
"token_uri":"https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url":"https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url":"https://www.googleapis.com/robot/v1/metadata/x509/service-account-email"
}- To activate the GCS connection in Amazon EMR, create a JSON file called
gcsconfiguration.json. Ensure the file is in that directory as the AWS CLI commands you want to run. A sample configuration file is provided below:
[
{
"Classification":"core-site",
"Properties":{
"fs.AbstractFileSystem.gs.impl":"com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS",
"google.cloud.auth.service.account.enable":"true",
"google.cloud.auth.service.account.json.keyfile":"/tmp/gcs.json",
"fs.gs.status.parallel.enable":"true"
}
},
{
"Classification":"hadoop-env",
"Configurations":[
{
"Classification":"export",
"Properties":{
"HADOOP_USER_CLASSPATH_FIRST":"true",
"HADOOP_CLASSPATH":"$HADOOP_CLASSPATH:/tmp/gcs-connector-hadoop3-latest.jar"
}
}
]
},
{
"Classification":"mapred-site",
"Properties":{
"mapreduce.application.classpath":"/tmp/gcs-connector-hadoop3-latest.jar"
}
}
]
2. Google Cloud Storage to Redshift: Start Amazon EMR and set it up.
We begin with a simple cluster of one primary node and four-core nodes for a total of five c5n.xlarge instances for our test dataset. To find the optimal cluster scale for your dataset, iterate on your copy workload by adding more core nodes and monitoring your copy job durations.
- To start and setup our EMR cluster, we utilize the AWS CLI (see the basic create-cluster command below):
aws emr create-cluster
--name "My First EMR Cluster"
--release-label emr-6.3.0
--applications Name=Hadoop
--ec2-attributes KeyName=myEMRKeyPairName
--instance-type c5n.xlarge
--instance-count 5
--use-default-roles- Create a custom bootstrap activity to copy the GCS connection JAR file and GCP credentials to the EMR cluster’s local storage upon cluster formation. To set your own bootstrap action, add the following option to the create-cluster command:
For more information on this phase, see Create bootstrap activities to install extra software.
- You must give a configuration object to alter the default configurations for your cluster. To specify the configuration item, add the following option to the create-cluster command:
For additional information on how to offer this object when constructing a cluster, see Configure apps when creating a cluster.
Putting it all together, the following code is an example of a command to create and set up an EMR cluster capable of doing GCS to Amazon S3 migrations
aws emr create-cluster
--name "My First EMR Cluster"
--release-label emr-6.3.0
--applications Name=Hadoop
--ec2-attributes KeyName=myEMRKeyPairName
--instance-type c5n.xlarge
--instance-count 5
--use-default-roles
--bootstrap-actions Path="s3:///copygcsjar.sh"
--configurations file://gcsconfiguration.json3. Google Cloud Storage to Redshift: As a step in an EMR cluster, submit S3DistCp or DistCp.
- There are various methods to execute the S3DistCp or DistCp utility.
When the cluster is up and running, SSH to the primary node and perform the command indicated in this post in a terminal window.
The work can also be started as part of the cluster launch. After the job is completed, the cluster can either continue to operate or be halted. This may be accomplished by submitting a step directly through the AWS Management Console when forming a cluster. Please provide the following information:
- Step type – Custom JAR
- Name – S3DistCp Step
- JAR location – command-runner.jar
- Arguments – s3-dist-cp –src=gs://<GCS BUCKET>/ –dest=s3://<S3 BUCKET>/
- Action of failure – Continue
We can always add a new step to the current cluster. The syntax in this example differs somewhat from that in earlier instances. We use commas to separate arguments. In the event of a complicated pattern, we use single quote marks to protect the entire step option:
aws emr add-steps
--cluster-id j-ABC123456789Z
--steps 'Name=LoadData,Jar=command-runner.jar,ActionOnFailure=CONTINUE,Type=CUSTOM_JAR,Args=s3-dist-cp,--src=gs://<GCS BUCKET>/, --dest=s3://<S3 BUCKET>/'4. Google Cloud Storage to Redshift: DistCp configuration and parameters
We improve the cluster copy throughput in this section by modifying the number of maps or reducers and other associated variables.
- Memory configurations
We employ the following memory configurations:-Dmapreduce.map.memory.mb=1536<br>-Dyarn.app.mapreduce.am.resource.mb=1536
The size of the map containers used to parallelize the transfer is determined by both parameters. Setting this value in accordance with the cluster resources and the amount of declared maps is critical for guaranteeing effective memory consumption. The following formula can be used to compute the number of launched containers:Total number of launched containers = Total memory of cluster / Map container memory
- Dynamic strategy configurations
We employ the following dynamic strategy parameters:-Ddistcp.dynamic.max.chunks.tolerable=4000<br>-Ddistcp.dynamic.split.ratio=3 -strategy dynamic
DistCp splits the copy task into dynamic chunk files based on the dynamic strategy options. Each of these pieces represents a subset of the original file listing. The map containers then draw pieces from this pool. If a container completes its task early, it may be assigned to another unit of work. This ensures that containers complete the copy operation faster and complete more work than slower containers. Split ratio and max chunks tolerated are the two configurable options. The split ratio controls how many chunks are generated from the number of maps. The max chunks acceptable parameter specifies the maximum number of chunks that can be allowed. The ratio and number of defined maps decide the setting:Number of chunks = Split ratio * Number of maps<br>Max chunks tolerable must be > Number of chunks
- Map options
The following map setup is used:-m 640
This specifies how many map containers will be launched.
- List status options
The following list status setting is used:-numListstatusThreads 15
The number of threads used to do the file listing of the source GCS bucket.
- An example command
When operating with 96 core or task nodes in the EMR cluster, use the following command:hadoop distcp<br>-Dmapreduce.map.memory.mb=1536 <br>-Dyarn.app.mapreduce.am.resource.mb=1536 <br>-Ddistcp.dynamic.max.chunks.tolerable=4000 <br>-Ddistcp.dynamic.split.ratio=3 <br>-strategy dynamic <br>-update <br>-m 640 <br>-numListstatusThreads 15 <br>gs://<GCS BUCKET>/ s3://<S3 BUCKET>/
5. Google Cloud Storage to Redshift: S3DistCp options and settings
When performing massive GCS copies using S3DistCP, ensure that the option fs.gs.status.parallel.enable (also mentioned previously in the sample Amazon EMR application configuration object) is set in core-site.xml. This aids in parallelizing the getFileStatus and listStatus functions in order to decrease the latency associated with file listing. You may also change the number of reducers to get the most out of your cluster. When operating with 24 core or task nodes in the EMR cluster, use the following command:
s3-dist-cp -Dmapreduce.job.reduces=48 --src=gs://<GCS BUCKET>/--dest=s3://<S3 BUCKET>/
- Performance and testing
We utilized a 9.4 TB (157,000 files) test dataset stored in a multi-Region GCS bucket to evaluate DistCp’s performance with S3DistCp. The EMR cluster and the S3 bucket were both situated in us-west-2. The number of core nodes employed in our tests ranged from 24 to 120.
The DistCp test yielded the following results:- Workload – 9.4 TB and 157,098 files
- Instance types – 1x c5n.4xlarge (primary), c5n.xlarge (core)
| Nodes | Throughput | Transfer Time | Maps |
| 24 | 1.5GB/s | 100 mins | 168 |
| 48 | 2.9GB/s | 53 mins | 336 |
| 96 | 4.4GB/s | 35 mins | 640 |
| 120 | 5.4GB/s | 29 mins | 840 |
- The following are the results of the S3DistCp test:
- Workload – 9.4 TB and 157,098 files
- Instance types – 1x c5n.4xlarge (primary), c5n.xlarge (core)
| Nodes | Throughput | Transfer Time | Reducers |
| 24 | 1.9GB/s | 82 mins | 48 |
| 48 | 3.4GB/s | 45 mins | 120 |
| 96 | 5.0GB/s | 31 mins | 240 |
| 120 | 5.8GB/s | 27 mins | 240 |
For our test dataset, the findings reveal that S3DistCP performed somewhat better than DistCP. In terms of node count, we stopped at 120 nodes since we were pleased with the copy’s performance. If your dataset requires it, increasing the number of nodes may result in greater performance. It is necessary to loop over your node counts in order to obtain the correct number for your dataset.
- Spot Instances are used for task nodes.
Amazon EMR supports the capacity-optimized allocation approach for EC2 Spot Instances by monitoring capacity measurements in real-time and launching Spot Instances from the most available Spot Instance capacity pools. In your EMR task instance fleet settings, you may now define up to 15 instance types. See Optimizing Amazon EMR for Resilience and Cost with Capacity-Optimized Spot Instances for further details.
- Clean it up
Make careful to destroy the cluster when the copy operation is finished, unless the copy job was a stage in the cluster launch and the cluster was configured to cease automatically after the copy job was completed.
Method 2: Using a No-Code ETL Tool Hevo
Step 1: Configure GCS as a Source
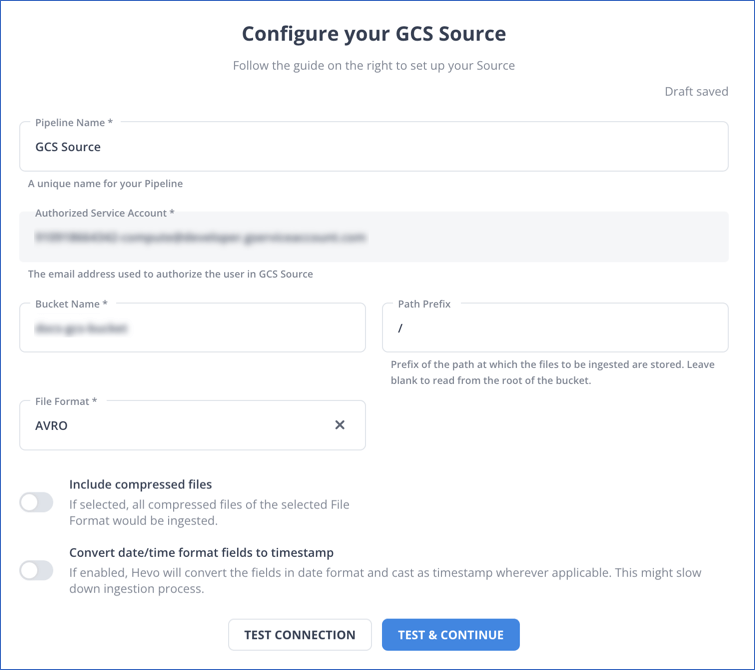
On the Configure your GCS Source page, specify the following:
Step 2: Configure Redshift as a Destination
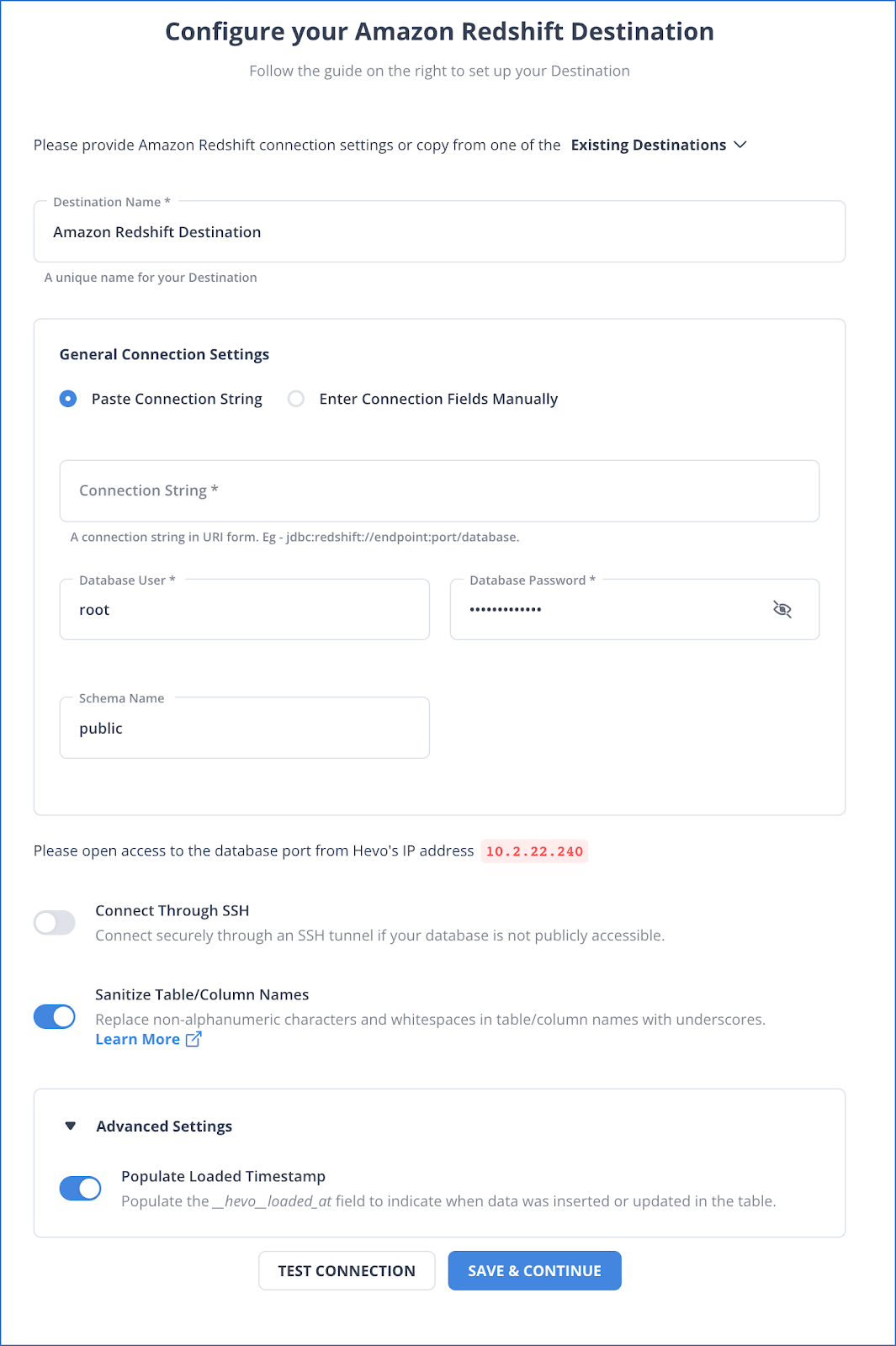
On the Configure your Amazon Redshift Destination page, specify the following:
With these two simply and easy steps you have successfully connected your google cloud storage to redshift data pipeline using Hevo.
Google Cloud Storage to Redshift: Conclusion
In this article, we’ve explored both Google Cloud Storage and Amazon Redshift, highlighting their key features and the steps required to seamlessly migrate data between them. By leveraging Redshift’s robust performance and scalability, combined with the cloud flexibility of Google Cloud Storage, you can build an efficient, analytics-ready data pipeline.To make this process even more streamlined, Hevo Data offers an easy-to-use platform with seamless integration across 150+ sources, allowing you to not only migrate your data but also transform and enrich it in real-time.
With Hevo’s no-code interface, you can set up pipelines in minutes and focus on deriving valuable insights rather than managing infrastructure. Experience Hevo Data firsthand with a 14-day free trial, and explore flexible pricing plans tailored to suit your specific business needs. Start simplifying your data integration journey today!
Frequently Asked Questions
1. What is the S3 equivalent in GCP?
The equivalent of Amazon S3 (Simple Storage Service) in Google Cloud Platform (GCP) is Google Cloud Storage.
2. What format does Redshift store data in?
Amazon Redshift stores data in a columnar format. This columnar storage format is optimized for complex queries and large-scale data processing, as it allows Redshift to read only the columns needed for a query, improving performance.
3. Can we load data from S3 to Redshift?
Yes, you can load data from Amazon S3 into Amazon Redshift.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





