

Debezium is the database monitoring platform that continuously captures and streams all real-time modifications updated on the respective database systems like MySQL and PostgreSQL.
Usually, developers use CLI tools like the default command prompt terminal to work with Debezium, which is the traditional way of setting up the Debezium workspace.
To begin working with Debezium, you have to set up and start four different services such as Kafka server, Zookeeper instance, Debezium connector service, and Kafka Connect platform. Running Debezium on Red hat OpenShift optimizes solutions.
However, starting all the services separately is a time-consuming process. To eliminate such complications, you can use containerization platforms to run all the above-mentioned services in the form of docker images.
One such containerization service is Red Hat OpenShift, which allows you to run and deploy the Docker container images that comprise all the necessary services to get started with a specific application.
In this article, you will learn about Debezium, Red Hat OpenShift, and how to run Debezium on the Red hat OpenShift container platform.
Table of Contents
Prerequisites
A fundamental of databases and real-time data streaming.
What is Debezium?

Debezium is an open-source and distributed platform exclusively built for implementing the CDC (Change Data Capture) approach. The Debezium platform is built on top of the Apache Kafka ecosystem, which captures and streams real-time changes from external RDBMS applications like Microsoft SQL Server, Oracle, PostgreSQL, and MySQL. Since Debezium is built on Kafka, it streams all the real-time row-level updates and modifications of specific databases into Kafka servers.
Debezium continuously updates the history of changes in Kafka logs inside Kafka servers. It provides you with a set of connectors in which each connector captures real-time changes from the respective databases.
For example, the Debezium MySQL connector streams real-time changes from the database, while the Debezium Oracle connector captures modifications from the Oracle database.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo and discover why 2000+ customers, such as Postman and ThoughtSpot, have chosen Hevo over tools like Debezium to upgrade to a modern data stack.
Get Started with Hevo for FreeWhat is Red Hat OpenShift

Developed by Red Hat in 2011, OpenShift is a cloud-based platform that allows you to run containerized applications and workloads. In other words, OpenShift is a cloud-based container PaaS (Platform as a Service) that enables users to develop, deploy, and manage end-to-end applications. Since Red Hat maintains the OpenShift platform at a backend, it provides you with complete support regardless of where you choose to run and deploy your application or workloads. With Red Hat OpenShift, you can flexibly develop, deploy, and scale applications on both on-premises and cloud infrastructure.
Steps to run Debezium on Red Hat OpenShift
1. Debezium on Red Hat OpenShift: Downloading OpenShift CLI
To run Debezium on Red Hat OpenShift, you should satisfy two prerequisites. You should readily have an OpenShift CLI (Command Line Interface) and Docker.
- For downloading OpenShift CLI for Debezium on Red Hat OpenShift, visit the Infrastructure Provider page of the Red Hat OpenShift cluster manager site with your Red Hat login ID. Select your appropriate infrastructure provider.
- Now, in the command line interface section, select your system OS type, in this case, Windows, from the drop-down menu. After choosing the respective OS, click on the “Download command-line tools” button.
- Now, the CLI tool is downloaded to your local machine and can be used for the next steps of Debezium on Red Hat OpenShift. Unzip the setup file of the CLI tool and move the “oc” binary file to your preferred file path.
- After moving the OpenShift CLI tool to your preferred directory, you are now ready to run OpenShift commands for Debezium on Red Hat OpenShift by following the below-given syntax.
C:> oc <command>- Before executing commands for Debezium on Red Hat OpenShift, you have to log in to the oc (OpenShift CLI) for managing the OpenShift cluster. For logging in with oc, you should readily have a cluster in the OpenShift Container Platform.
- Execute the following command to log in with oc.
$ oc login- Then, enter the web URL of the OpenShift Container Platform.

- In the next step of Debezium on Red Hat OpenShift, you are prompted to decide whether to use insecure connections or not. As shown in the image above, answer with yes or no (Y/N) in your command prompt.
- Then, enter the respective user name and password of OpenShift CLI. Now, you are successfully logged in with OpenShift CLI.
Following the above-given steps, you successfully installed and configured the OpenShift CLI. In the further steps of Debezium on Red Hat OpenShift, you will use the OpenShift CLI as the command terminal to manage projects and clusters of your OpenShift Container Platform.
2. Debezium on Red Hat OpenShift: Running Debezium on Red Hat OpenShift
- Initially, you have to install the necessary operators and templates by cloning the GitHub repository of strimzi. Strimzi provides various operators and templates for managing the Kafka clusters running at any container platforms like OpenShift and Kubernetes.
- For exporting the preferred Strimzi version for Debezium on Red Hat OpenShift, open your OpenShift CLI and execute the following command.
export STRIMZI_VERSION=0.18.0- After exporting, execute the command below to clone the Strimzi operators and templates from the GitHub repository.
git clone -b $STRIMZI_VERSION https://github.com/strimzi/strimzi-kafka-operator- Then, change the directory to “strimzi-kafka-operator” by executing the below command.
cd strimzi-kafka-operator- Now, switch to the admin user and install the operators and templates for managing the Kafka cluster.
oc login -u system:admin
oc create -f install/cluster-operator && oc create -f examples/templates/cluster-operator- In the next step, execute the following command to deploy a Kafka broker cluster.
oc process strimzi-ephemeral -p CLUSTER_NAME=broker -p ZOOKEEPER_NODE_COUNT=1 -p KAFKA_NODE_COUNT=1 -p KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 -p KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1 | oc apply -f -- On executing the above command, you created a single instance of Kafka broker and a Kafka topic with a single replication factor.
- In the next step, you will create a Kafka Connect docker image containing pre-installed Debezium connectors. Initially, you have to download and extract the respective Debezium connector you want to run on OpenShift.
- In this case, since you are running Debezium’s MySQL connector on the OpenShift platform, you have to particularly download the Debezium MySQL connector.
- Run the following command to download and extract the Debezium MySQL connector.
curl https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.8.1.Final/debezium-connector-mysql-1.8.1.Final-plugin.tar.gz tar xvz- Now, create a Docker file that contains the base image as Strimzi Kafka. Execute the following command to include the previously downloaded Debezium MySQL connector into the Docker file.
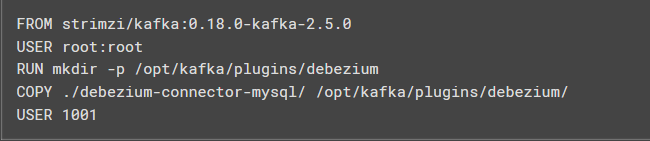
- On running the above command, you created the plugins/debezium directory that contains separate folders for each Debezium connector that you run on the OpenShift platform.
- Now, build the Debezium image from the previously created Docker file and push it into your own Docker container registry or platform. Execute the following command to implement the pushing process.
export DOCKER_ORG=debezium-community
docker build . -t ${DOCKER_ORG}/connect-debezium
docker push ${DOCKER_ORG}/connect-debezium- In the above command, you can replace debezium-community with your docker hub registry name.
- Now, you can check the status of the running instances from your Docker container. Execute the command given below to view the active status.
oc get pods- On executing the above command, you get the output as shown below.
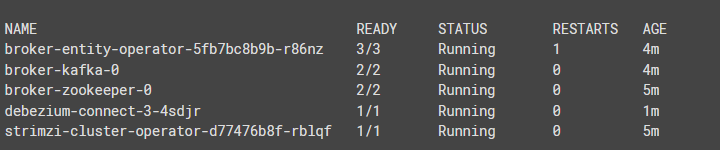
- From the above image, you can conclude that all the instances that belong to Docker containers are running successfully.
- You can also see the active status of instances from your OpenShift web GUI.
- Navigate to the “Pods” view in the OpenShift web console or follow the link to check the status of your instances.

- Your OpenShift web console resembles the above image, in which you can see the status of instances and their age (the exact amount of time since when the respective instances were created).
- Now, you can check whether the Debezium MySQL connector is working properly on the OpenShift platform.
- In the OpenShift CLI, execute the following command to start the MySQL database.
oc new-app --name=mysql debezium/example-mysql:1.8- After starting the database, you have to set the appropriate credentials for the MySQL instance.
oc set env dc/mysql MYSQL_ROOT_PASSWORD=debezium MYSQL_USER=mysqluser MYSQL_PASSWORD=mysqlpw- On executing the above-given command, run the oc get pods command to check the status of the newly created MySQL instance.

- The output will resemble the above image, which confirms your MySQL instance is running successfully.
- In the next step, you have to register the Debezium MySQL connector to run in the previously created MySQL instance.
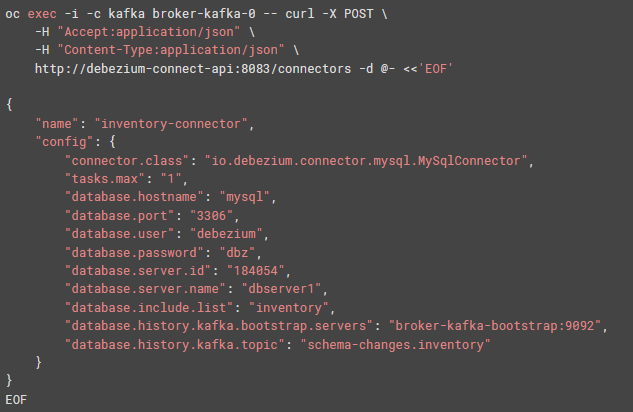
- Now, the Debezium connector is ready to read or capture the change of events from the corresponding Customer table in the Kafka server. Execute the following command to read changes.
oc exec -it broker-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --property print.key=true --topic dbserver1.inventory.customers- On running the above command, the change of events captured by the connector is in the format, as shown below, where the output follows the JSON format having the key-value pair.

On executing the above-mentioned steps, you successfully installed, configured, and executed Debezium on Red Hat OpenShift.

Conclusion
In this article, you learned about Debezium, Red Hat OpenShift, and how to create OpenShift CLI to run Debezium on the Red Hat OpenShift platform. This article primarily focused on running Debezium connector instances on OpenShift using the OpenShift CLI.
However, you can also use the web GUI or interface of the Red Hat OpenShift platform to install and manage Debezium connectors and operators.
MongoDB and PostgreSQL are trusted sources that many companies use as it provides many benefits, but transferring data from it into a data warehouse is a hectic task.
Frequently Asked Questions
Where does Debezium run?
Debezium can run in various environments, including on-premises, in virtual machines, or in containerized environments like Docker and Kubernetes. It’s typically deployed alongside Apache Kafka, as it relies on Kafka to stream change data captured from source databases to target systems.
How to install Ansible Tower on Red Hat OpenShift?
To install Ansible Tower on Red Hat OpenShift, follow these steps:
1. Prepare the OpenShift Cluster: Ensure you have access to an OpenShift cluster and appropriate permissions.
2. Download Ansible Tower: Get the installation files from the Ansible Tower website.
3. Create a new project in OpenShift: Deploy Ansible Tower using a YAML deployment file or OpenShift templates.
4. Run the Installer: Use the oc command-line tool to deploy the application, applying the necessary configurations for networking and storage.
Can I use Debezium without Kafka?
Debezium is primarily designed to work with Apache Kafka, as it captures changes from databases and streams them into Kafka topics. While technically possible to capture data changes without Kafka, using Debezium without Kafka would lose much of its intended functionality and benefits related to event streaming and processing.
What is the working of Debezium?
Debezium captures data changes from databases using change data capture (CDC). It listens to the database’s transaction log, identifies changes (inserts, updates, deletes), and produces change events that are published to Kafka topics. Applications can then consume these events to react to data changes in real time, enabling various use cases like replication, auditing, and data synchronization.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



