



Every data-centric organization uses a data lake, warehouse, or both data architectures to meet its data needs. Data Lakes bring flexibility and accessibility, whereas warehouses bring structure and performance to the data architecture.
How about a unified data architecture that combines the flexibility and accessibility of a data lake with the structure and performance of a warehouse? This is precisely what we will be discussing in this article. Just a spoiler, this unified data architecture is termed a data lakehouse. We will also discuss how to ingest operational data into an Apache Iceberg lakehouse.
Let’s dive in!
Table of Contents
What is a Data Lakehouse?
A Lakehouse is a modern approach to designing a data architecture that blends the features of a data lake and a data warehouse to overcome their shortcomings. Technically, it started as a data lake and was then built up by the structure and restrictions of a data warehouse, giving users the “best of both worlds.” The lakehouse’s data storage stores data in a raw, unaltered, and native format like a data lake and has built-in warehouse elements like schema enforcement and indexing.
Understanding the Basics
Let’s restart from the very basics.
When storing data in the data lake as immutable objects, we lose various features that traditional databases guarantee, such as CRUD transactionality. We have to rewrite the entire file/object whenever any transaction to data entry in that particular file is made. This becomes more difficult and inefficient when thousands to millions of files are involved.
So, how do we bring back transactionality and other database-like features onto the data lake? This is where Open Table formats(OTFs) like Iceberg come into play. There are other OTFs like Apache Hudi and Deltalake, but we will focus on Iceberg in this article.
Supercharge your data lakehouse with Hevo’s Apache Iceberg integration. Get efficient, flexible, and high-performance data management.
Why Apache Iceberg?
- Optimized Performance – Faster queries with minimal data scanning.
- Schema Evolution Made Easy – Modify tables without breaking your pipelines.
- ACID Compliance & Time Travel – Maintain consistency and roll back to any previous data state.
Start building a modern, scalable data lakehouse today with Hevo and Apache Iceberg.
Get Started with Hevo for FreeWhat is the Apache Iceberg?
Open Table Formats (OTFs) and Apache Iceberg are Modern Data Lake Table formats. Unlike the Hive Table format, they track table schema, partitions, and other metadata at the file level. This approach to defining a table provides features like ACID transactions, consistent reads, safe writes by multiple readers and writers simultaneously, time travel, easy schema evolution without rewriting the entire table, and many more.
Iceberg is a high-performance open-table format for tables with huge amounts of data. Iceberg brings the reliability and simplicity of SQL database tables into big data while making it possible for independent query and processing engines like Spark, Trino, Flink, Presto, Hive, and Impala to work with the same tables, simultaneously.
But why ICEBERG?
1. Expressive SQL
Data users can interact with Apache Iceberg using their favorite language, SQL.
Using SQL commands, new data can be merged with existing data, existing rows can be updated, and targeted deletions can be performed. As the engineers configure it, Iceberg can rewrite data files for read performance or use delete deltas for faster updates.
sql> MERGE INTO prod.sales.campaign st
USING (SELECT * FROM staging.sales.campaign) sst
ON st.id = sst.id
WHEN NOT MATCHED THEN INSERT *;2. Full Schema Evolution
Schema evolution works. Adding a column won’t bring back “zombie” data. Columns can be renamed and reordered. Best of all, schema changes never require rewriting your table.
ALTER TABLE sales
ALTER COLUMN sale_campaign
TYPE double;ALTER TABLE sales
ALTER COLUMN sale_campaign
AFTER sale_date;ALTER TABLE sales
RENAME COLUMN sale_campaign
TO sale_campaing_modified;3. Hidden Partitioning
Iceberg automatically handles the tedious and error-prone task of producing partition values for rows and skips unnecessary partitions and files. This results in faster queries without extra filters, and the table layout can be updated as data or queries change.
4. Time Travel and Rollback
A snapshot of the iceberg table is stored in the metadata layer across timestamps and thus can be used to query the data as of any particular timestamp snapshot. This helps users query any version of the snapshot and examine changes. Users can also roll back to a working data version and move the data lake to a good state.
SELECT count(*) FROM prod.sales;SELECT count(*) FROM prod.sales FOR VERSION AS OF 2188465307835585443;SELECT count(*) FROM prod.sales FOR TIMESTAMP AS OF TIMESTAMP '2022-01-01 00:00:00.000000 Z';5. Data Compaction
Data compaction is supported out of the box, and you can choose from different rewrite strategies, such as bin-packing or sorting, to optimize file layout and size.
CALL system.rewrite_data_files("prod.sales");An Iceberg Table’s Architecture:
Apache Iceberg table has three layers – Catalog Layer, Metadata Layer, and Data Layer.
Let us discuss what each layer signifies:
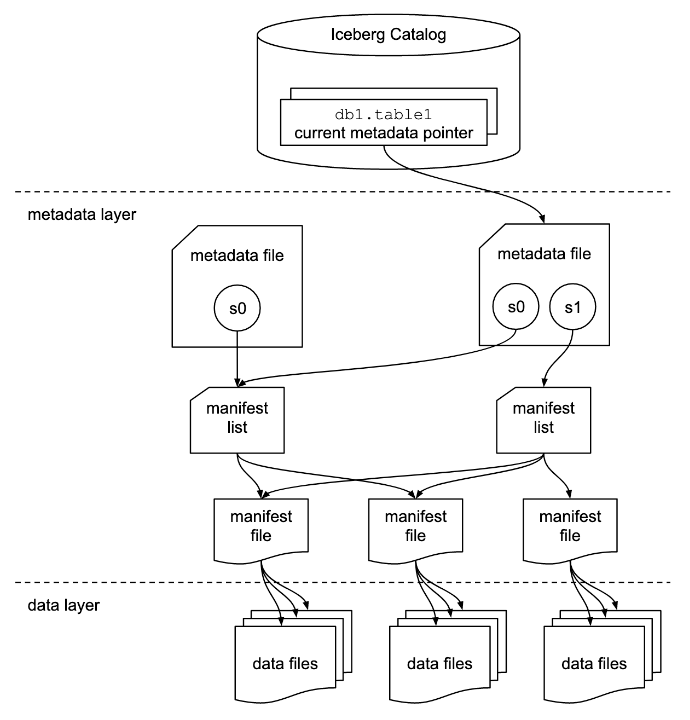
Catalog Layer:
The catalog layer stores a reference or a pointer to the current metadata file for the iceberg tables. The diagram shown above shows two metadata files.
The most recent metadata file is the one on the right, and it is stored in the table’s current metadata pointer.
Metadata Layer:
This layer has all the metadata files related to iceberg tables in a tree structure to track the data files and their metadata, along with the details of all the operations made on them.
This layer contains three file types:
- Manifest Files:
Manifest files keep track of files in the data layer and provide statistics for each file in AVRO file format.
- Manifest Lists:
Manifest lists files track manifest files, including the location and partition they belong to, and the upper and lower bound for partition columns for the data it tracks, in Avro file format.
- Metadata Files:
Metadata files keep track of Manifest Lists. These files accumulate metadata about the iceberg tables at a certain point in time, such as the table’s schema, partition information, snapshots, and which snapshot is the current one.
All this information is stored in a JSON format file.
Data Layer:
This is the layer where the actual data for the iceberg tables is stored. It is primarily made of data files. Data practitioners can choose from various file types for this layer, such as Apache Parquet, Apache ORC, and Apache Avro.
Now, we understand why we should use an iceberg and how an iceberg table is constructed. We are ready to start building some analytics lakehouse using on-top-of-iceberg tables:
Batch Ingestion into Apache Iceberg Lakehouse
Apache Iceberg supports both batch and streaming ingestion. Let us look into an example of batch ingestion first:
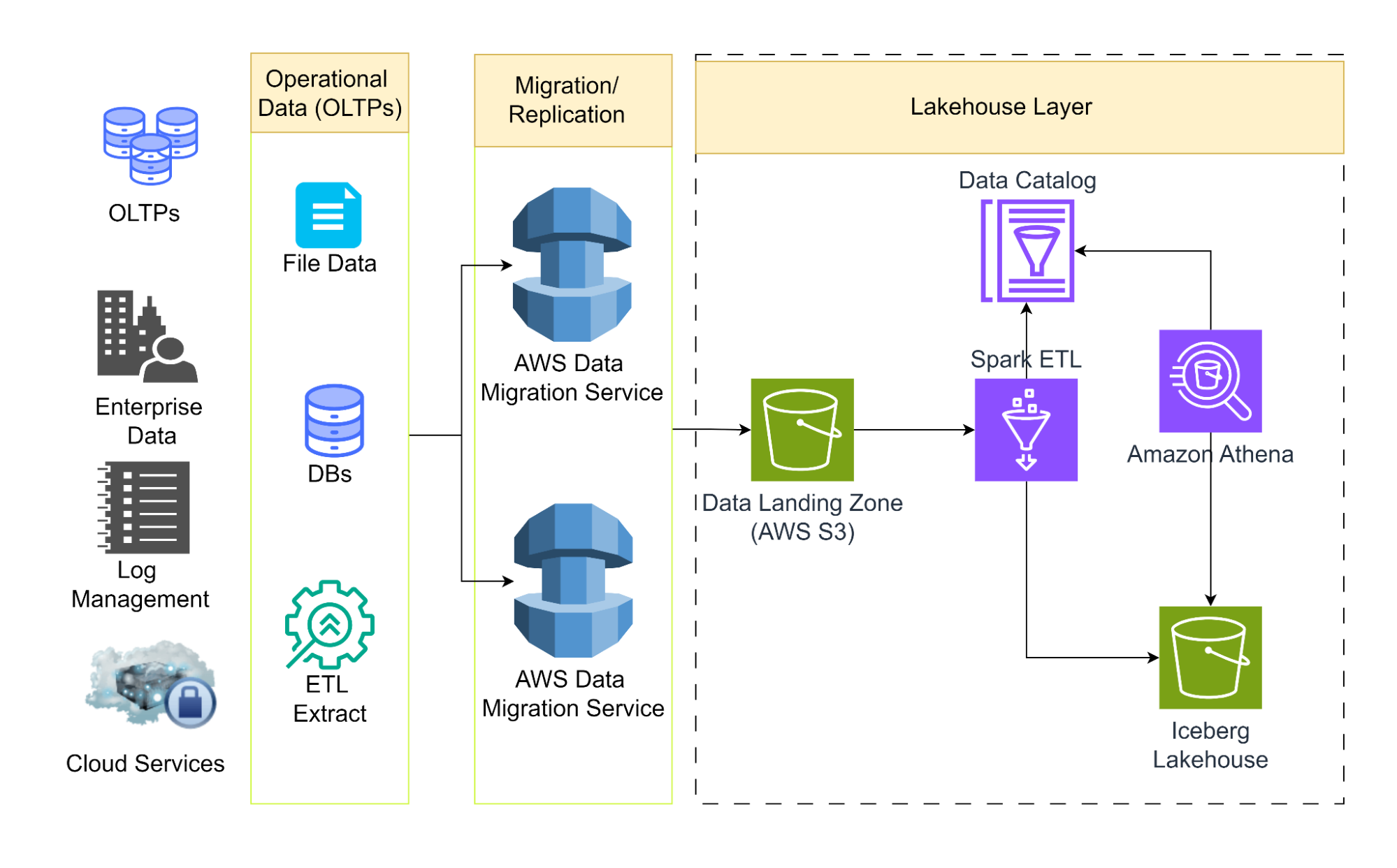
Pre-requisites
Programming Language:
- Python
- SQL
- Spark (Structured Streaming)
Tools & Packages:
- Boto3 (AWS library for Python)
Step 1: Create an AWS Data Migration/Replication job to replicate OLTPs to the S3 data lake.
When a replication job is created on the AWS Data Migration service, data from different OLTP sources is ingested into an S3 data lake.
Step 2: Create a catalog on Glue Data Catalog.
Create and run a glue crawler to populate the Glue data catalog with the metadata of the data lake. Glue jobs make use of the catalog for downstream ETL processes.
Step 3: Create a Glue job to ETL/ELT on Iceberg Lakehouse
AWS Glue is a go-to tool for data engineers to run on-demand ETL/ELT Spark jobs. Apache Iceberg framework is supported by AWS Glue 3.0 and later. Using the Spark engine, we can use AWS Glue to perform various operations on the Iceberg Lakehouse tables, from read and write to standard database operations like insert, update, and delete.
- Enabling the Iceberg on AWS Glue Spark Job
- Specify a glue job parameter, –datalake-formats with value
iceberg. - Create a key named –conf for the AWS Glue job with following value
- Specify a glue job parameter, –datalake-formats with value
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
--conf spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.glue_catalog.warehouse=s3://<your-warehouse-dir>/
--conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog
--conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIOIf we need to use AWS Glue 3.0 with Iceberg 0.13.1, we must set additional configurations to use the Amazon DynamoDB lock manager to ensure an atomic transaction.
--conf spark.sql.catalog.glue_catalog.lock-impl=org.apache.iceberg.aws.glue.DynamoLockManager
--conf spark.sql.catalog.glue_catalog.lock.table=<your-dynamodb-table-name>- Read from the data lake using Spark:
Create a temporary spark view to further use in the iceberg query.
from awsglue.context import GlueContext
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
df = glueContext.create_data_frame.from_catalog(
database="<your_database_name>",
table_name="<your_table_name>",
additional_options=additional_options
)
df.createOrReplaceTempView('temp_table')- Create an Iceberg table on top of Amazon S3 and register it to the AWS Glue Data Catalog.
Using Spark SQL API, use the glue temp view to write data to an iceberg table.
dataFrame.createOrReplaceTempView(‘temp_table’)
query = f"""
CREATE TABLE glue_catalog.<your_database_name>.<your_table_name>
USING iceberg
TBLPROPERTIES ("format-version"="2")
AS SELECT * FROM tmp_<your_table_name>
"""
spark.sql(query)Now that the data is ingested into an iceberg table, we can read the data either using spark:
dataFrame = spark.read.format("iceberg").load("glue_catalog.databaseName.tableName")We can also read the data using Amazon Athena, which uses the Presto engine under the hood and SQL Queries.
SELECT * from glue_catalog.databaseName.tableName;Stream Ingestion into Apache Iceberg Lakehouse.
Apache Iceberg supports real-time data ingestion using various streaming sources and connectors. Apache Kafka and Amazon Kinesis are popular data streaming sources in a streaming data architecture. Spark structured streaming is a processing engine that reads data from the stream and writes to Iceberg tables.
Let us discuss some real-time data ingestion architectures with Iceberg tables in action:
Reading and Writing Stream data from AWS MSK using Spark Streaming:
Iceberg supports processing incremental data in spark structured streaming jobs, which start from a historical timestamp.
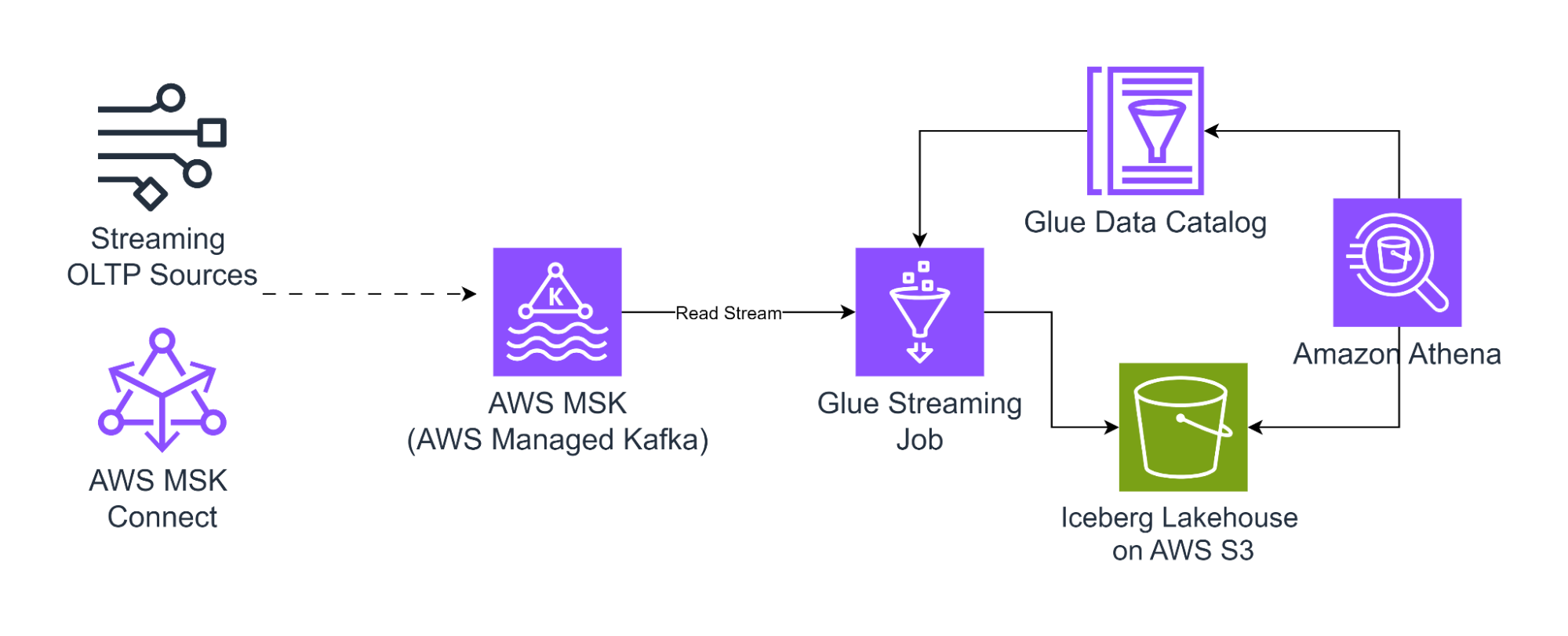
Prerequisites
Programming Language:
- Python
- SQL
- Spark (Structured Streaming)
Tools & Packages:
- Boto3 (AWS library for Python)
# reading stream using Spark Structured Streaming
df = spark.readStream
.format("iceberg")
.option("stream-from-timestamp", Long.toString(streamStartTimestamp))
.load("database.table_name")The following snippet of code of Spark Structured Streaming can be used to write data from the streaming query to an Iceberg table:
# Write the streaming dataframe to an iceberg table
df.writeStream
.format("iceberg")
.outputMode("append")
.trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES))
.option("checkpointLocation", checkpointPath)
.toTable("database.table_name")Reading and writing Streaming data from AWS Kinesis to Iceberg tables using AWS Managed Flink Service.
AWS has a family of services for real-time streaming data ingestion known as Kinesis: Kinesis Data Stream for streaming ingestion and AWS Managed Flink (formally known as Kinesis Data Analytics) for real-time data processing. Let us discuss an example of streaming data from a WebSocket API into an iceberg table.
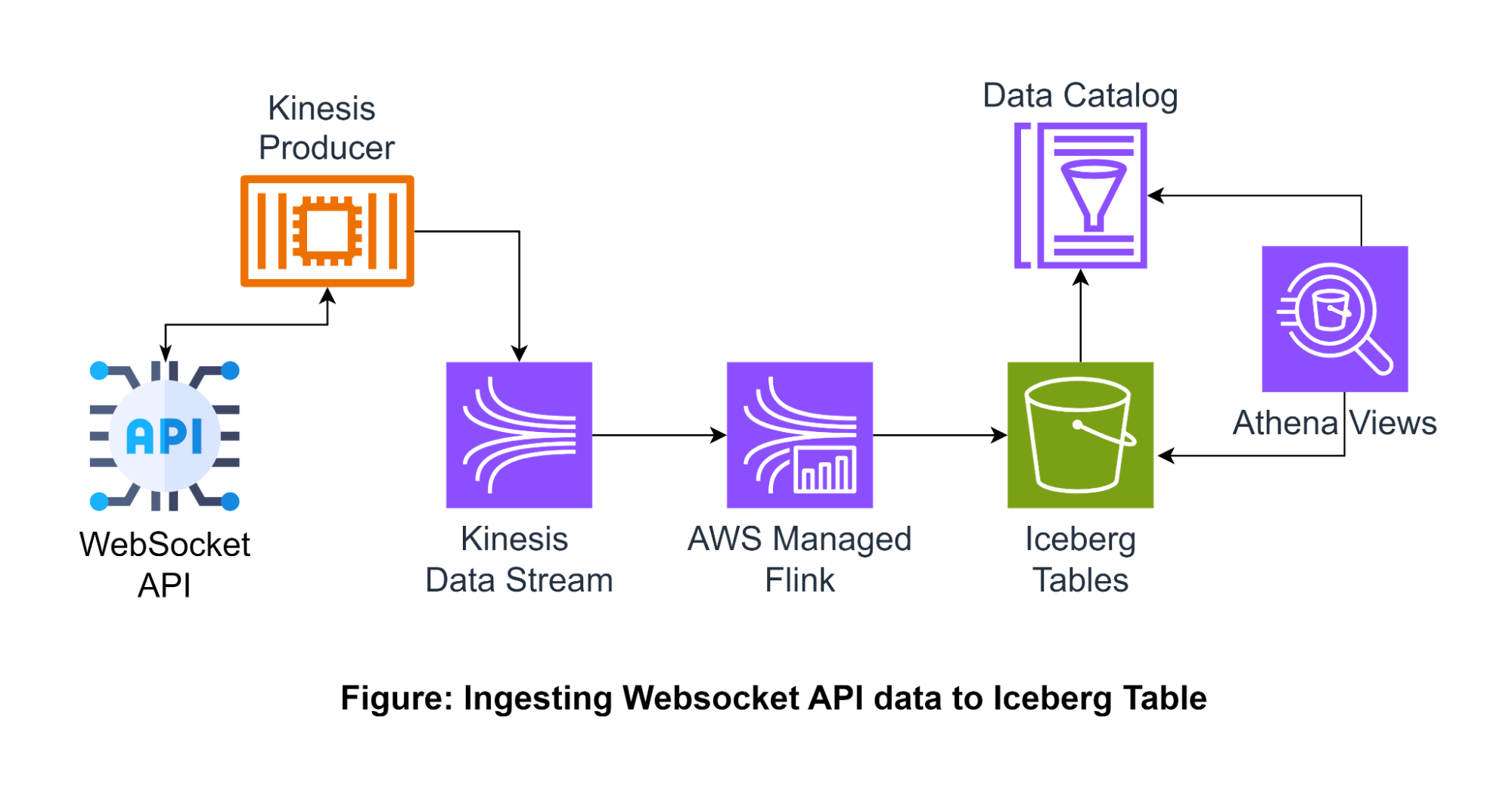
Pre-requisites
Programming Language:
- Python
- Java
- SQL
- KSQL (Streaming SQL)
Tools & Packages:
- Boto3 (AWS Library for Python)
Step 1: Create a Glue table for Iceberg Lakehouse
We can create the table using Flink SQL Table API:
String warehouse = "<WAREHOUSE>";
String db = "<DB>";
tEnv.executeSql(
"CREATE CATALOG glue_catalog WITH (\n"
+ " 'type'='iceberg',\n"
+ " 'warehouse'='"
+ warehouse
+ "',\n"
+ " 'catalog-impl'='org.apache.iceberg.aws.glue.GlueCatalog',\n"
+ " 'io-impl'='org.apache.iceberg.aws.s3.S3FileIO'\n"
+ " );");
tEnv.executeSql("USE CATALOG glue_catalog;");
tEnv.executeSql("CREATE DATABASE IF NOT EXISTS " + db + ";");
tEnv.executeSql("USE " + db + ";");
tEnv.executeSql(
"CREATE TABLE `glue_catalog`.`" + db + "`.`sample` (uuid bigint, data string);");Step 2: Producing data to Kinesis Data Stream
Kinesis producer agents running the Kinesis producer library to put records into the Kinesis data stream from the WebSocket API.
Firstly, let us initialize a AWS kinesis client:
# Initialize a Kinesis client
kinesis = boto3.client('kinesis', region_name='aws-region')The Kinesis data stream accepts JSON data:
# Converting data to json object
data_str = json.dumps(data)Once the data is ready to be put into the data stream:
# Put record into the Kinesis
response = kinesis.put_record(
StreamName=stream_name,
Data=data_str.encode('utf-8'),
PartitionKey=str(datetime.now().timestamp()) # partition key
)Step 3: The Flink application reads data from the Data Stream and writes to the Iceberg table.
The AWS-managed Flink service leverages a Kinesis connector that reads data from a data stream, allowing real-time transformation before writing to the iceberg table.
Firstly, let us create a Kinesis Data Consumer to read data from the Kinesis data stream:
// Define the Kinesis source
String kinesis-stream-name = "kinesis-stream-name";
FlinkKinesisConsumer<String> kinesisDataConsumer = new FlinkKinesisConsumer<>(
kinesis-stream-name,
new KinesisDeserializationSchemaWrapper<>(new Schema())
);Now, configure the data stream as a source for the Flink application:
// set up data stream source
DataStream<String> kinesisDataStream = env.addSource(kinesisDataConsumer);Now, point the Flink application to the iceberg table on AWS S3:
// Initializating Iceberg table
String icebergTableS3Path = "s3://path/to/iceberg-table";
TableLoader tableLoader = TableLoader.fromCatalog(FlinkCatalogFactory.builder().defaultWarehouse(icebergTableS3Path).build());
TableLoaderResult tableResult = tableLoader.loadTable();
Table icebergTable = tableResult.table();Finally, let’s write data to the iceberg table:
// Writing data to Iceberg
kinesisDataStream.addSink(new StreamingSink<>(icebergTable, schema });Step 4: Query data using Trino (Athena) on AWS
We can use AWS Athena to query data using the Trino Engine from glue iceberg tables.
-- Select all columns from the Iceberg table
SELECT *
FROM database.schema.table;Learn More About:
Conclusion
This article discussed the rising data lakehouse architecture and how Apache Iceberg makes it engine agnostic, bringing in the right tool for the right job. Apache Iceberg is a go-to architecture that can power batch and stream data ingestion into the lakehouse. Learn how an Iceberg catalog improves data versioning and governance in modern data platforms. Explore key steps in moving Postgres data to Iceberg seamlessly. Migrate Oracle data to Iceberg to improve scalability and storage efficiency.
You can also ingest data from various sources to your desired destination within minutes using Hevo’s automated platform. Sign up for Hevo’s 14-day free trial to learn more!
Frequently Asked Questions(FAQs)
Does Apache Iceberg support ACID transactions?
Yes, Iceberg supports databases like Atomicity, Consistency, Isolation, and durability (ACID) features.
Does Apache Iceberg support time travel?
Each timestamp snapshot of the iceberg table is stored in the metadata layer and thus can be used to query the data as of any particular snapshot across the timestamp.
How does Apache Iceberg support multiple concurrent writes?
Iceberg leverages “optimistic concurrency” to provide transactional guarantees during simultaneous concurrent writes.
What are the file types that Apache Iceberg supports?
The data layer of the Apache Iceberg architecture supports file formats like Parquet, AVRO, and ORC to store actual data in the lakehouse.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




