

A data lake is a central storage place for an organization’s data in its original format. Unlike data warehouses, data lakes can handle all kinds of data, including unstructured and semi-structured data like images, video, audio, and documents. Using inexpensive object storage and open formats, data lakes allow companies to use advanced analytics and machine learning.
However, data lakes have not fully delivered on their promises because they lack essential features like transaction support, consistent enforcement of data quality or governance, and effective performance optimizations.
In this blog, we will look at the main features and benefits of Apache Iceberg and show how they simplify the data lake management process. But first, let’s understand the limitations of traditional data lakes.
Table of Contents
Understanding Data Lake Challenges
In the early days of big data, data lakes used Hadoop for storage and processing, but as data volume grew, it became complex. Hive emerged to translate MapReduce Jobs into SQL jobs, using a table format to identify data in storage.
As cloud storage gained popularity, the Hive table format remained the standard, but its reliance on folder structure led to inefficiencies with cloud storage. Generally, the compute engine decides how to write the data. Then, the data is usually revisited and optimized only if entire tables or partitions are rewritten, generally done ad hoc. The figure below demonstrates the foundation components of a data lake.

While data lakes offer numerous benefits, they also have limitations. Below are the challenges of traditional data lakes.
Managing massive datasets just got easier! Hevo now supports Apache Iceberg as a destination, empowering you to build a high-performance, scalable data lakehouse effortlessly.
Why Iceberg?
- Faster Queries, Less Scanning – Iceberg’s smart metadata handling means Hevo loads only what’s needed.
- Schema & Partition Evolution – Adapt without breaking pipelines! Iceberg tracks change intelligently.
- ACID Transactions & Time Travel – Query historical data or roll back changes seamlessly.
With Hevo + Iceberg, unlock flexible, efficient, and reliable data management at scale. Ready to modernize your data stack? Try it today!
Get Started with Hevo for FreePerformance
As the figure above demonstrates, a data lake is a framework of various components. Due to the decoupled nature of each component in a data lake,specific optimizations typically found in data warehouses, such as indexes, incremental updates, and ACID (Atomicity, Consistency, Isolation, Durability) guarantees, are absent.
Requires lots of configuration
As previously mentioned, creating a tighter coupling of your chosen components with the level of optimizations you’d expect from a data warehouse would require significant engineering.
Lack of ACID transactions
One notable drawback of data lakes is the absence of built-in ACID transaction guarantees, common in traditional relational databases. In data lakes, data is often ingested in a schema-on-read fashion, meaning that schema validation and consistency checks occur during data processing rather than at the time of ingestion. This poses challenges where ACID compliance is of utmost priority, such as in financial systems or applications dealing with sensitive data.
Due to diverse components (storage, file format, table format, engines), overcoming these performance challenges requires much overhead. And therefore, data lakes are less desirable in business-critical use cases.
Discover how Apache Iceberg tables optimize data lake management and take it a step further with Hevo’s seamless data integration solutions.
Get Started with Hevo for FreeNeed for Innovation
Today, digital transformation initiatives are at an all-time high. Data requirements are growing rapidly. While there are various components, the Hive framework has been instrumental in the development of data lake environments, but not without its challenges. The challenges posed by the Hive have highlighted the need for innovation in data lake management.
Modern table formats all aim to bring a core set of significant benefits over the Hive table format:
- They allow for ACID transactions, which are safe transactions completed in full or canceled. Many transactions could not have these guarantees in legacy formats like the Hive table.
- They enable safe transactions when there are multiple writers. If two or more writers write to a table, there is a mechanism to ensure the writer who completes their writing second is aware of and considers what the other writer(s) have done to keep the data consistent.
- They offer a better collection of table statistics and metadata that can allow a query engine to plan scans more efficiently so that it will need to scan fewer files.
In the following sections, we will explore how Apache Iceberg tables address these challenges and reshape data lake management for the modern era.
Introduction to New Table Format: Apache Iceberg
Apache Iceberg is a free and open-source table format to organize massive data tables. It was built by Netflix’s Ryan Blue and Daniel Weeks to overcome performance, consistency, and many of the challenges previously stated with the Hive table format.
Apache Iceberg has native support to allow different compute engines, like Spark or Presto, to work simultaneously on the same table. This capability has made it a popular choice for efficiently managing vast data.
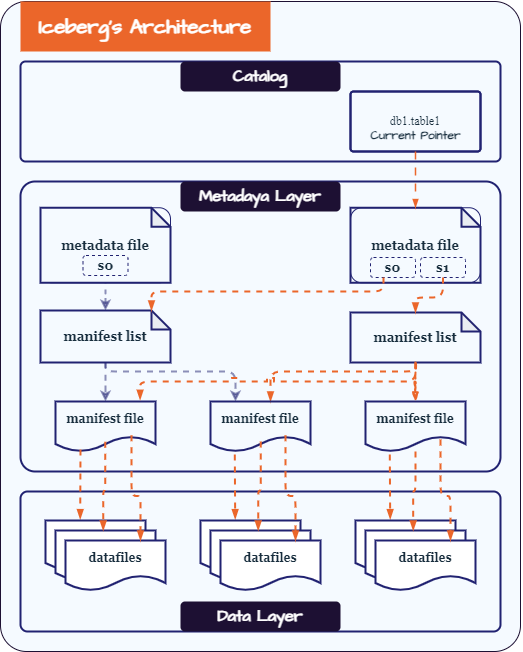
The Data Layer
The data layer stores the actual data of the table, consisting mainly of data files and deleted files. Users query the table and get the data they need from the data layer. While the metadata layer may sometimes provide results, the data layer is mainly responsible for answering user queries. The files in the data layer form the leaves of the table’s tree structure.
Data Files
Data files are nothing but the data itself. Iceberg supports multiple industry standards file formats, including Parquet, ORC, and Avro. Organizations use different formats based on their needs. However, Parquet is widely adopted specifically for data lake due to its performance benefits and industry support.
The Metadata Layer
The metadata layer is an integral part of an Iceberg table’s architecture. It contains all the metadata files for an Iceberg table. This layer enables core features such as time travel and schema evolution. It consists of the following files:
Manifest Files
Manifest files track datafiles and delete files at the file level, providing details and statistics for each file. Iceberg tables use manifest files to store statistics for multiple datafiles, improving performance. Iceberg tables have up-to-date and accurate statistics, allowing engines to make better decisions and resulting in higher job performance.
Manifest Lists
A manifest list is like a snapshot of an Iceberg table at a specific time. It includes a list of all the manifest files for the table at that moment, along with their location, the partitions they belong to, and the upper and lower bounds for partition columns for the datafiles they track.
Metadata Files
The metadata files keep track of manifest lists. When changes are made to the table, a new metadata file is automatically created and registered as the latest version. This process ensures a linear history of table commits and helps with concurrent writes. Additionally, it ensures that engines always see the newest version of the table during read operations.
The Catalog Layer
The catalog layer holds the current location of the metadata pointer for each table, ensuring consistency for readers and writers.
Key Benefits of Apache Iceberg for Data Lake Management
Apache Iceberg’s modern design approach offers many features and benefits beyond addressing Hive’s challenges. On top of that it introduces renewed capabilities for data lakes and data lakehouse workloads. Let’s dive into key benefits:
1. Flexibility
a. Schema evolution
Tables can undergo various changes, such as adding or removing a column, renaming a column, or modifying a column’s data type. With Apache Iceberg’s powerful schema evolution features, it becomes possible to carry out tasks like converting an ‘int’ column to a ‘long’ column as the values in the column grow in size.
b. Partition evolution
Apache Iceberg provides the flexibility to modify a table’s partitioning at any time without needing to rewrite the entire table and its data. Because partitioning is closely tied to metadata, the operations required to adjust your table’s structure are fast and cost-effective.
2. Performance
a. Row-level table operations
Apache Iceberg allows you to optimize the table’s row-level update patterns using one of two strategies: copy-on-write (COW) or merge-on-read (MOR).
When using COW, for a change of any row in a given data file, the entire file is rewritten (with the row-level change made in the new file) even if a single record is updated.
When using MOR, only a new file containing the changes to the affected row that is reconciled on reads is written for any row-level updates.
These strategies give the flexibility to speed up heavy updates and delete workloads.
b. Time travel
Apache Iceberg allows you to access historical snapshots of table data, enabling you to run queries on past states of the table, known as “time travel.” This becomes very handy for tasks such as generating end-of-quarter reports or reproducing the output of a machine learning model from a specific point in time without needing to duplicate the table’s data.
c. Version rollback
Iceberg’s snapshot isolation allows querying the data as it is and reverting the table’s newest version to previous snapshots, making it easy to undo mistakes by rolling back.
3. Interoperability
Apache Iceberg is a superior choice for integrating into existing data systems because it works well with popular data processing tools like Apache Spark, Trino, and Apache Flink. This means organizations can keep using their current tools while reaping the benefits of Iceberg. Standard APIs make integrating easier, offering consistent connections and smooth interactions across different systems.
Conclusion
Apache Iceberg is transforming how data lake files are managed, addressing long-standing challenges in big data ecosystems with a robust solution. Its features, including ACID transactions, schema evolution, time travel, and partition management, ensure data consistency, flexibility, and effective data organization.
Looking forward, Apache Iceberg is set to play a critical role in shaping the future of data lake platforms. As data volumes and processing requirements increase, Iceberg’s flexibility, scalability and performance will become even more crucial. We anticipate broader adoption and further innovation in cloud-native data processing and analytics.
While Apache Iceberg tables optimize data lake management, use Hevo to seamlessly integrate and manage your data. Get started with Hevo’s free trial or schedule a demo today.
Frequently Asked Questions
1. What are the advantages of Apache Iceberg?
Apache Iceberg offers several advantages, including improved data lake management with features like time travel, schema evolution, and partitioning. It provides strong consistency guarantees and supports large-scale data processing with efficient querying and storage optimizations.
2. How do you optimize data lake?
To optimize a data lake, you can implement strategies like data partitioning, indexing, and compression. Regularly cleaning and organizing data, using efficient file formats (e.g., Parquet), and leveraging metadata management tools also help improve performance and manageability.
3. When not to use Apache Iceberg?
Avoid using Apache Iceberg if your data lake doesn’t require complex features like schema evolution or time travel, or if you need a lightweight solution with minimal overhead. It may also be less suitable for simpler use cases where a traditional file format like Parquet or Avro suffices.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




