



Python is the most widely used programming language, with countless applications in a variety of disciplines. With its flexibility and dynamic nature, it is perfect for deployment, analysis, and maintenance. Python also has an inbuilt multiprocessing and threading module that allows for multi-threading and multiprocessing. To set up Batch Processing, you can use Python’s core functionality. Batch Processing is essential for corporations and organizations to effectively manage massive volumes of data. It’s particularly well-suited to managing regular, repetitive tasks.
In this article, you will walk through batch processing and explain why it is important. You will get a brief overview of Python and will understand an example of how to get started with Python Batch Processing. At the end of this article, you will discover the various benefits of Python batch processing and some of the challenges it faces. So, read along to learn more about Python Batch Processing and how you can speed up your tasks.
Table of Contents
What is Batch Processing?
Batch Processing is a technique for processing large amounts of data in a repeatable manner. When computational resources are available, the batch technique allows users to process data with little or no human intervention. Simply described, batch processing is the method through which a computer completes batches of work in a nonstop, sequential manner, typically simultaneously. It’s also a command that guarantees huge jobs are broken down into smaller chunks for debugging efficiency.
Batch ETL Processing entails users collecting and storing data in batches during the course of a “batch window”. This saves time and enhances data processing efficiency, allowing organizations and businesses to handle enormous volumes of data and analyze it rapidly.
You can refer to What is Batch Processing? A Comprehensive Guide to understand more about Batch Processing.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s automated, No-code platform empowers you with everything you need to have for a smooth data replication experience.
Check out what makes Hevo amazing:
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built integrations for 100+ sources (with 40+ free sources) that can help you scale your data infrastructure as required.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
What is Python?

Python is an open-source, high-level, object-oriented programming language designed by Guido van Rossum. It is one of the most popular computer languages. Python’s basic, clear, and easy-to-learn syntax makes it simple to grasp and aids in the creation of short-line code. Furthermore, Python contains a vast collection of libraries that can be used for a variety of purposes in the fields of Data Engineering, Data Science, Artificial Intelligence, and many others. Pandas, NumPy, and SciPy are just a few examples of prominent Python packages.
Python allows you to work more quickly and efficiently to integrate systems. It has a large and thriving worldwide community, with major tech giants, including Google, Facebook, Netflix, and IBM, relying on it. Python enables interactive code testing and debugging, as well as offers interfaces to all major commercial databases.
How to Set Up Python Batch Processing?
In this section, you will understand the steps to work with Python Batch Processing using Joblib. Joblib is a suite of Python utilities for lightweight pipelining. It contains unique optimizations for NumPy arrays and is built to be quick and resilient on large data. It is released under the Berkeley Source Distribution (BSD) license.
Some of the key features of Joblib are:
- Transparent Disk-Caching of Functions & Lazy Re-Evaluation: A memoize or make-like feature for Python functions that work with any Python object, including very big NumPy arrays. By expressing the operations as a collection of steps with well-defined inputs and outputs: Python functions, you can separate persistence and flow-execution logic from the domain logic or algorithmic code. Joblib can save their computation to disc and repeat it only if required.
- Simple Parallel Computing: Joblib makes it easy to write readable parallel code and easily debug it.
- Fast Compressed Persistence: An alternative for a pickle that works well with Python objects that contain a lot of data ( joblib.dump & joblib.load ).
Let’s see an example of how you can use the Joblib to set up the Python Batch Processing:
In this case, you’ll create a sample function that approximates Pi but with a 6th order.
This will take around 200 milliseconds to compute. You will find some variables in the code.
A row is an initial variable, which represents a single item to analyze. This might be a filename that the method must open and load or a string that must be normalized.
You can see the sample code below, which can be tweaked as per your use case.
from joblib import Parallel, delayed
from tqdm import tqdm
def batch_process_function(order, payload=None):
"""
Simulate process function.
Order and payload are ignored.
Approximate pi using Leibniz series.
"""
k, pi = 1, 0
for i in range(10**6):
if i % 2 == 0: # even
pi += 4 / k
else: # odd
pi -= 4 / k
k += 2
return pi
# Settings
N = 1_000
items = range(N)
# Serial run (if needed)
# result = [batch_process_function(6, None) for row in items]
# Parallel run using joblib with a progress bar from tqdm
result = Parallel(n_jobs=8)(
delayed(batch_process_function)(6, None)
for _ in tqdm(items)
)
- The code imports
Parallelanddelayedfromjoblibfor parallel processing. - It also imports
tqdmfor a progress bar. - The function
batch_process_function(order, payload=None)approximates π using the Leibniz series. The parametersorderandpayloadare ignored. - It runs a loop for 10^6 iterations to calculate pi.
N = 1_000sets the number of items to process.items = range(N)creates a range of items from 0 to 999.- A serial run is commented out. It processes each item in a list comprehension.
- The parallel run executes
batch_process_functionin parallel with 8 jobs. It usesdelayedto postpone function execution. - The progress bar from
tqdmtracks the loop. - The result is a list of π approximations computed in parallel.
The output for the code is shown below.
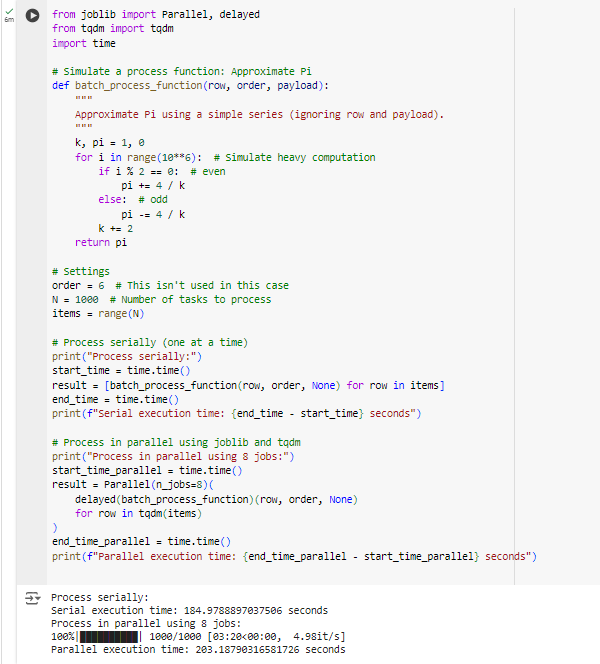
It’s worth noting that the overhead of multi-processing might be significant owing to the serialization of huge amounts of data required for each operation. To read more about the alternatives and limitations of this method, you can refer to the Parallel Batch Processing in Python | Towards Data Science.
What are the Benefits of Python Batch Processing?
Businesses use Batch Processing systems for a variety of reasons. When choosing new software for their company, business owners should consider the overall impact. Some of the advantages of Python Batch Processing are:
- Speed & Low Costs: Batch Processing can lessen a company’s dependency on other pricey pieces of technology, making it a comparatively low-cost option that saves money and time. Batch procedures are executed most efficiently and feasibly without the risk of user mistakes. As a result, managers have more time to focus on day-to-day operations and can analyze data more quickly and accurately.
- Offline Features: Batch Processing systems work in a stand-alone mode. This process is still going strong at the end of the day. To prevent overloading a system and disturbing regular tasks, Managers can restrict when a process begins. The software can be configured to execute specific batches overnight, which is a practical option for firms that don’t want jobs like automated downloads to disturb their daily operations.
- Efficiency: When computers or other resources are readily accessible, Batch Processing allows a corporation to handle jobs. Companies can plan batch operations for activities that aren’t as urgent and prioritize time-sensitive jobs. Batch systems can also run in the background to reduce processor burden.
- Simplicity: Batch Processing, in comparison to Stream Processing, is a less sophisticated system that does not require particular hardware or system support for data entry. It requires less maintenance after it is set up than a stream processing system. To learn the differences between Batch Processing and Stream Processing, refer to Batch Processing vs Stream Processing: 9 Critical Differences.
- Improved Data Quality: Batch Processing reduces the chances of mistakes by automating most or all components of a processing operation and minimizing user contact. To achieve a greater level of data quality, precision and accuracy are enhanced. For more practical approaches, you can also explore our guide to effective data cleaning tools in Python.
What are the Challenges of Batch Processing?
While Batch Processing is an excellent solution, it is not appropriate for every firm or scenario. There are several restrictions and obstacles that may prevent it from being the optimal choice for any company. Some of the challenges faced with the Python Batch Processing are listed below:
- Specific Training and Deployment: All new technology necessitates education. Batch triggers, scheduling, and how to handle exception alerts and failures are all things that employees must be aware of. Since debugging systems may be fairly sophisticated, it’s ideal to have an in-house professional who is familiar with those concepts. However, some businesses may prefer third-party advisors as to the best option.
- Cost Considerations for Smaller Firms: Implementing Batch Processing will save time and money on employees for large organizations that process substantial and continuous data. The start-up expenditures, on the other hand, may not be practical for a smaller firm that lacks data entry workers or sufficient technology to support the system.
Conclusion
In this article, you got an overview of what batch processing is and why you need it. In addition, you explored what Python is and understood the steps to set up Python Batch Processing. Further in this article, you explored the various benefits of Python Batch Processing and also learned some of the challenges faced while working with Python Batch Processing.
Businesses are today confronted with more diverse and sophisticated data sets than they have ever been before. As a result, organizations can no longer manage their data only through Batch Processing. To stay competitive, most businesses now employ a range of processing methods, combining batch with event-driven systems such as kafka python for streaming use cases. This is where a simple solution like Hevo might come in handy!
Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources, including 60+ Free Sources, into your Data Warehouse. Hevo is fully automated and, hence, does not require you to code.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Share your experience with Python Batch Processing in the comments section below!
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





