

As analytics in your company graduates from a MySQL/PostgreSQL/SQL Server, a pertinent question that you need to answer is which data warehouse is best suited for you. This blog tries to compare Redshift vs BigQuery – two very famous cloud data warehouses today.
In this post, we are going to talk about the two most popular data warehouses: Amazon Redshift and Google BigQuery. Honestly, in the Redshift vs BigQuery comparison, similarities are greater than the differences.
Table of Contents
What are Data Warehouses?
Data Warehouses can be defined as a large collection of business data. This data can then be leveraged by an organization to make business decisions. Organizations that leverage Data Warehouses for their Business Intelligence and Analytics see various substantial benefits. Here are a few benefits of leveraging Data Warehouses:
- Faster Decisions: The data in a Data Warehouse is present in such consistent formats that it is ready to be analyzed. Apart from this, it also provides a more complete dataset and the analytical power to base decisions on hard facts.
- Better Data: Adding various data sources to a Data Warehouse enables organizations to ensure that they are collecting relevant and consistent data from that source. They don’t need to wonder whether the data will be inconsistent or accessible as it comes into the system.
What are Data Processing Systems?
Data Processing Systems can broadly be classified into two classes: OLTP (Online Transactional Processing) and OLAP (Online Analytical Processing). Here are a few salient differences between the two:
- OLTP: This is used by most businesses for processing transactions during day-to-day operations. It stores each row in a table as an object. OLTP’s primary goal is Data Processing.
- OLAP: This is used by Data Warehouses to run queries. It stores each column as an object. It is great at crawling through massive data sets to find useful trends to steer business growth.
For more differences, you can refer to our immensely informative blog on OLTP vs OLAP Systems which will give you a holistic understanding of both data processing systems.
What is Redshift?

Amazon Redshift is a fully managed cloud-based data warehouse which is designed for handling large-scale data set storage. It is also used to perform large-scale database migration. The architecture of Redshift involves nodes and clusters. The initial process involves launching a set of computing resources called nodes. These nodes are organized into large groups called clusters. Queries can be processed after it.
Key Features of Amazon Redshift
- Redshift ML: This feature makes it easier for Database Developers and Data Analysts to train, create, and deploy Amazon SageMaker models using SQL. It also allows its customers to use SQL statements to create and train Amazon SageMaker models on their data in Amazon Redshift.
- Materialized Views: Materialized Views let you achieve significantly faster query performance for predictable or iterative analytical workloads like dashboarding, along with queries from Business Intelligence tools and ETL Data Processing jobs.
- Result Caching: Result Caching is used to deliver sub-second response times for repeat queries. Visualization, Business Intelligence, and Dashboard tools that execute repeat queries experience a significant performance boost.
Know more about Amazon Redshift from their official documentation.
What is BigQuery?

Google BigQuery is a fully managed and serverless data warehouse. It allows the analysis of petabytes of data. BigQuery also supports querying using ANSI SQL. It has machine learning capabilities. It runs on Google Cloud Storage and can be accessed using REST API.
You can gain insights with real-time and predictive analysis using Google BigQuery. Know more about Google BigQuery from their official document.
Key Features of Google BigQuery
- BigQuery Omni: BigQuery Omni is a fully managed, flexible, multi-cloud analytics solution that lets you analyze data across clouds such as Azure and AWS.
- BigQuery ML: This feature allows Data Analysts and Data Scientists to operationalize ML models on planet-scale Semi-Structured and Structured data. This can be done inside BigQuery itself while using SQL in no-time flat.
- BigQuery BI Engine: This feature is an inbuilt in-memory analysis service that enables users to analyze large and complex datasets interactively with sub-second query response time and high concurrency.
- BigQuery GIS: This feature combines the serverless architecture of BigQuery with native support for geospatial analysis. This allows you to augment your analytics workflows with location intelligence.
What are the Differences between Redshift and BigQuery?
Now that you have a brief idea about the features and benefits of Redshift and BigQuery, you can look into the Redshift vs BigQuery discussion to understand which one suits your use case better. Here are the 4 factors you can keep in mind:
Redshift vs BigQuery: Features
The devil is in the details when it comes to comparing Redshift and BigQuery – the features, capabilities, and underlying architecture. When comparing Redshift and BigQuery, keep the following features in mind.
| Redshift | BigQuery | |
| Platform | Amazon Web Services | Google Cloud Platform |
| Infrastructure | Provisioned clusters and nodes | Serverless |
| Availability (regions per area) | Americas – 8 Europe – 5 Asia Pacific – 9 | Americas – 4 Europe – 3 Asia Pacific – 7 |
| Updating tables | Staging table | Data Manipulation Language |
| Table column limits | 1,600 columns | 10,000 columns |
| Streaming data ingestion | Must use Amazon Kinesis Firehose | Supported |
| Manageability / usability | User configures infrastructure, periodic management tasks required | No configuration necessary |
| Security | Inherits security features of Amazon Web Services Encryption of data must be enabled AWS data loss prevention (DLP) service, Macie, does not support Redshift | Inherits security features of Google Cloud Platform Encrypts data by default Google Cloud DLP service supports BigQuery |
Performance
On many head-to-head tests, Redshift has proved to show better query times when configured and tweaked correctly. There are several benchmarks available over the internet. You can also refer to the official AWS blog from here. Refer our documentation on performance of Redshift and BigQuery.
It is slightly difficult to gauge the performance between the two since over 500 companies have published their own benchmarks to pick the product that suits them the best. Here are a few benchmarks to give you an idea about the Redshift vs BigQuery comparison:
- Independent Research: Independent Research was conducted by an enthusiast on cab data which showed BigQuery as 43x faster than Redshift. This result was flawed due to its selection of query type and node type.
- Amazon Benchmark: Amazon ran a TPC-H benchmark that depicted Amazon Redshift outshining Google BigQuery on almost all tests. However, Amazon decided to use an 8-node DC1.8XL for this test which runs at a whopping $20k/month.
- Google Benchmark: Google presented a TPC-H benchmark at CloudAir in San Francisco in 2016 that depicted Google BigQuery outshining Amazon Redshift. However, Google cleverly decided to go with just a single performance metric to prove their superiority instead of all 26 metrics.
To summarise the Redshift vs BigQuery discussion, Amazon Redshift is a great choice for handling everyday business processes while BigQuery is great for handling niche business workloads that query big chunks in a small timeframe and for Data Mining/ML and Data Scientists.
Availability
Regions and zones are used in both Redshift and BigQuery architectures. High availability is achieved by physically separating zones within each region (HA). To ensure high availability, Redshift necessitates more manual configuration than BigQuery, but both offer effective resiliency.
Redshift has 14 countries covered by regions, while BigQuery has 12 countries covered by regions. Within each region, each service has one or more zones.
A zone should be viewed as a single point of failure in the context of high availability, so two nodes within the same zone do not provide HA. A node in each of two (or more) zones within a region is the best practice for high availability.
Manageability and Usability
Redshift gives you a lot more flexibility on how you want to manage your resources. This means that you get more control at the cost of some management overhead.
To operate a decently sized Redshift cluster efficiently, you need a deep understanding and skill-set around warehousing concepts. For example, Redshift will expect you to know about how to distribute your data across nodes and will require you to do vacuuming operations periodically.
BigQuery, on the other hand, does not expect you to manage your resources. It abstracts away the details of the underlying hardware, database, and all configurations. It mostly works out of the box.
There are 4 key layers of Manageability that need to be taken into account to clarify the difference between Redshift and BigQuery. The 4 layers are as follows:
- Ease of Use: BigQuery trumps Redshift in terms of ease of use. This is because cluster management in BigQuery is fairly simple and you don’t have to perform as many tweaks as compared to Redshift. On top of this, BigQuery also handles all the complexities of database configuration which gives it the upper hand here. So BigQuery stands taller than Redshift here for the Redshift vs BigQuery discussion.
- Integrations: Both Amazon and Google offer a plethora of integrations to their users. Almost every Data Analysis and BI tool work perfectly well with these two Data Warehouses. So it is an equal match here for the Redshift vs BigQuery discussion.
- Data Updates/Types and Deletes: BigQuery supports some standard SQL data types along with a small range of sub-standard SQL. Redshift, on the other hand, supports all standard SQL types. BigQuery treats nested data classes as first-class citizens owing to its Dremel capabilities. This gives it an advantage over Redshift, where you have to flatten out your data before running a query. Both BigQuery and Redshift can handle updates and deletes, but it’s relatively expensive for BigQuery. Update and Delete support is better for Redshift since you can reclaim your tables with Postgres Vacuuming. Redshift also offers its users the ability to roll back on transactions which gives it an advantage over BigQuery since BigQuery doesn’t have this feature.
Pricing
In the case of Redshift, you need to predetermine the size of your cluster. That means you are billed irrespective of whether you query your data on not. Shutting down clusters when not needed is left to the user. Billing is done on hourly usage of the cluster.
This makes Redshift more costly when your query volumes are low. But, if your query volumes are higher, predictable, and uniformly distributed over time Redshift may turn out to be a lot cheaper. Also, the costs are more predictable because you always know the size of your cluster.
You need to decide on a cluster type before deciding on a pricing plan. This requires a basic knowledge of the different types of nodes offered by Amazon Redshift to accommodate your workloads. These are the types of nodes provided by Redshift:
- DC2 Nodes: These types of nodes allow you to have compute-intensive Data Warehouses that also provide local SSD storage. You can choose the number of nodes based on the performance and data size requirements. These nodes store your data locally for optimum performance. As your data size grows, you can add more compute nodes to increase the storage capacity of the cluster. DC2 Nodes are suggested for datasets under 1 TB uncompressed since it offers the best performance for the lowest price for this category.
- RA3 Nodes With Managed Storage: These nodes allow you to optimize your Data Warehouse by scaling and paying for managed and compute storage independently. RA3 allows you to choose the number of nodes based on your performance requirements. It also allows you to only pay for the managed storage that you use. Therefore, you should size your RA3 cluster based on the amount of data you process daily. Redshift managed storage uses high-performance SSDs in each RA3 node for fast local storage and Amazon S3 for long-term durable storage. If the data in a node outgrows the large local SSDs, Redshift managed storage automatically offloads that data to Amazon S3. However, you won’t be incurring an extra cost in this situation.
- DS2 Nodes: DS2 Nodes allow you to create large Data Warehouses using Hard Disk Drives (HDD). But with new improvements, it is suggested to pick RA3 Nodes instead for more storage and better performance for the same on-demand cost.

For On-Demand Pricing the effective price per TB per year is the hourly price for that instance, multiplied by the number of hours in a year, divided by the number of TB per instance. For RA3 Nodes, the effective price per TB is calculated for only the compute node costs. Know more about Redshift pricing here.
BigQuery, on the other hand, has segregated compute resources from storage. Thus, you are only charged when you are running queries.
Billing is done on the amount of data processed during queries. On the surface this pricing might seem to be cheaper but, this approach makes costs for BigQuery unpredictable and it will turn out to be more expensive than Redshift when query volumes are high.
Google BigQuery offers two pricing models as follows:
- Storage Pricing: This refers to the cost of storing data that you load in Google BigQuery.
- Analysis Pricing: This is the cost to process queries including user-defined functions, SQL queries, scripts, and certain Data Definition Language (DDL) and Data Manipulation Language (DML) statements that scan tables.
Google BigQuery also charges for other operations like using the BigQuery Storage API and streaming inserts. The Analysis Pricing Model can further be subdivided into two models as follows:
- On-Demand Pricing: In this pricing model, you are charged for the number of bytes processed by each query. This model offers the first 1 TB of query data processed per month for free. This model is applied by default.
- Flat-Rate Pricing: In this pricing model, you need to purchase slots that are virtual CPUs. Buying slots refer to buying a dedicated processing capacity that can be used to run queries. You can get slots in three commitment plans: Flex (60-second commitment), Monthly, and Annual. You are charged a lower amount for the Monthly and Annual plans in exchange for a longer-term capacity commitment.
On-Demand query pricing is as follows:
Flat-Rate pricing commitment plans are as follows:
- Monthly Flat-Rate Commitments
- Annual Flat-Rate Commitments
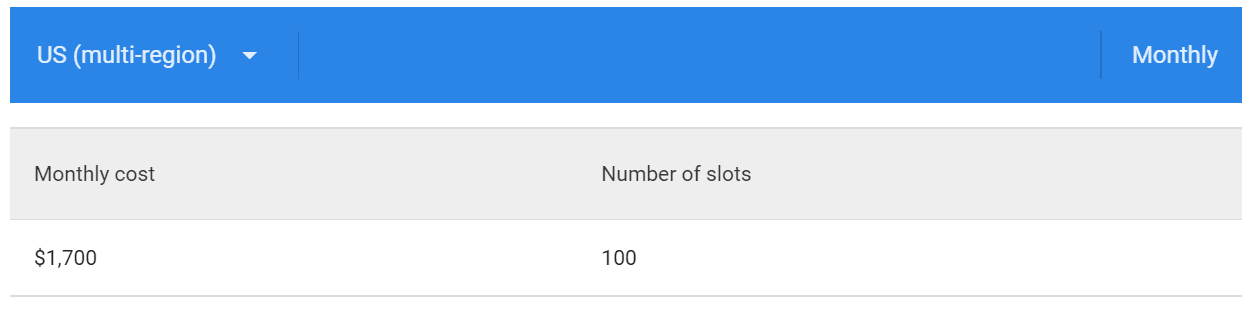
- Flex Slots

Know more about BigQuery pricing here.
Security
In the case of Redshift, it banks on AWS IAM (Identity and Access Management), an Amazon management access, and identifies its users. The system extends exceptional versatility for the company to monitor and manage the complex situation in the case of IAM.
BigQuery has the support from its Cloud IAM. Users can use OAuth as a conventional procedure to obtain the cluster, especially when a third-party authorization exists.
Business Intelligence Tools
You can use either of these data warehouses with dozens of analytics and business intelligence tools, but each cloud platform has its own analytics tool.
Amazon QuickSight integrates with Redshift and provides business intelligence (BI) insights via interactive dashboards.
BigQuery has its own business intelligence engine, which response to queries in milliseconds. Users can create interactive dashboards with the help of Google Data Studio.
Conclusion
Ecosystems around both Amazon Redshift and Google BigQuery are buzzing. They are being actively promoted by their respective companies and both the products work as marketed. You wouldn’t be too wrong about choosing either of them. Still, we recommend one over the other in the following scenarios:
- Redshift: When you are okay spending some time optimizing your data for fast queries- when your resource utilization is going to be fairly distributed across time and a large proportion of data being actually queried rather than just sitting in the database. Check out Hevo’s integration with Redshift here.
- BigQuery: When you want something that just works and don’t want to spend time tuning the database when you are okay having query response times of a few minutes and you have a lot of data that is being queried rarely. Check out Hevo’s integration with BigQuery here.
We hope that this Redshift vs BigQuery comparison was useful for you. As both platforms provide top-notch features, so it depends on you which data warehouse suits you the most. After you have decided on the data warehouse, you can initiate your data migration using Hevo Data.
Give Hevo a try by signing up for a 14-day free trial today.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





