




A lightweight, all-in-one batch framework that makes it easier to create dependable batch applications that are vital to the day-to-day operations of enterprise systems. Spring Batch comes with reusable features like Logging/Tracing, Transaction Management, Task Processing Statistics, Job Restart, and Resource Management, all of which are necessary when processing huge volumes of data.
This article will tell you about Spring Batch Parallel Processing. It will also provide some pointers that can help you choose the best possible approach.
Table of Contents
What is Spring Batch?
A lightweight, all-in-one batch framework that facilitates the development of dependable batch applications that are critical to enterprise systems’ day-to-day operations. Spring Batch includes reusable features including Logging/Tracing, Transaction Management, Task Processing Statistics, Job Restart, and Resource Management, which are required when processing large amounts of data. It also encompasses more advanced technical features and solutions that will enable exceptionally high-performance batch jobs through optimization and partitioning approaches.
In the diagram below, the Batch Reference Architecture is illustrated in a simplified form. A Job, which is made up of numerous Steps, usually encapsulates a Batch Operation. A single ItemReader, ItemProcessor, and ItemWriter are normally used in each Step. A JobLauncher runs a job, and metadata about the jobs that have been configured and run is recorded in a JobRepository. It defines the key concepts and words utilized by Spring Batch Parallel Processing.
Are you looking for an ETL tool to migrate your data? Migrating your data can become seamless with Hevo’s no-code intuitive platform. With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from various sources and destinations with 150+ pre-built connectors.
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Loading: Quickly load your transformed data into your desired destinations, such as BigQuery.
- Transparent Pricing: Hevo offers transparent pricing with no hidden fees, allowing you to budget effectively while scaling your data integration needs.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeWhat is Scaling?
Spring Batch’s Scalability specifies how to run operations in parallel, locally, or on other machines. The majority of Scaling occurs at the step level, so you can use several ways to determine wherever you want to Split Processing. You can opt to parallelize the entire process or only sections of it. You can also create datasets and process them locally or remotely in parallel. The optimal approach allows your application to fulfill your performance goals. You can take one of the numerous techniques to grow your applications:
- Vertical Scaling (scale up): Vertical Scaling (also known as Scaling up) is the process of moving an application to more capable hardware. To get the necessary performance, the application must be hosted on a larger, better, and faster system.
- Horizontal Scaling (scale out): To accommodate the load, a system can be expanded with more processing nodes (or machines). The goal of this method is to distribute computation among multiple nodes remotely. It involves load balancing since it spreads application processing over multiple nodes.
The Spring Batch Scaling Model
The optimal strategy (or set of strategies) is one that permits your app to reach your performance goals. The following are the two kinds of Scaling:
Local Scaling
Batch Task Stages are executed in parallel by Local Scaling in a single process.
Remote Scaling
Remote Scaling in multiple processes allows batch job steps to be executed in parallel.
Four Approaches to Scaling the Spring Batch
Scaling Spring Batch can be done in four ways. You’ll go over each strategy in detail.
1) Multi-Threaded Steps
Spring Batch Parallel Processing is each chunk in its own thread by adding a task executor to the step. If there are a million records to process and each chunk is 1000 records, and the task executor exposes four threads, you can handle 4000 records in parallel instead of 1000 records. It’s simple to set up by adding ThreadPoolTaskExecutor, however, it lacks restart ability and thread safety.
2) AsyncItem Processor / AsyncItem Writer
Future is returned by AsyncItem Processor. Another thread executes the logic of AsyncItem Processor. When the future is returned, Async ItemWriter opens it and pushes the data. This enables the processor logic to be scalable within a single JVM.
3) Partitioning
You simply partition the data. Partitions are then processed simultaneously. If you have a million records and divide them up into 100K chunks. You can use threads to run the partitions in parallel, which is similar to Multi-threading, or you can run it remotely using remote partitioning. This enables to set up of a master-worker configuration, with the master assigning the worker to execute on specific partitions.
Local Partitioning
The advantage of Local Partitioning over Multi-threaded Partitioning is that each partition is a separate step. As a result, you get the restart ability and thread-safety that regular steps provide but that multi-threaded steps do not.
Remote Partitioning
Remote Partitioning enables you to distribute the workload across multiple JVMs. Spring Batch Parallel Processing includes a message-based PartitionHandler which could be used to distribute processing across JVMs out of the box.
4) Remote Chunking
The worker is in charge of processing and writing, while the master is in charge of reading. The master must first read and then transmit actual records to the worker over the wire. Since this is a high-I/O operation, the processing must be the bottleneck for this strategy to be effective. In partitioning, on the other hand, the master just instructs the worker which partition to handle, such as record 1 to 100K.
Spring Batch Parallel Processing
Multiple jobs can be run simultaneously. There are two main types of Spring Batch Parallel Processing: Single Process, Multi-threaded, or Multi-process. These are also divided into subcategories, as follows:
- Multi-threaded Step (Step with many threads, single process)
- Parallel Steps ( Steps in the Same Direction, single process)
- Remote Chunking of Step (Step Chunking from afar, multi-process)
- Partitioning a Step (Creating a Step Partition, single or multi-process)
Following that, you’ll go over the single-process options first, followed by the multi-process options.
1) Multi-Threaded Step
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>Adding a TaskExecutor to your Step setup is the simplest method to start Spring Batch Parallel Processing. A SimpleAsyncTaskExecutor is the most basic multi-threaded TaskExecutor.
As a result of the above configuration, the Step will run in a distinct thread of execution, reading, processing, and writing each chunk of items (per commit interval). Note that, unlike the single-threaded situation, there is no definite order for the things to be processed, and a chunk may contain non-consecutive items.
<step id="loading"> <tasklet task-executor="taskExecutor" throttle-limit="20">...</tasklet>
</step>2) Parallel Steps
It is possible to parallelize application logic in a single process if it can be divided into discrete responsibilities and given to various phases. The “task-executor” parameter can be used to define which TaskExecutor implementation should be used to run the various flows. SyncTaskExecutor is the default, but to run the steps in parallel, you’ll need an asynchronous TaskExecutor. Parallel Step execution is simple to set up and use. For example, if you wanted to run steps 1 and 2 in parallel with step 3, you could create the following flow:
<job id="job1">
<split id="split1" next="step4" task-executor="taskExecutor">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>3) Remote Chunking
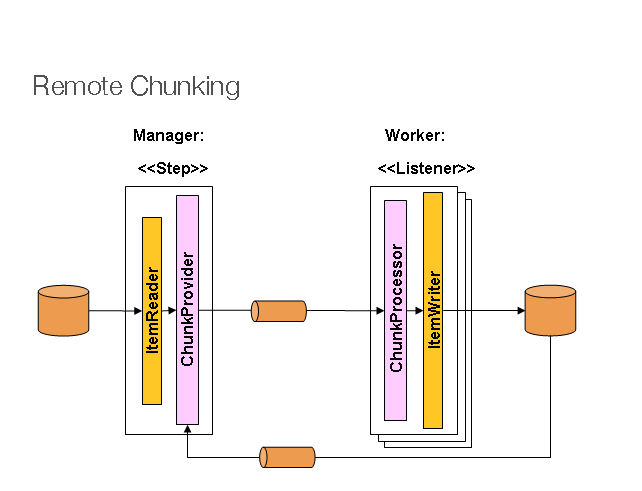
In Remote Chunking, step processing is distributed across multiple processes that communicate with one another through middleware. The Master is a single process, whereas the Slaves are a group of distant processes. The Master is just a Spring Batch Parallel Processing Step with the ItemWriter replaced with a generic form that knows how to send chunks of items as messages to the middleware.
Slaves are standard listeners for whatsoever middleware is being utilized, and their job is to manage chunks of items employing the ChunkProcessor interface with a standard ItemWriter or ItemProcessor + ItemWriter. The reader, processor, and writer components are all commercially available, which is one of the architecture’s advantages. The items are dynamically separated, and work is shared via middleware, resulting in load balancing.
4) Partitioning
Spring Batch also has an SPI for partitioning and remotely executing a Step execution. The distant participants in this scenario are basically Step instances that could have been created and utilized for local processing just as easily. Here’s a visual representation of the pattern in action.
The Job is running as a series of steps on the left, with one of the Steps designated as a Master. The Slaves in this image are all identical instances of a Step, which might potentially replace the Master and result in the same Job conclusion. Slaves are often distant services, but they could potentially be local execution threads. The Master’s messages to the Slaves in this pattern do not need to be long-lasting or guaranteed to arrive:
The JobRepository meta-data in Spring Batch Parallel Processing ensures that each Slave is only run once for each Job execution. In Spring Batch Parallel Processing, the SPI consists of a custom Step implementation (the PartitionStep) and two strategy interfaces that must be developed for the unique context. PartitionHandler and StepExecutionSplitter are the strategy interfaces, and their roles are depicted in the sequence diagram below:
The “remote” Slave in this situation is the Step on the right, thus numerous objects and or processes could be involved, and the PartitionStep is shown driving the execution. This is how the PartitionStep configuration looks:
<step id="step1.master">
<partition partitioner="partitioner" step="step1">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>Conclusion
Spring Batch Parallel Processing is classified into two types: single process and multi-threaded or multi-process. These are further subdivided into the following categories: Multi-threaded Steps, Parallel Steps, Remote Chunking of Steps, and Partitioning Steps. Spring Batch can be scaled in four ways: Multi-threaded steps, asyncItem Processor / asyncItem Writer, Partitioning, and Remote Chunking. Multiple jobs can be run concurrently, making the task easier. In case you want to export data from a source of your choice into your desired Database/destination then Hevo Data is the right choice for you!
Hevo Data, a No-code Data Pipeline provides you with a consistent and reliable solution to manage data transfer between a variety of sources and a wide variety of Desired Destinations, with a few clicks. Hevo Data with its strong integration with 150+ sources (including 60+ free sources) allows you to not only export data from your desired data sources & load it to the destination of your choice, but also transform & enrich your data to make it analysis-ready so that you can focus on your key business needs and perform insightful analysis.
SIGN UP for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Share your experience of learning about Spring Batch Parallel Processing! Let us know in the comments section below!
Frequently Asked Questions
1. What is parallel batch processing?
Parallel batch processing refers to executing multiple batches of tasks or jobs simultaneously to improve efficiency and reduce the overall processing time.
2. Is Spring Batch still relevant?
Spring Batch remains relevant and widely used for batch processing in Java applications.
3. Is parallel processing faster?
Parallel processing is generally faster than sequential processing for tasks that can be effectively divided and executed concurrently, but effectiveness depends on task characteristics and resource availability.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link








