

There are various Data Warehouses available in the market today, knowing their attributes and strengths will go a long way in helping you to decide which one best fits the purpose of your business, your financial capability, and the magnitude of your operation. When it comes to the field of Data Warehouses, the choice of Teradata vs Snowflake is a relatively tough one.
Teradata is a software company that provides various types of databases and analytics-related products and services. it was formed in 1979 in Brentwood, California as a collaboration between researchers at Caltech and Citibank’s advanced technology group. Snowflake is a Cloud-based Data Warehousing company based in San Mateo, California. It was founded in July 2012 and launched in October 2014. Both these technologies are leveraged by organizations of all scales, both big & small, and depending on the situation, one can dominate over the other.
This article provides you with a comprehensive analysis of both Data Warehouses and highlights the major differences between them to help you make the Teradata vs Snowflake decision easy. It also provides you with a brief overview of both data warehouses and their features. Read along with how you can choose the right Data Warehouse for your organization.
Table of Contents
What is Teradata?

Teradata is a popular Relational Database Management System (RDBMS) produced by Teradata Corp. It is suitable for large data warehousing operations, it has the capabilities of handling large volumes of data and it is highly scalable.
Key Features of Teradata
Teradata has the following features:
- Unlimited Parallelism: Teradata’s database system is based on a Massively Parallel Processing (MPP) architecture. The MPP architecture divides the system’s workload evenly by splitting tasks among its processes and running them in parallel, ensuring that each task is completed swiftly.
- Connectivity: Teradata connects to channel-attached systems like mainframes and network-attached-based systems. It also supports the use of standard SQL to connect to data stored in tables and has several extension capabilities.
- Shared Nothing Architecture: Teradata uses a Shared Nothing Architecture, in which each node works independently with its Access Module Processors (AMPs) and does not share its disks.
- Scalability: The Teradata system is highly scalable and can be scaled up to about 2048 Nodes by simply doubling the capacity of the system by increasing the number of AMPs.
What is Snowflake?

Snowflake is a Cloud-based Data Warehousing and Analytics system that gives users access to store and analyze data using cloud-based hardware and software. It is a Software-as-a-Service company powered by an advanced data platform. It is built on Amazon Web Services and Microsoft Azure Cloud infrastructure and owned by Snowflake Inc.
Key Features of Snowflake
Snowflake has the following features:
- Cloud Service Provider: Snowflake runs completely on cloud infrastructure as all the components of Snowflake’s service run in public cloud infrastructures offered by Amazon Web Service, Microsoft Azure, and Google Cloud.
- Scalability: Snowflake gives you the ability to scale up resources when there is a large amount of data to be loaded to increase speed and to scale down when the process of loading is finished without creating an interruption to the service.
- Separation of Computing and Storage Resources: Snowflake’s multi-layer shared data architecture separates the compute and storage resources to avoid concurrency. Workloads to be executed are matched against its compute clusters called a virtual warehouse to ensure that queries from one virtual data warehouse will not affect queries from another.
- Near-Zero Administration: Snowflake’s Software-as-a-Service offers data warehousing and enables companies to set up and manage their solution without significant involvement from IT teams, as it does not require additional software or hardware to be installed in its operations.
- Security: Snowflakes has a range of security features, from the way you access snowflake to how data is stored, as you can manage network policies by restricting some IP addresses, use various authentication methods like two-factor authentication and encryption across all network communications.
A Snowflake-native app to monitor Fivetran costs.

Teradata VS Snowflake
| Factor | Teradata | Snowflake |
| Deployment | On-premises, hybrid, or cloud (Teradata Vantage) options available. | On-premises, hybrid, or cloud (Teradata Vantage) options are available. |
| Scalability | On-premises, hybrid, or cloud (Teradata Vantage) options are available. | Instantly scalable with automatic separation of computing and storage, scaling resources dynamically without manual effort. |
| Performance | High performance but requires manual optimization (indexes, tuning) for large workloads. | Optimized automatically with dynamic compute scaling and clustering, handling large workloads with minimal intervention. |
| Ease of Use | More complex to manage, requiring manual setup for infrastructure and workload optimization. | Simple, user-friendly with minimal configuration, as it handles infrastructure, tuning, and scaling automatically in the cloud. |
| Cost Structure | Fixed costs based on infrastructure; can be expensive due to dedicated resources. | Pay-as-you-go model for both computing and storage, offering flexible, cost-efficient pricing based on actual usage. |
Learn How to Integrate Snowflake and Terraform.
Factors that Drive the Teradata vs Snowflake Decision
Teradata and Snowflake both function using Massively Parallel Processing (MPP) in querying data. They have lots of similarities, but they also have some differences. Below is a list of key differences between Teradata and Snowflake:
1) Architecture
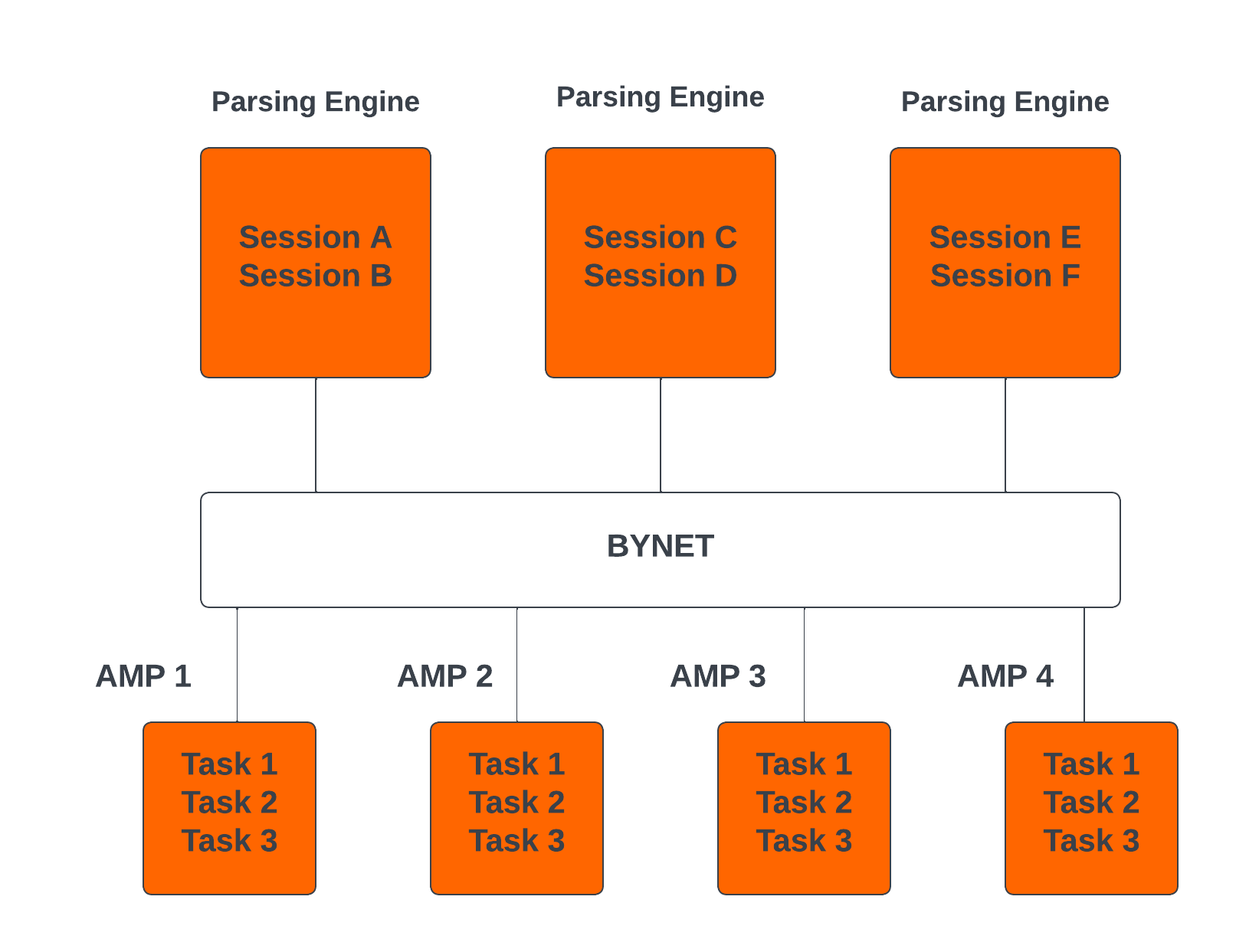
Teradata acts as a single data store that accepts a large number of concurrent requests from multiple client applications and executes them in parallel, along with load distribution among several users. Teradata’s architecture is made up of the following components:
- Node – this is a unit in Teradata as each server is referred to as a node that consists of its operating system, CPU, memory, a copy of Teradata’s RDBMS software, and disk space.
- Parsing Engine – the parsing engine is responsible for receiving queries from clients and preparing an execution plan.
- Message Parsing Layer – this is the networking layer in Teradata that allows communications between the parsing engine (PE) and Access Module Processor (AMP) and also between the nodes. It is referred to as BYNET.
- Access Module Processor (AMP) – It is called a virtual processor whose purpose is to store and retrieve data. When a client wants to store data, the parsing engine sends the records to BYNET, which in turn sends the row to the target AMP, then the AMP stores this record on its disk. For retrieval, when a client runs a query to get records, the parsing engine sends a request to BYNET, which sends a retrieval message to the AMPs. The AMP searches the disk in parallel to identify the record for forwarding to BYNET, and from BYNET, the record is sent to the parsing engine and then to the user.
The architecture of Teradata is shown below.
- Snowflake
Snowflake’s architecture is a combination of the traditional shared-disk and shared-nothing database architectures. It consists of nodes that access a central data repository like in a shared-disk architecture but also has nodes in a cluster where each node stores a portion of the entire data set locally using MPP to process queries.
This combined approach allows for a shared-disk architecture but with the performance and benefits of a shared-nothing architecture. This unique arrangement of Snowflake consist of the following parts, and their functions are explained below:
- Database Storage – When data is loaded into Snowflake, it rearranges the data into its internal columnar format before storing this optimized version in its cloud storage. It manages how data is stored in it and the data objects stored by Snowflake are not visible nor accessible by customers but can be accessed through SQL queries sent using Snowflake.
- Query Processing Layer – This is where query execution takes place and it’s done using virtual warehouses. This virtual warehouse is an independent compute cluster that functions using MPP, it is made up of multiple compute nodes allocated by Snowflake from a cloud provider, therefore, each virtual warehouse does not share compute resources with other virtual warehouses and has no impact on the performance of others.
- Cloud Services – This layer is a collection of services that coordinates the activities across the platform as it processes user’s requests. Its functions range from authentication, query parsing, and optimization, access control, metadata management, infrastructure management, etc.
The architecture of Snowflake is shown below.

2) Mode of Operation
Teradata uses hardware and software components that need to be installed on-premises for optimal usage of their services. Despite having a cloud service, it is not as popular as the usage of its propriety hardware and software service, whereas Snowflake runs a cloud solution as everything resides in the cloud.
The data, software, and the SQL client used to access the Snowflake warehouse are stored and run on cloud infrastructure. So basically, there are no hardware/software installations, configurations or maintenance, management of data, upgrades, etc., and SQL tuning is handled by Snowflake as it uses AWS, Azure, GCP hardware, and its propriety layer to manage resources and users.
3) Size and Capacity
Teradata operates with a fixed size and capacity, and if the need arises for more capacity, you will need to purchase additional hardware and upgrade the system, thereby restructuring it.
Snowflake comes with unlimited storage and computes size as it offers a cloud service that can be scaled automatically at any time.
Read about the data storage types in Snowflake storage costs.
4) Indexes
Teradata uses primary, secondary, and joint indexes. On Snowflakes, there is no such thing as a secondary or joint index.
5) Collection of Statistics
The collection of statistics on Teradata is done by the user. You have to instruct Teradata to carry out the operation but Snowflake collects required statistics on its own without a user having to do anything.
6) Access to Data
Teradata uses hashing to gain access to data stored within its system while Snowflake stores data in a micro-partition and within each micro partition, the data columnar are stored as they are compressed. Each micro partition has metadata, and access is gained by looking up the metadata.
7) Workload Management
Teradata offers sophisticated workload management and partition systems. Any virtual partition can access the CPU if they are not needed by other partitions.
Snowflake uses the concept of a virtual warehouse to separate the workload and manage it for you.

8) Data Distribution
Teradata is a shared-nothing architecture, and each Teradata node works independently as it does not share its disks.
Snowflake is not a shared-nothing architecture. Rather, the computing resources have access to shared data.
9) APIs and Other Access Methods
Teradata has the following APIs and access methods: .NET Client API, HTTP REST, JDBC, JMS Adapter, ODBC, and OLE DB.
Snowflake has the following APIs and access methods: CLI Client, JDBC, and ODBC.
10) Supported Programming Languages
Teradata supports the following programming languages: C, C++, Cobol, Java (JDBC-ODBC), Perl, PL/1, Python, R, and Ruby.
Snowflake supports the following programming languages: JavaScript, Node.js, and Python.
Hevo Data, a No-code Data Pipeline, helps load data from 150+ data sources such as Databases, SaaS applications, Cloud Storage, SDK, and Streaming Services and simplifies the ETL process. Check out why Hevo is the Best:
- Transform your data with custom Python scripts or using the drag-and-drop feature.
- Forget about manually mapping the schema into the destination with automapping.
- Connect with Live Support, available 24/5, and chat with data engineers.
With a 4.3 rating on G2, see how industry leaders like BeepKart transformed their data management with Hevo.
Sign up here for a 14-Day Free Trial!Conclusion
This article gave a comprehensive analysis of the 2 popular Data Warehousing technologies in the market today: Teradata and Snowflake. It talked about both the Data Warehouses and their features. It also gave the parameters to judge each of the Data Warehouses. Overall, the Teradata vs Snowflake choice solely depends on the goal of the company and the resources it has.
In case you want to integrate data from data sources into your desired Database/destination like Snowflake and seamlessly visualize it in a BI tool of your choice, then Hevo Data is the right choice for you! It will help simplify the ETL and management process of both the data sources and destinations.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Share your experience of learning about Teradata vs Snowflake in the comments section below.
FAQs
1. Why move from Teradata to Snowflake?
The advantages of migrating to Snowflake are easier scalability, lower costs with its pay-as-you-go model, and a simplified cloud-native architecture that automatically handles infrastructure and performance, unlike Teradata’s more complex management.
2. Can Snowflake connect to Teradata?
Absolutely, yes. Snowflake can be integrated with Teradata using data integration tools like Fivetran, Informatica, or custom scripts, enabling smooth and efficient migration and synchronization of data between the two platforms.
3. What tools integrate with Snowflake?
It integrates with all kinds of tools, such as Tableau, Looker, and Power BI for analytics; Fivetran and Talend for data ingestion; and many others including Python, Spark, and AWS services for extended functionality.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





