




 Quick Takeaway
Quick TakeawayHadoop is an open-source framework that enables scalable data storage and processing across distributed clusters. Its core components like HDFS, MapReduce, and YARN ensure fault tolerance and efficient resource management.
Key Hadoop Tools:
- HDFS: A distributed file system for scalable storage.
- MapReduce: A programming model for parallel data processing.
- YARN: Manages resources and schedules tasks across the cluster.
Ecosystem Tools:
- Apache Hive: SQL-like queries for data in HDFS.
- Apache Spark: Real-time data processing engine.
- Apache HBase: NoSQL database for large data storage.
- Apache Sqoop: Transfers data between relational databases and Hadoop.
Together, these tools form a comprehensive ecosystem for managing big data, from storage to analytics.
The Hadoop Big Data Tools can extract the data from sources, such as log files, machine data, or online databases, load them to Hadoop, and perform complex transformations.
In this blog, you will get to know about the Top 21 Hadoop Big Data Tools that are available in the market
Table of Contents
Best 21 Hadoop Big Data Tools
- HBase
- Hive
- Mahout
- Pig
- Spark
- Sqoop
- Avro
- Ambari
- Cassandra
- Chukwa
- ZooKeeper
- NoSQL
- Lucene
- Oozie
- Flume
- Cloud Tools
- Map Reduce
- Impala
- MongoDB
- Apache Storm
- Tableau
1: HBase
- Apache HBase is a non-relational database management system running on top of HDFS that is open-source, distributed, scalable, column-oriented, etc.
- It is modeled after Google’s Bigtable, providing similar capabilities on top of Hadoop Big Data Tools and HDFS.
- HBase is used for real-time, consistent (not “eventually consistent”) read-write operations on big datasets (hundreds of millions or billions of rows) for high throughput and low latency. HBase scales linearly and modularly.
- HBase does not really support SQL queries because it is not an RDBMS. It doesn’t have typed columns, triggers, transactions, secondary indexes, etc. HBase is Java-based and has a Java Native API which can be used to communicate with it. It provides access to DDL and DML like SQL in the case of a relational database.
- HBase provides fast record lookups and updates for large tables. This is something HDFS does not provide. HDFS is more geared towards batch analytics, not real-time, whereas HBase with its columnar storage is ideal for real-time processing.
2: Hive
- Apache Hive is a distributed data warehouse for Hadoop Analytics Tools that allows querying and managing large datasets. These datasets can be queried using SQL syntax. Hive provides access to files in HDFS or other storage systems like HBase. Hive supports the query language HiveQL, which converts SQL-like queries to a DAG of MapReduce, Tez, and Spark jobs.
- Hive follows a ‘schema on read’ model. This means, it just loads the data without first enforcing the schema. The data ingestion is faster since it does not go through strict transformations. But the trouble is the query performance is slower. Unlike HBase which is more suitable for real-time processing, Hive is geared towards batch processing.
3: Mahout
- Apache Mahout is a distributed framework producing scalable machine learning algorithms under Hadoop Analytics Tools for Big Data. Mahout algorithms like clustering, classification, etc. are run on Hadoop but it is not tightly coupled with Hadoop.
- Today the Apache Spark platform gets more focus. Mahout has many Java/Scala libraries for mathematical and statistical operations. You can also read the detailed guide on Hadoop vs Spark.
4: Pig
- Apache Pig is a Big Data Analytics tool which is a high-level data flow tool to analyze large datasets. Pig Latin is the language used for this tool. The pig can run Hadoop jobs in MapReduce, Tez, or Spark.
- Pig converts the queries to MapReduce internally to avoid having to learn to write complex Java programs. So Pig makes it a lot easier for programmers to run queries.
- It can handle structured, semi-structured, and unstructured data. The pig can extract, transform, and load the data into HDFS.
5: Spark
- Apache Spark is one of Hadoop Big Data Tools. It is a unified analytics engine for processing big data and for machine learning applications. It is the biggest open-source data processing project and has seen very widespread adoption.
- While Hadoop is a great tool to process large data, it relies on disk storage making it slow. This makes interactive data analysis a difficult task. Spark, on the other hand, processes in memory making it many, times faster.
- Spark’s RDD (Resilient Distributed Dataset) data structure makes it possible to distribute data across the memory of many machines. Spark also supports several tools including Spark SQL, MLib (for machine learning), and GraphX (for graph processing).
6: Sqoop
- The next tool in Hadoop Big Data Tool is Apache Sqoop. It is a command-line interface used to move bulk data between Hadoop and structured data stores or a mainframe. Data can be imported from an RDBMS into HDFS.
- This data can be transformed in MapReduce and exported back to the RDBMS. It has an import tool to move tables from an RDBMS to HDFS and an export tool to move it back. Sqoop has commands that let you inspect the database. It also has a primitive SQL execution shell.
Streamline your ETL processes with Hevo’s no-code platform, designed to automate complex data workflows effortlessly. With an intuitive interface, Hevo enables smooth data extraction, transformation, and loading—all without manual coding.
- Automate ETL pipelines with ease
- Enjoy flexible, real-time data transformations
- Connect to 150+ data sources, including 60+ free sources
See why Hevo is rated 4.7 on Capterra for data integration excellence.
Get Started with Hevo for Free7: Avro
- Apache Avro is an open-source data serialization system. Avro defines schemas and data types using JSON format. This makes it easy to read and enables implementation with languages that already have JSON libraries. The data is stored in a binary format making it fast and compact.
- Data is stored in its corresponding schema, and hence it is fully self-descriptive. This makes it ideal for scripting languages. When compared to other data exchange formats (such as Thrift, Protocol, etc.) Avro differs in that it does not need code generation because data is always attached to the schema.
- When schema changes (schema evolution), producers and consumers will have different versions of the data, but Avro resolves changes in the schema like missing fields, new fields, etc. Avro has APIs written for many languages like C, C++, C#, Go, Java, Ruby, Python, Scala, Perl, JavaScript, PHP, etc.
8: Ambari
- Apache Ambari is another tool in Hadoop Big Data Tools. It is a web-based tool that can be used by system administrators to provision, manage, and monitor the status of the applications running over the Apache Hadoop clusters. It has a user-friendly interface backed by RESTful APIs that automate operations in the cluster.
- It has support for HDFS, MapReduce, Hive, HBase, Sqoop, Pig, Oozie, HCatalog, and ZooKeeper. Ambari brings the Hadoop ecosystem under one roof to manage and monitor. It acts as the point of control for the cluster.
- Ambari lets you install and configure Hadoop services across multiple hosts. It provides central management for Hadoop services across the cluster.
- It lets you monitor the health of the cluster, alerts you when necessary to troubleshoot problems using Ambari Alert Framework, and collects metrics using Ambari Metrics System.
9: Cassandra
- Apache Cassandra is a NoSQL database that is distributed and highly scalable. There is no single point of failure and it provides highly available service. Cassandra scales linearly. As you add new machines in the cluster (collection of machines/nodes), the read and write throughput increases.
- There are multiple nodes with no master, sharing the same role, so there are no network bottlenecks.
- Failed nodes are replaced with no downtime. Cassandra’s architecture is built to be deployed across multiple data centers for failover recovery and redundancy.
- Cassandra has support for MapReduce, Apache Pig, and Apache Hive in Hadoop Big Data Tools. In the presence of a network partition, a distributed data store has to choose between consistency and availability according to the CAP theorem.
- Cassandra is an AP system, which means it chooses availability over consistency. Consistency levels can be configured. Cassandra uses replicas stored in different data centers. So if one data center fails, the data is still safe.
10: Chukwa
- Apache Chukwa is a large-scale open-source system for log collection and analysis. It is built on top of HDFS and MapReduce framework. Chukwa provides a platform for distributed data collection and processing.
- Chukwa has Agents that emit data, Collectors that receive this data and write it to stable storage, ETL processes for parsing and archiving, Data Analytics Scripts to interpret the health of the Hadoop cluster, and a Hadoop Infrastructure Care Center (HICC), an interface to display data.
11: ZooKeeper
- Apache ZooKeeper is a centralized service for systems to manage a distributed environment with multiple nodes. Distributed applications face trouble with consensus on the master, configuration, members of a group, etc.
- ZooKeeper acts as the distributed configuration service for Hadoop. ZooKeeper reduces the scope for error by maintaining the status of each node in real time. It assigns the node a unique id to identify it. It elects the leader node for coordination.
- ZooKeeper has a simple architecture, is reliable (works even when a node fails), and is scalable. Many Hadoop frameworks use ZooKeeper to coordinate tasks and maintain high availability.
12: NoSQL
- NoSQL, a non-relational database, is independent of schema and can accommodate both structured and unstructured types of data. Moreover, it is easy to scale but due to the lack of a fixed structure, it can not perform joins. This tool is ideal for Distributed Data Stores and therefore, NoSQL databases are used for storing and modifying big data associated with real-time web applications.
- Companies such as Facebook, Google, Twitter, etc., which assemble vast amounts of user data daily, utilize NoSQL databases for their applications. These databases operate on a wide variety of database technologies that are efficient in storing structured, unstructured, semi-structured, and polymorphic data.
13: Lucene
- Lucene is a popular Java library that allows you to incorporate a search feature in a website or application. This tool uses content to a full-text index which enables you to query that index and return results.
- You can sort these results either with respect to the query or arrange them in accordance with a random field like the last modified date. ordered by relevance to the query or sorted by an arbitrary field such as the last modified date of a document.
- Lucene support all kinds of data sources be it SQL Databases, NoSQL Databases, Websites, File System, etc.
14: Oozie
- Apache Oozie is a scheduling system that helps you in managing and execute Hadoop tasks when working in a distributed environment.
- Using Apache Oozie, you can easily schedule your jobs. Moreover, within a task sequence, you can even schedule multiple tasks to run in parallel.
- It is an open-source, scalable, and extensible Java Web Application that activates workflow actions. This tool utilizes the Hadoop runtime engine to implement its tasks.
- Apache Oozie relies on callback and polling to detect if a task is complete. During the start of a new task, Oozie provides a unique HTTP URL to the task and then notifies that same URL once the task is complete. If the activity fails to retrieve the callback URL, Oozie can query the activity for completion.
15: Flume
- Apache Flume is a popular distributed system that streamlines the task of collecting, aggregating, and transferring huge chunks of log data. It operates on a flexible architecture that is easy to use and works on data streams. Moreover, it is highly fault-tolerant and contains numerous failover and recovery mechanisms.
- One of the reasons behind Flume’s popularity is that it provides you with different plans on the basis of reliability, such as “best-effort delivery”, “end-to-end delivery”, etc. The best-effort Delivery avoids failure at the level of Flume Nodes, while the end-to-end delivery ensures delivery even if the Flume Nodes crash.
- Apache Flume collects log data from log files of various web servers and aggregates it into HDFS for further analysis. It has an in-built query processor which facilitates the transformation of each new batch of data before sending it to the intended receiver.
16: Cloud Tools
- A cloud platform is a combination of an operating system and hardware carrying an Internet data center server. It facilitates the co-existence of software and hardware products on a large scale.
- The Public Cloud has made Cloud Tools an integral part of any organization. Nowadays platforms such as Amazon Web Services (AWS), Google Cloud Platform (GCP) & Microsoft Azure are the key providers of Cloud tools.
- Cloud companies provide a wide range of cloud-related products and services, including Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS) solutions. They are easily accessible to everyone and allow you to scale your processes up to any level.
17: Map Reduce
- MapReduce is a computing technique based on Java Programming Language and is useful for distributed computing. It consists of 2 key activities namely Map and Reduces.
- The Map process takes one dataset and converts it into another dataset while breaking individual elements into tuples.
- The Reduce process then takes the output of the Map process and merges those data tuples into a small set of tuples.
- All this occurs at high speed and the MapReduce Technique can work on petabytes of data in one go.
- Users implement this model to divide data present on Hadoop Product Servers into smaller chunks. Eventually, all this data is aggregated in the form of a consolidated output.
18: Impala
- Impala is massive parallel processing (MPP) engine designed for processing querying large Hadoop clusters.
- It is open-source, offers high performance, and maintains a low latency( as compared to its peer Hadoop engines).
- Unlike a similar product Apache Hive, Impala does not operate on MapReduce algorithms. Instead, it is based on a distributed architecture that is responsible for all query executions that run on the same machines. This mechanism allows Impala to overcome the latency issues of Apache Hive.
19: MongoDB
- MongoDB is a NoSQL database that uses a document-oriented model to process JSON FIles. MongoDB isn’t constrained to any specific data structure.
- This implies you don’t have to worry about structuring your data in a particular format or schema for inserting it in a Mongo Database.
- However, this property makes the process of designing a MongoDB ETL, a challenging endeavor.
- MongoDB uses replica sets of data and ensures high availability. A replica set usually contains 2 or more copies of your data.
- Each of these replica-set copies can act as the primary data at any time. Moreover, all the reads and writes operations are carried out on the chosen primary replica by default. The second copy is used as a backup.
20: Apache Storm
- In a very brief time since Twitter acquired it, Apache Storm has become a preferred tool for distributed real-time processing.
- This tool allows you to work on huge data chunks seamlessly and is similar to Hadoop. Apache Storm is an open-source application developed in Java and Clojure. Today it is a key player in the market for real-time Data Analytics.
- Apache Storm finds major applications in Machine learning tools, Data Computation, Unbounded Stream Processing, etc. Furthermore, it is capable of taking continuous message streams as input and can output simultaneously to multiple systems.
21: Tableau
- Tableau is one of the most robust and convenient Data Visualization and BI tools on the market. Its BI features allow you to extract deep insights from your raw data easily.
- Moreover, its data visualization capabilities are unmatched in the current market. It allows you to personalize your views and develop engaging reports and graphs for your business.
- Combining Tableau with the correct hardware and the right operating systems, you can implement all Tableau products in virtualized environments. Furthermore, this tool has no restrictions on the number of views that you can develop for your business.
What is Hadoop Ecosystem?
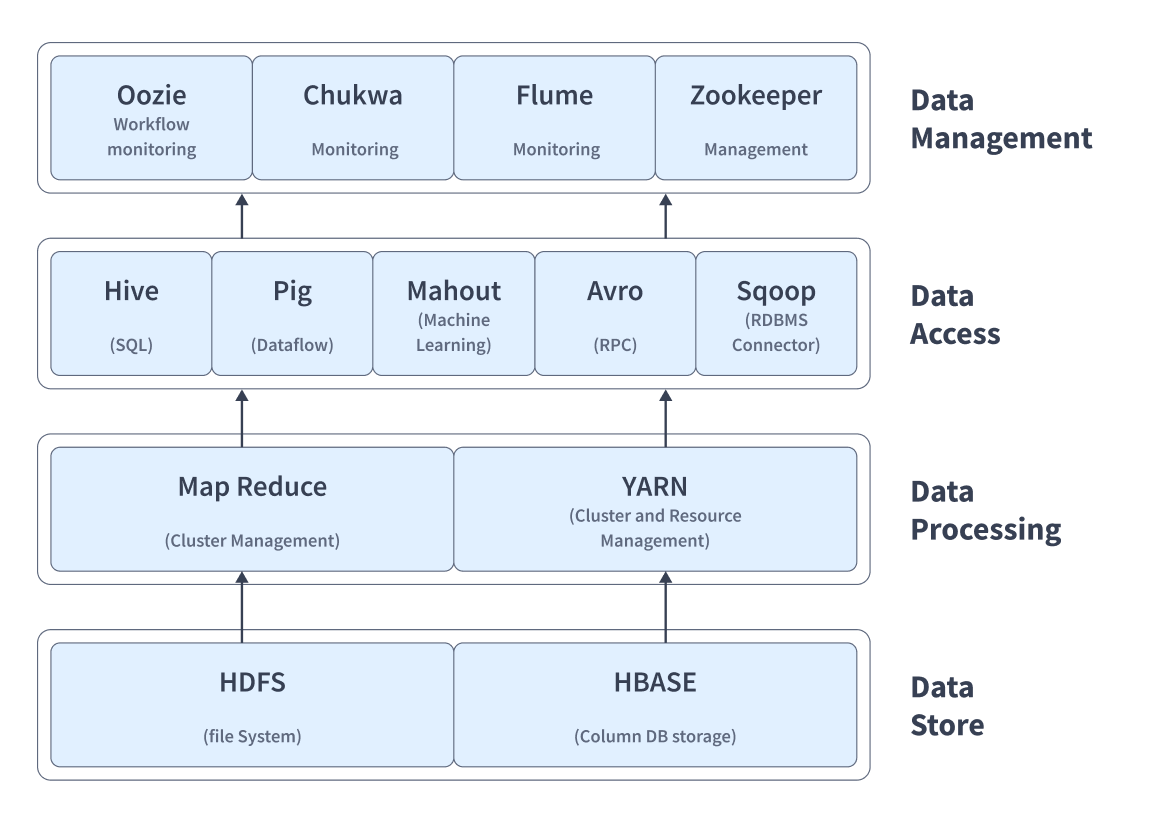
Here’s a brief intro to these major components of the Hadoop Ecosystem.
- HDFS: Hadoop Distributed File System (HDFS), is one of the largest Apache projects and forms the primary storage system of Hadoop capable of storing large files running over the cluster of commodity hardware. It follows a NameNode and DataNode architecture.
- MapReduce: It is a programming-based Data Processing layer of Hadoop capable of processing large structured as well as unstructured datasets. It is also capable of parallelly managing very large data files by dividing the job into a set of sub-jobs.
- Pig: This is a high-level scripting language used for Query-based processing of data services. Its main objective is to execute queries for larger datasets within Hadoop and further organize the final output in the desired format.
- Spark: Apache Spark is an in-memory data processing engine suitable for various operations. It features Java, Python, Scala, and R programming languages, and also supports SQL, Data Streaming, Machine Learning, and Graph Processing.
Why Hadoop Big Data Tools are Needed?
- Data will always be a part of your workflows, no matter where you work or what you do. The amount of data produced every day is truly staggering.
- Having a large amount of data isn’t the problem, but being able to store and process that data is truly challenging.
- With every organization generating data like never before, companies are constantly seeking to pave the way in Digital Transformation.
- A large amount of data is termed Big Data, and it includes all the unstructured and structured datasets, which need to be managed, stored, and processed. This is where Hadoop Big Data Tools come into the picture.
- Hadoop is an open-source distributed processing framework and is a must-have if you’re looking to pave the way into the Big Data ecosystem.
- With Hadoop Big Data Tools, you can efficiently handle absorption, analysis, storage, and data maintenance issues. You can further execute Advanced Analytics, Predictive Analytics, Data Mining, and Machine Learning applications. Hadoop Big Data Tools can make your journey in Big Data quite easy.
Conclusion
You have seen some very important Hadoop Big Data Tools in the above list. Although Hadoop is a useful big data storage and processing platform, it can also be limiting as the storage is cheap, but the processing is expensive.
You cannot complete a job in sub-seconds as it takes a longer time. It is also not a transactional system as source data does not change, so you have to keep importing it over and over again. However, third-party services like Hevo Data can guarantee you smooth data storage and processing.
Give Hevo a try by signing up for a 14-day free trial today.
FAQs
1. What are the limitations of Hadoop in big data?
Hadoop struggles with real-time processing, handling small files, and complex data management due to its batch processing nature and lack of flexibility.
2. What are the data tools of Hadoop?
Key Hadoop tools include HDFS (storage), MapReduce (processing), YARN (resource management), and tools like Hive, Pig, and HBase for data querying and management.
3. Is Hadoop an effective tool to manage big data?
Hadoop is effective for large-scale, batch processing tasks but less efficient for real-time analytics and handling smaller, varied datasets.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



