




Easily move your data from Webhooks To Redshift to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
Table of Contents
What are Webhooks?
Key Features of Webhooks
What is Amazon Redshift?
Key Features of Amazon Redshift
Why is there a need to integrate Webhooks to Redshift?
How to integrate Webhooks to Redshift using Hevo?
Prerequisites
Steps for integrating Webhooks to Redshift

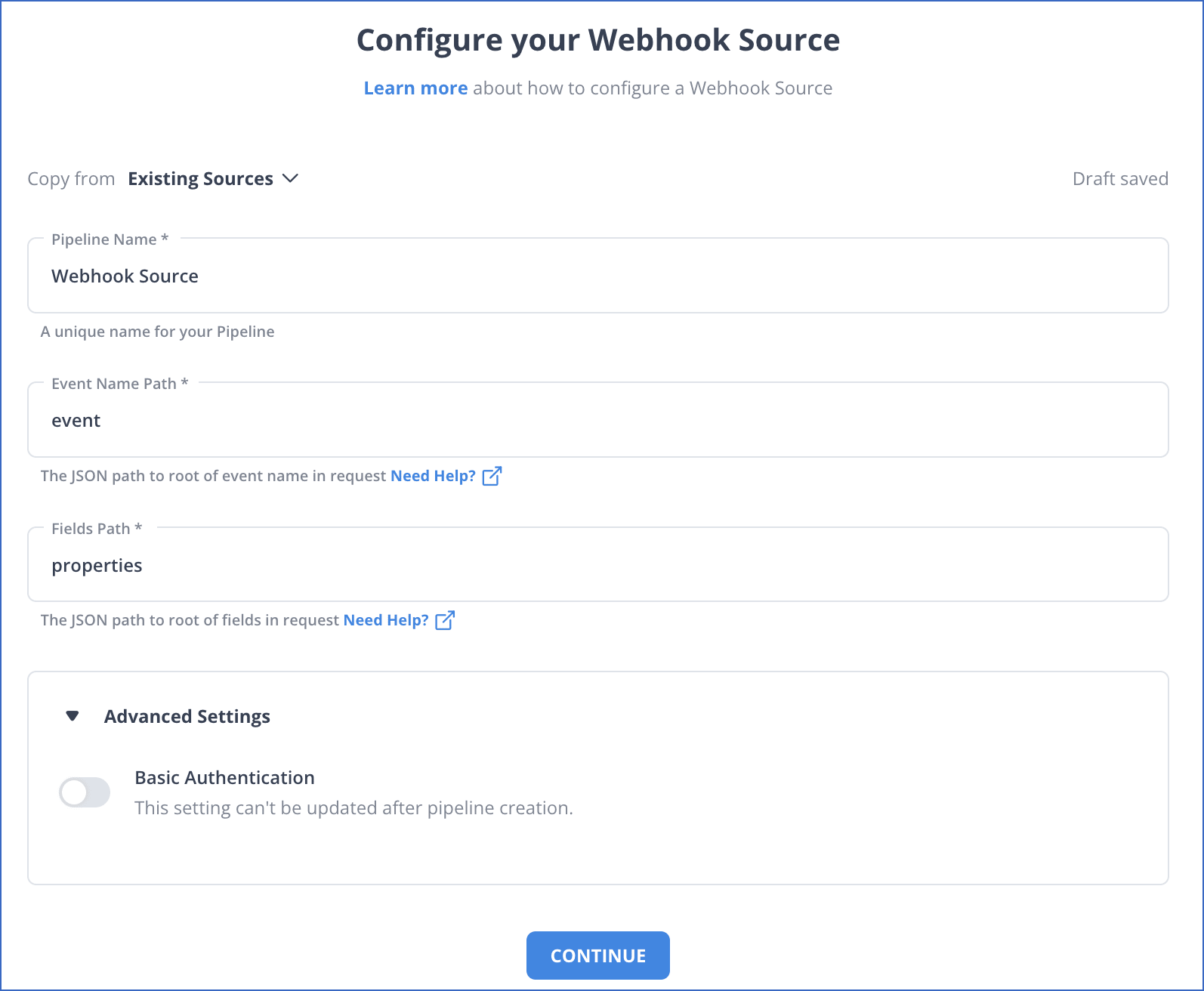
Step 1: Configure Webhooks as a Source
Step 2: Configure Amazon Redshift as a Destination Type

Benefits of using Hevo to integrate Webhooks to Redshift
Conclusion
Learn how to integrate various data sources with Redshift, including efficiently connecting Twilio to Redshift. Access our detailed guides and resources here.
FAQ on WebHook to Redshift
How to connect a webhook to a database?
To connect a webhook to a database:
1. Set up an API endpoint to receive the webhook request.
2. Parse the incoming data from the webhook.
3. Insert the parsed data into your database (e.g., MySQL, MongoDB) using the appropriate database query.
How do I add a webhook to AWS?
To add a webhook to AWS:
1. Create an API Gateway endpoint to receive the webhook.
2. Set up a Lambda function as the backend for the API Gateway to process the incoming webhook data.
3. The Lambda function can then store the data in a database like DynamoDB or trigger other AWS services. Example flow: Webhook → API Gateway → Lambda → DynamoDB.
How do I receive data from a webhook?
To receive data from a webhook:
1. Set up an HTTP server with an endpoint that can accept POST requests.
2. Configure the webhook source to send data to this endpoint.
3. The server will parse the request body (usually JSON or form data) to access the data.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



