

Cloud Technology has revolutionized the way businesses manage and process data. Previously, there was a high demand for hardware to store and manage data, but that comes with a cost and requires highly experienced people to manage it. Cloud computing alleviates these challenges by allowing users to access and pay for only the resources they need when they need them.
One such example of Cloud Computing is the AWS Glue Catalog, which we will discuss today. Read along the blog to learn about the AWS Glue Catalog and the process of setting up your ETL pipeline!
Table of Contents
What is AWS Glue Catalog?
AWS Glue Catalog is a centralized repository that stores data metadata and provides a unified interface for users to query, analyze, and search the data formats, schemas, and sources.
AWS Glue Catalog is a part of AWS Glue service, a fully managed ETL service, which acts as a persistent metadata store. It manages the data across AWS services like S3, Redshift, and databases like RDS. AWS Glue Catalog stores the metadata for both structured and unstructured data and provides a unified interface to view the information.
The key feature of the AWS Glue Catalog is that it streamlines data discovery. Using crawlers, it can automatically discover and register data from various sources and store information like table definitions, schemas, datatypes, and partitioning information in a centralized repository. This catalog can then be shared across many AWS services like Athena, Redshift Spectrum, and EMR.
Hevo is the only real-time ELT platform that is both cost-effective and reliable. With more than 150+ plug-and-play integrations, Hevo simplifies your ELT jobs because of the following features:
- In-flight Transformations: Transform your data within the pipeline using a drag-n-drop interface or python scripts.
- Automated Schema Mapping: Automatically map Event Types and fields from your Source to the corresponding tables and columns in the Destination
- Easy Integration: Connect Google Sheets to Snowflake in just 2 Steps without any coding.
Find out why Hevo is rated 4.3 on G2 and join 2000+ happy customers who vouch on Hevo’s no code pipelines.
Get Started with Hevo for FreeKey Features of AWS Glue Catalog
- Automatic Schema Discovery: AWS Glue Data Catalog Crawler is an amazing feature that crawls through various data sources and discovers the metadata automatically. This helps in creating data schemas, understanding data types, and managing data, especially when dealing with large and diverse datasets.
- Central Metadata Repository: The AWS Glue Data Catalog acts as a centralized metadata store that enables easy access and management of data schemas, table definitions, and other metadata. This centralization of the repository helps in maintaining data consistency and governance.
- Schema Versioning: AWS Glue has a serverless feature called AWS Glue Schema Registry that manages schema versioning. This feature keeps track of schema changes happened over time and it ensures that correct data transformations are applied to the dataset as and when they evolve.
- Integration with AWS Services: The AWS Glue Data Catalog integrates seamlessly with other AWS services like Amazon Athena, Redshift Spectrum, and EMR, enabling efficient data querying and analysis. This integration provides a unified view of data across different services and environments.
- Partition Indexing and Optimization: Partitioning the data improves query performance and tool efficiency. By indexing the partition key, data retrieval and processing can be faster.
- Security and Access Control: AWS Glue uses AWS IAM policies to secure and encrypt data in transit and in rest. These security features allow users to protect sensitive data according to organizational policies.
Core Components of AWS Glue Catalog
- Databases: Databases are the logical containers that hold table information. They are managed by the AWS IAM policies that help control user access. Databases help organize data and serve as a namespace for tables.
- Tables: Tables are the smallest entity in the Database. They hold information about the data, such as schema, column name, data type, partition information, and location. Services like ETL, Glue Job, and RDS use this information to locate the data and perform queries for analysis.
- Crawlers: AWS Glue Crawler is an amazing feature that crawls through various data sources and discovers the metadata automatically. It performs schema versioning on the data schema as they evolve to keep the most latest version is available for use. Crawlers support various data formats, including JSON, CSV, Parquet, and Avro.
- Classifiers: Classifiers help crawlers understand the structure and format of data. AWS Glue includes built-in classifiers for common data formats, but users can also create custom classifiers to handle proprietary formats or specific data structures.
- Jobs: In AWS Glue, the jobs are the scripts that perform the Extract, Transform, and Load the data from source to destination. The jobs use the metadata stored in the catalog to analyze the data and apply the appropriate transformations.
AWS Glue Data Catalog Use Cases
- Data Lake Management: AWS Glue Catalog is an excellent service that manages data lakes by storing a huge amount of data in it and its schema along with the partition information. These metadata can be used by AWS Lake Formation to manage Glue ETL jobs, crawlers, and the Data Catalog to transport data from one layer of the data lake solution to another.
The Data Catalog helps in organizing the data by providing a structured metadata layer. This metadata enables efficient data discovery, governance, and lifecycle management, ensuring that data assets are easily accessible and secure.
- ETL and Data Analytics: The AWS Glue Data Catalog provides necessary metadata for the ETL process to execute jobs that transform raw data into a more useful format for analysis. This Catalog can be used by Data Analysts and Data Scientists to query and explore the data using various AWS tools like AWS Athena and Redshift Spectrum without worrying about the data schema.
AWS Glue Data Catalog Architecture
The typical architecture of AWS Glue involves the following components:
- Data Sources: There are a variety of data sources in AWS, like S3, Redshift, RDS, and databases. These data sources can be used by AWS Glue crawlers to detect the schema and extract metadata from them.
- Crawlers and Classifiers: Crawlers crawl data from various sources and automatically detect the schema, data formats, and data structure. The metadata is then stored in the Data Catalog for ETL purposes.
- Data Catalog: The AWS Glue Data Catalog is the central repository for the data’s metadata. It includes table definitions, data schema versions, and partition information. The Data Catalog provides a unified interface for querying.
- ETL Jobs: Jobs are basically scripts written in Pyton, Scala, or Java that use the metadata from the Data Catalog and apply the transformation to the data. They can read data from various sources and write it back to a data lake or other destinations.
- Consumers: The consumers can be end-users or applications that consume the data from AWS Glue. They can use the AWS Glue Data Catalog’s metadata for data discovery, analytics, and reporting. The various applications that can consume the data from the AWS Glue Data Catalog are Athena, Redshift Spectrum, and EMR.

Setting Up and Configuring the AWS Glue Data Catalog
AWS Glue Catalog can be created by following the below steps –
Creating a Crawler
- Sign in to AWS Console, search for AWS Glue from the search option, and click to open the AWS Glue page.
- Go to the tutorial section at the bottom and click Add Crawler.

- Once you click on Add Crawler, a new screen will pop up, specify the Crawler name, and say “Flight Test”.

- After specifying the name, click Next. On the next screen, select the data source and click Next.

- On the next screen, select the Data Source as S3 and specify the path of the flight data. The default path is – s3://crawler-public-us-west-2/flight/2016/csv

- Once you fill in all the information, click on Next, and in the next section, select No when asked to Add another data store.

- Once you click Next, you will be asked to create an IAM role to access S3 and run the job. Provide the name of the role and click Next.

- Once you provide the IAM role, you will be asked how you want to schedule your crawler. We suggest you choose the “Run on Demand” option.

- Once you select the scheduler, click next and create the output database.

- Once you create the database, the review page will be open. Review all the settings and click Finish.

- Once you click finish, the crawler will be created instantly and available for run. Click on Run Crawler to start execution.
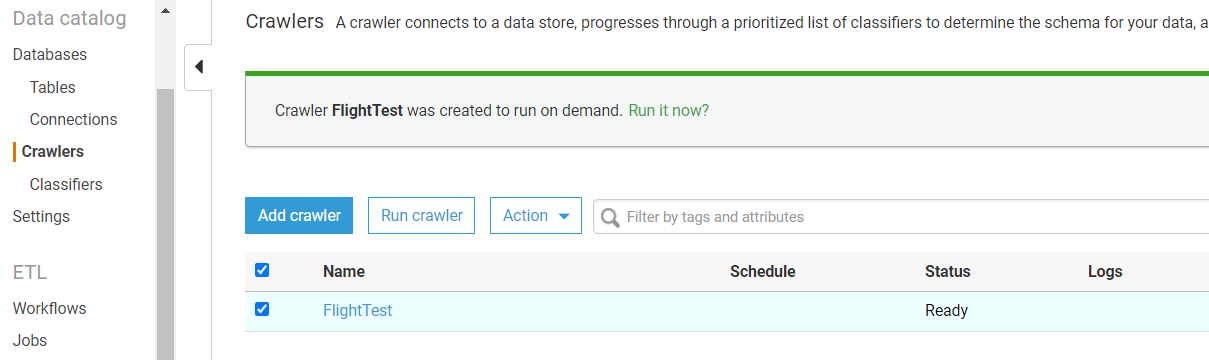
Viewing the Table
Once the crawler is successfully executed, you can see the table and its metadata created in the defined DB. Follow the below steps to explore the created table –
- On the bottom section of Glue Tutorial, click on Explore table.
- This will head you to the tables section, and click on the csv table created inside the flights-db database.
- Click on the table, and click View Details.

- You can see all the information/properties of the table.

- If you scroll down further to the same page, you can see the table metadata fetched automatically from the file.

Configuring Job
- In this section, you have to configure the job to move data from S3 to the table using the crawler.

- Once you click on Add Job, a job configuration page will open. Fill in the required details, such as the job name, IAM role, type of execution, and other parameters.

- After the configuration, click on Next. On the next page, select the data source “CSV” and click on Next.

- Choose a transformation type – Change Schema.
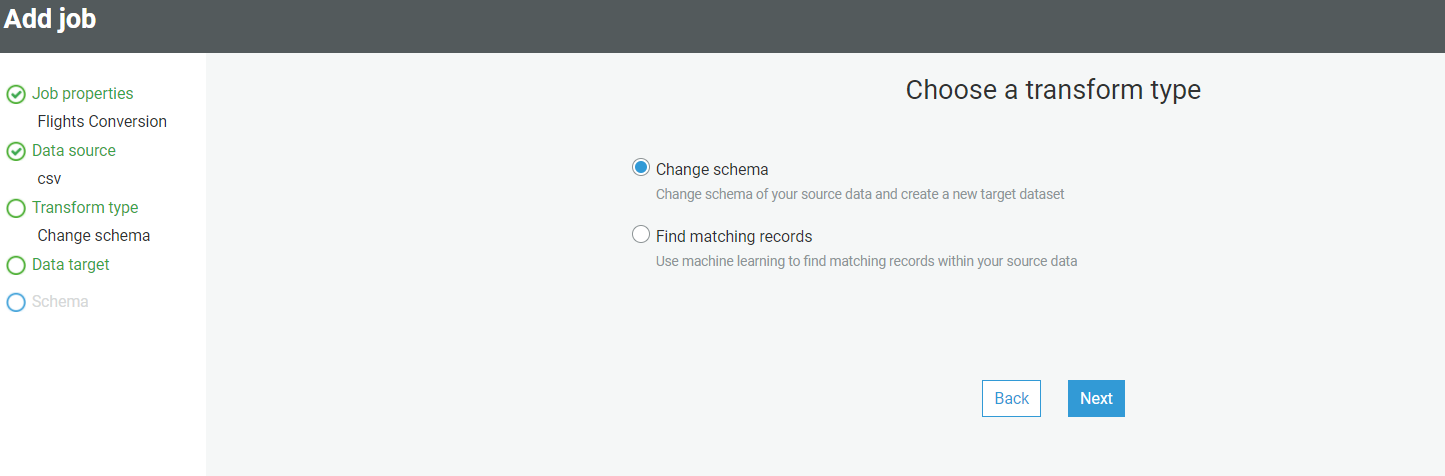
- Choose the data target, and select the table “CSV” created above.

- On the next page, you’ll see the source of the target mapping information. Add/delete the columns that you wish to. We suggest keeping the default mapping and clicking next.

- Click on the save job, and on the next page, you can see the flow diagram of the job and edit the script generated.

- You can use the inbuilt transform feature of AWS Glue to add some predefined transformation to the data.

- Check the status of the Job. Once it is completed, head to the table section to see the data.

- Click on View Data; it will open Athena and preview a few records from the data.

Benefits and Limitations
Benefits
- AWS Glue Data Catalog is the single source of truth for the data as it keeps the metadata in its Centralised Schema Repository.
- AWS Glue Data Catalog integrates very well with other AWS Services like Redshift, RDS, and streaming workflow.
- AWS Glue is scalable and it can scale as per the data requirements.
- AWS offers Pay-As-You-Go, that enables you to pay only for the resources that you use, without worrying about the overhead costs.

Limitations
- AWS Glue Data Catalog is limited to only AWS services, and hence, it may not be used when a multi-cloud structure is in place.
- Setting up the jobs and crawlers can be complex for beginners.
- Setting up the IAM policies is complicated and may require additional support from Admin/platform engineers.
- While suitable for many use cases, performance may vary based on the size of the data and the complexity of ETL jobs.
Conclusion
In this blog post, we have discussed the AWS Glue Data Catalog and its architecture, example use cases, and how to set up a Crawler that automatically detects the data schema and helps users perform ETL with ease.
However, if you’re looking for a no-code solution, then Hevo Data provides a platform to perform ETL with minimal or no coding effort.
Sign-up for a 14 day Free Trial
Frequently Asked Questions
1. How big is the AWS Glue data catalog?
AWS Glue Data Catalog offers free storage for up to 1 million objects. Beyond that, you’ll be charged $1 for every additional 100,000 objects per month.
2. What is the difference between S3 and glue?
S3 is object storage for storing and retrieving data, while Glue is a serverless ETL service used to prepare and load data for analytics.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



