




Retrieval-augmented generation (RAG Architecture) enhances response generation of a Large Language Model (LLM) by incorporating external information retrieval. It searches a database for information beyond the model’s pre-trained knowledge base, significantly improving the accuracy and relevance of the generated responses.
Does that make sense? No?
Let’s dive in!
Table of Contents
Introduction to Large Language Models (LLMs)
As a result of significant advancement in the Natural Language Processing (NLP) domain of Artificial Intelligence, Large Language Models (LLMs) were brought to life. These models are trained on extensive datasets comprising diverse textual content acquiring billions of parameters during training, enabling them to generate, comprehend and manipulate human knowledge with remarkable accuracy.
But since they are trained on static datasets up to a certain point in time, they do have limitations in their temporal knowledge and hence their ability to provide current information is constrained. This temporal limitation can make them less effective for tasks that require the latest data, such as real-time tasks or dynamic information retrieval.
Pre-trained LLM models also known as Foundation Models (FMs) can only consider a limited amount of text in their responses, known as context windows and are more useful with general tasks as they are trained over a vast amount of general, public data.
Some models like GPT-3 can see up to around 12 pages of text (that’s 4,096 tokens of context). That’s not good enough for most knowledge bases. But when one needs to employ FMs for any specific use cases, business domain or have it function over organizations private data, there are a few ways it can be like:
- Prompt Engineering
- RAG / RAG Agents
- FMs Fine Tuning
- Building LLMs from ground up
The list is based on the increasing difficulty level of customizing any Foundation Model.
In this article we will talk about RAG, exploring its different infrastructural as well as architectural components and dive deep into how it functions.
A non-RAG LLM Application
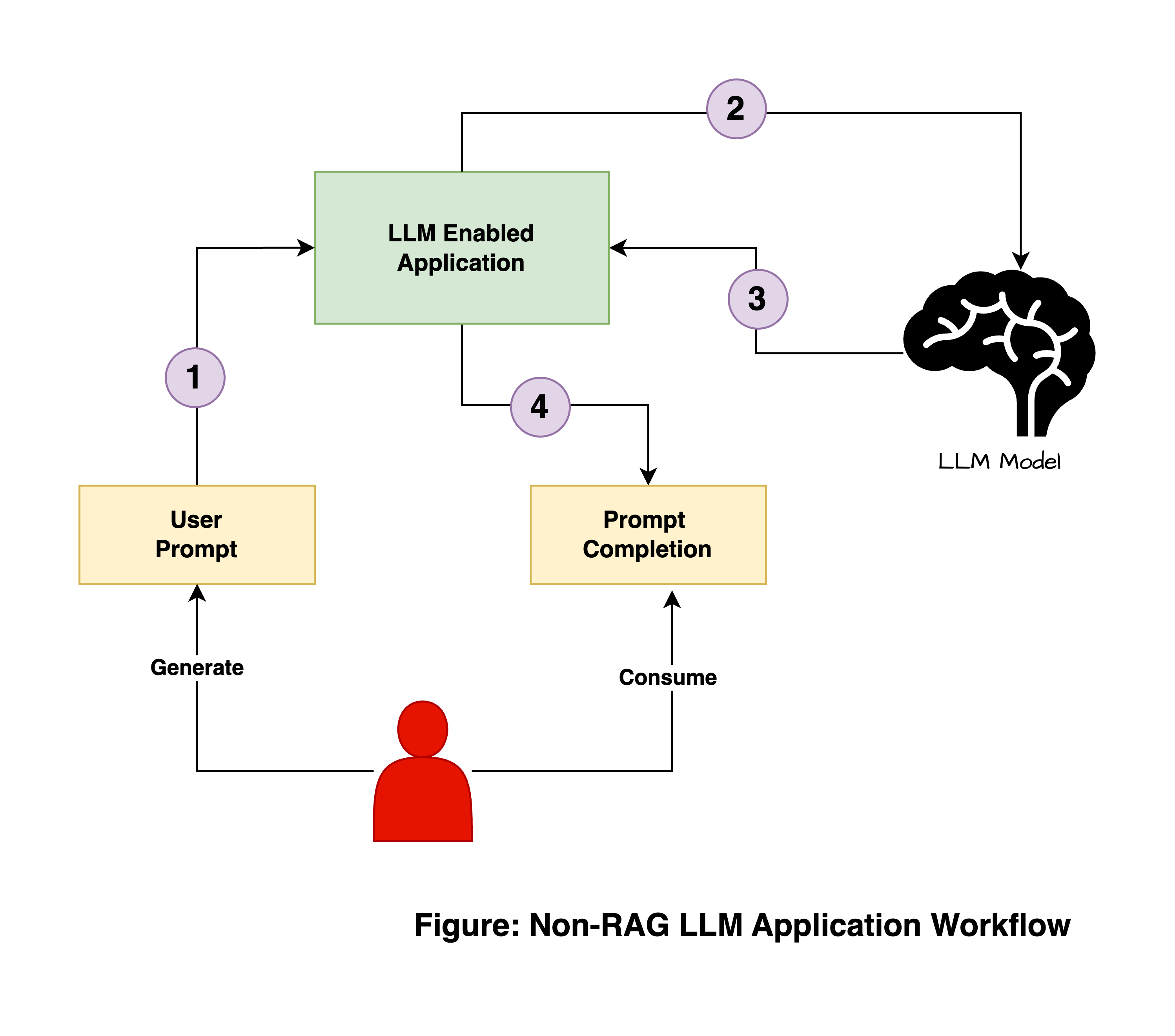
Let’s start with a simple (non-RAG) LLM process.
(1). The user sends a prompt to the LLM-enabled app
(2). The app connects to the LLM and feeds the prompt as input
(3). The LLM predicts the words for the output as accurately as possible and
(4). Feeds the ‘prompt completion’ back to the app to display to the user
Now in the above setting, let’s assume the LLM used is Google’s BERT (one of the first language models) that is trained over public data from google. The application will respond very much accurately to questions like “Which is the tallest mountain in the world?” but will fail to answer questions like “What is the growth rate of my company?” as it only has access to knowledge base fed while training but doesn’t have access to company’s private data to answer the second question.
This is where RAG comes to play by adding database capabilities to an LLM Application. So, instead of fitting data into the LLM every time we launch a new GenAI service or product, we can allow the LLM direct access to the relevant data while generating an answer to the user’s prompt.
Now, let’s assemble different components of a RAG to build an end-to-end application:
Infrastructural Components of a Retrieval Augmented Generation (RAG)
Let’s start with building the RAG infrastructure concepts, which comprise of the following:
1. Data Integration / Ingestion
The very first step while building a RAG application involves gathering data from various sources such as databases, APIs or central data lake with a goal of compiling a comprehensive datasets that can include both structured and unstructured data ensuring all the relevant information is available for retrieval and subsequent generation tasks. Effective data integration requires robust data connectors and workflow to automate data collection.
2. Extract, Transform, Normalize and Load (ETNL)
Once relevant data is ingested, it’s very crucial to prepare it for the downstream processes. Data is extracted from the source systems, ensuring that all the necessary information is captured and further transformed into a consistent format. After a controlled transformation data is then standardized to remove any redundancies and inconsistencies, making it uniform and reliable. Finally data is then loaded into the data repository where it can be accessed by the retrieval module.
3. Data Repository
The data repository is the core component of a RAG application where all the processed data is stored. It consists of several key elements:
- Data Cataloging: Like any other data repository, data catalogs store the metadata about the actual data stored which includes information on data origin, structure, relationships, facilitating easy discovery and management of data assets.
- Storage/Indexing: Unlike web-applications that use SQL/NoSQL databases to store data, RAG solutions use high-performance storage solutions (e.g. Elasticsearch, Apache Solr etc.) to store and index data, enabling efficient search and retrieval operations with low latency and high throughput. These storage solutions act as an extension to the knowledge base of the LLM model we would use in the RAG solution to further handle any queries related to our private data.
- Vector Embeddings: Textual data is embedded into high-dimensional vector spaces using advanced NLP models (e.g. BERT, GPT etc.) known as embedding models. These embeddings facilitate semantic search capabilities and similarity-based retrieval. It is important to use the same embedding model as the Foundation Model we are using while building the application.
- Knowledge Graphs: Data in the repository can also be represented in graph databases (e.g., Neo4j, Amazon Neptune etc.) to capture intricate relationships between entities and enable complex query, handling and enhancing the semantic understanding of the data.
This diagram pictures the components of a architecture and shows the conceptual tasks and components used in the indexing and retrieval processes. Its primary goal is to highlight the different phases data go through and the shared components used by both processes. Data Scientists generally design such a system with the help of frameworks such as Langchain or Llama Index.
Extraction & Indexing
The indexing stage in a RAG architecture lays the groundwork for efficient information retrieval. It involves transforming a vast collection of data sources, regardless of structure (unstructured documents like PDFs, semi-structured data like JSON, or structured data from databases), into a format readily usable by LLMs. This process can be broken down into a Load-Transform-Embed-Store workflow.

- The indexing process begins with data loaders, they retrieve data from various sources, including unstructured documents (e.g., PDFs, docs), semi-structured data (e.g., XML, JSON, CSV), and even structured data residing in SQL databases using data connectors. These loaders then convert the retrieved data into a standardized document format for further processing.
- Document splitters then organize the data and prepare it for efficient processing by the embedding model. They achieve this by segmenting the documents into logical units – sentences or paragraphs – based on predefined rules. This segmentation ensures that information remains semantically intact while preparing it for further processing.
- Following segmentation, the tokenizer steps in. It takes each logical unit (e.g., paragraph) from the document splitter and breaks it into its fundamental building blocks: tokens. These tokens can be individual words, sub-words, or even characters, depending on the chosen embedding model and the desired level of granularity. Accurate tokenization is critical for tasks that rely on understanding the meaning of the text, as it forms the basis for how the LLM interprets the information. Since the tokenizer essentially defines the vocabulary understood by the entire architecture, utilizing a single shared tokenizer process across all components dealing with text processing and encoding is recommended. Using a single tokenizer ensures consistency throughout the system.

- Once tokenization is complete, the embedding model converts each token into a numerical vector representation, capturing its semantic meaning within the context of the surrounding text. Pre-trained embedding models, either word embeddings or contextual embeddings, achieve this by mapping the tokens into these vector representations.
- Finally, an indexing component takes over. It packages the generated embedding vectors along with any associated metadata (e.g., document source information) and sends them to a specialized embedding database – the vector database (vector DB) – for efficient storage. This database becomes the foundation for the retrieval stage, where the RAG architecture searches for relevant information based on user queries.
The vector database plays a crucial role in efficient retrieval. It stores the embedding vectors in a three-dimensional space, allowing for fast and effective search operations based on vector similarity. The embedding model paves the way for the retrieval process, where the RAG architecture efficiently locates relevant information from the indexed data based on user queries, ultimately enabling the LLM to generate informative and relevant responses.
Retrieval & Generation
The retrieval stage in an RAG architecture is where the magic happens. Here, the system efficiently locates relevant information from the indexed data to enhance the LLM generation capabilities. This process ensures that the user’s query (often called a prompt in NLP) is processed in the same ‘language’ used for creating and storing the embeddings during indexing.

The process begins with the user submitting a query, often phrased as a natural language prompt (question, instruction, etc.).
- Once the user submits the query (called a prompt), the prompt must be translated into the same ‘language’ used to create and store the embeddings during indexing. But before processing the prompt further, it’s essential to apply guardrails to ensure the prompt meets certain safety, ethical, and quality standards. Guardrails play a crucial role in preventing the system’s misuse for malicious purposes and ensuring that the generated responses align with the organization’s ethical guidelines and expectations.
- To achieve this, the system leverages the same tokenizer and embedding model employed in the indexing stage. The tokenizer breaks the prompt into tokens (words or subwords) and then converts it into a vector representation using the pre-trained model. This vector representation captures the semantic meaning of the prompt within the context of the larger language model.
- With the query transformed into a vector, the retrieval process can efficiently search through the collections of embeddings stored in the vector database. This search hinges on the principle of vector similarity – the system seeks embeddings within the database that closely resemble the prompt’s vector representation. These retrieved embeddings, typically representing relevant vectors from the indexed data, are referred to as chunks.
- Not all retrieved chunks hold equal weight. A ranking service steps in to prioritize the most relevant ones. This service applies a ranking algorithm, considering factors like the degree of similarity between the chunk’s embedding and the prompt’s vector, to assign a score to each retrieved chunk. This scoring helps identify the chunk most likely to contain information that addresses the user’s query.
- Finally, the integration module presents the prepared passages alongside the embedded prompt to the LLM. This empowers the LLM to process the information, drawing upon its knowledge and understanding of language to generate a comprehensive and informative response that aligns with the user’s query.

The journey of an RAG response continues after the LLM generates its initial output. Several crucial steps ensure the user receives a refined, informative, and well-presented response. This stage encompasses post-processing, formatting, user interface integration, and, ultimately, user presentation.
The raw output from the LLM might undergo some post-processing steps to enhance its quality. This could involve tasks like:
- Text Normalization: Ensuring consistency in formatting, such as converting all numbers to a standard format or handling special characters.
- Spell Checking: Identifying and correcting any potential typos or spelling errors.
- Grammar Correction: Refining the grammatical structure of the generated text for clarity and coherence.
- Redundancy Removal: Eliminating unnecessary repetition or irrelevant information that may clutter the response.
These post-processing steps ensure the generated response is informative, grammatically sound, and easy for the user to understand. Additionally, guardrails can evaluate and filter the generated outputs to ensure they meet predefined criteria. This may involve automated checks for compliance with safety, ethical, or quality standards, as well as human review processes to verify the suitability of the generated content.
The generated response might need formatting adjustments before presentation, depending on the application and user interface requirements. This formatting could involve structuring and adding visual elements. When structuring the response, the content is organized into well-defined paragraphs for improved readability. Post-processing adds visual elements such as bullet points, headers, or even multimedia content (if applicable) and enhances clarity and user engagement.
Once processed and formatted, the response is seamlessly integrated into the application or platform’s user interface. This user interface could be a web page, mobile app, chat interface, or any other medium through which users interact with the system. This integration ensures a smooth flow of information from the RAG architecture to the user experience layer.
Finally, the polished and formatted response reaches the user through the chosen interface. The user can then review the information, provide necessary feedback, or take further actions based on the response. Depending on the application, users can interact further with the system by asking follow-up questions or initiating new tasks.
Throughout this final stage, a critical focus remains on the user experience. The generated response should meet the user’s accuracy, relevance, and readability expectations. Additionally, error-handling mechanisms should be in place to address any potential issues that arise during response generation or presentation. User feedback loops can also be implemented to continuously improve the performance of the RAG model and ensure it delivers consistently valuable experiences.
By effectively managing these final steps, RAG architectures can not only generate high-quality responses but also ensure they are presented in a way that maximizes user satisfaction and understanding.
Building and maintaining data pipelines can be technically challenging and time-consuming. With Hevo, you can easily set up and manage your pipelines without any coding. With its intuitive interface, you can get your pipelines up and running in minutes.
Key-Benefits of using Hevo:
- Real-time data ingestion
- No-code platform
- Pre and Post-load transformations
- Automated Schema Mapping.
Join over 2000+ customers across 45 countries who’ve streamlined their data operations with Hevo. Rated as 4.7 on Capterra, Hevo is the No.1 choice for modern data teams.
Get Started with Hevo for FreeConclusion:
- RAG (Retrieval-Augmented Generation) architecture combines retrieval-based (a retriever) and generative models (a generator) to enhance the performance of natural language processing tasks. The retriever component searches a large corpus of documents to find relevant information based on the input query, while the generator component, often a sequence-to-sequence model like GPT or BERT, takes the retrieved documents and the original query to generate a coherent and contextually accurate response.
- The integration of these components allows RAG models to leverage both the extensive information available in the retrieval corpus and the sophisticated language generation capabilities of modern NLP models. The architecture efficiency addresses the limitations of purely generative models, which might lack factual accuracy, and purely retrieval-based models, which may struggle to generate fluid and contextually appropriate language.
Combine the power of RAG with Streamlined Data Integration. Try Hevo Today for 14 day free trial!
Frequently Asked Questions
1. What is the difference between RAG and LLM?
LLMs are powerful language models trained on massive datasets. RAG builds on LLMs by letting them access external knowledge bases for more accurate and up-to-date responses.
2. How to implement RAG in LLM?
- Select a suitable pre-trained language model.
- Collect and organize relevant information.
- Use vector databases or search engines.
- Create a system to convert user queries into search queries.
- Combine retrieved information with the user’s query as input.
- Optimize how retrieved info is presented to the LLM.
- Use the LLM to create answers based on the augmented input.
- Refine and format the LLM’s output as needed.
- Continuously evaluate and improve system performance.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link

