

Working with different types of data has become essential in the Big Data era because analysis of this data gives you valuable information that enables you to make better data-driven decisions for your business. When working with this complex set of business data, you’ll need to unify and load this data into your desired destination at some point.
While some data transfers may be easy others can be challenging due to the large volumes of data, along with source & destination incompatibility. To run these tasks smoothly, Data Warehouses need some central repository like AWS Glue Data Catalog, Alation, etc. for maintaining metadata and ETL jobs.
To make these tasks easier, ETL tools have come into the picture. These tools help in moving data from one place to another. AWS Glue Data is a software developed by Amazon that keeps a tab of all the metadata related to an ETL tool. In this article, we will learn about ETL tools, their advantages, and AWS Glue Data Catalog.
Table of Contents
What is AWS Glue Data Catalog?
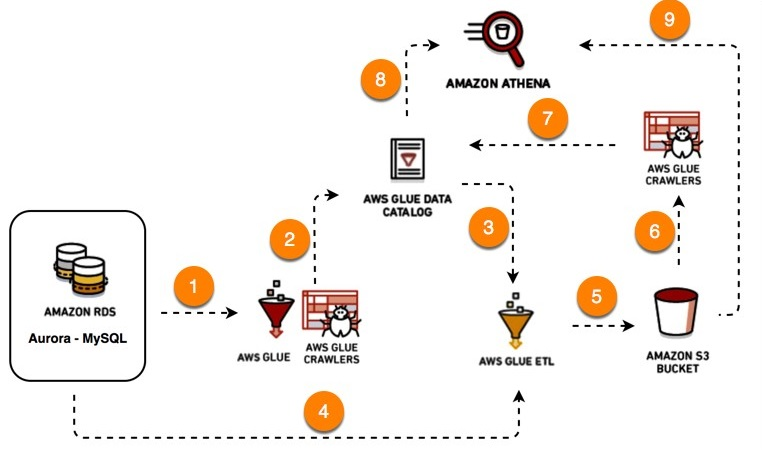
Amazon AWS Glue Data Catalog is a Data Catalog that stores all the metadata related to the AWS ETL software. An ETL tool deals with a lot of data. It has information about the source and destination and keeps a tab on the data being transferred, the underlying mechanisms, system failures, etc. For all this, an ETL tool needs to store all the required metadata.
AWS Glue Data Catalog tracks runtime metrics and stores the indexes, locations of data, schemas, etc. It basically keeps track of all the ETL jobs being performed on AWS Glue. All this metadata is stored in the form of tables where each table represents a different data store.
Applications of AWS Glue Data Catalog
Before diving into this concept, you need to understand why you need the AWS Glue Data Catalog :
- Keeps you informed because all the data related to ETL processes is stored.
- Error tracing becomes easier because you can look back into what went wrong and why.
- Easy to ensure fault tolerance because it regularly keeps tabs on the data.
- No need to set up configurations again, as it stores all the configurations and connections.
If it were not for the AWS Glue Data Catalog, you would need to manually keep a tab of data, and this data needs very regular monitoring, which can be a tremendously challenging task.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s automated, No-code platform empowers you with everything you need to have for a smooth data replication experience. Check out what makes Hevo amazing:
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
What are the benefits of Using the Glue Catalog?
The Data Catalog is part of AWS Glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. Key benefits of using AWS Glue Catalog include:
- Metadata Storage: Store metadata about data formats, schemas, and sources, including table definitions, physical locations, and business-relevant attributes.
- Integration with AWS Services: Seamlessly integrates with Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum, providing a unified view of your data across these services.
- Support for Diverse Data Types: Enables governance, efficient ETL processes, and flexible querying for structured and semi-structured data.
- Automated Schema Discovery: Automates schema discovery to ensure accurate and efficient data cataloging.
- Up-to-Date Metadata:
- Schedule crawlers to periodically update metadata.
- Manually add or update table details via the AWS Glue console or API.
What are the Components of AWS Glue Data Catalog?
The AWS Glue Data Catalog consists of the following components:
1) Databases and Tables
Databases and Tables make up the Data Catalog. A Table can only exist in one Database. Your Database can contain Tables from any of the AWS Glue-supported sources.
2) Crawlers and Classifiers
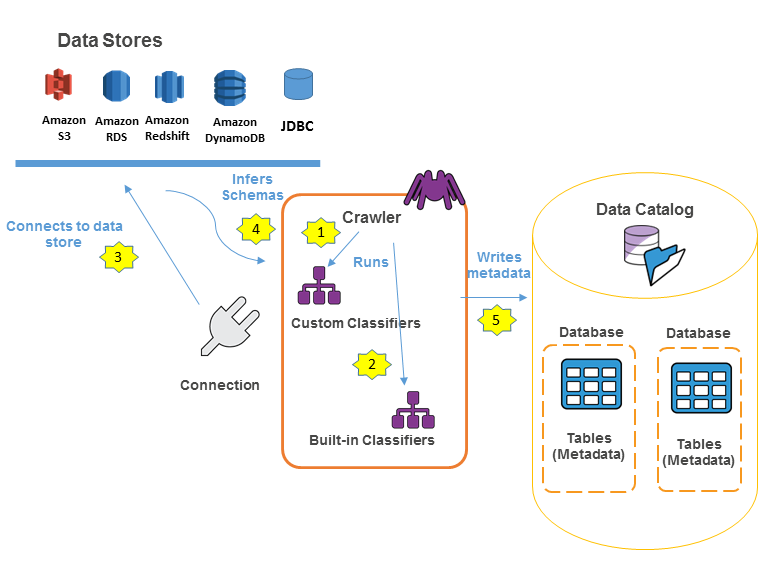
An AWS Glue Crawler is an automated tool which discovers, organizes, and catalogues data from multiple sources. It is assisting in the management of metadata as it extracts schema information and stores it in the AWS Glue Data Catalog. Crawlers can be scheduled or run on demand to keep your data in order and updated.
How it works?
- Crawlers scan data sources, extract schema information, and store the metadata in the AWS Glue Data Catalog.
- They assist in the creation or updating of tables in the Data Catalog.
- Also, crawlers can sense schema changes and thereby start ETL operations when necessary.
What it can do?
- Create or update tables in the Data Catalog
- Detect changes in schema or data structure
- Perform ETL operations
- Integrate with AWS analytics services
- Load data and metadata into S3 bucket.
Crawlers can crawl the following data stores via their native interfaces:
- Amazon S3
- DynamoDB
- JDBC-connected data stores, including:
- Amazon Redshift
- Amazon Aurora
- Amazon RDS (Relational Database Service)
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- Publicly accessible databases (on-premises or on another cloud provider environment)
- Aurora
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
Crawlers utilize predefined classifiers to detect schema, though they might face challenges with complex or nested structures, leading to incorrect data types or missing columns. AWS Glue comes with a set of built-in classifiers, but you can also create your own Custom Classifiers.
3) Connections
Connections allow you to centralize connection information such as login credentials and virtual private cloud (VPC) IDs. This saves time because you don’t have to input connection information each time you create a crawler or job.
The following Connection types are available:
- JDBC
- Amazon RDS
- Amazon Redshift
- MongoDB, including Amazon DocumentDB (with MongoDB compatibility)
- Network (designates a connection to a data source within a VPC environment on AWS)
4) AWS Glue Schema Registry
The AWS Glue Schema Registry allows disparate systems to share a serialization and deserialization schema. Assume you have a data producer and a data consumer, for example. Whenever the serialized data is published, the producer is aware of the schema. The consumer makes use of the Schema Registry deserializer library, which extracts the schema version ID from the record payload. The consumer then uses schema to deserialize the data.
With the AWS Glue Schema Registry, you can manage and enforce schemas on your data streaming applications using convenient integrations with the following data input sources:
- Apache Kafka
- Amazon Managed Streaming for Apache Kafka
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Analytics for Apache Flink
- AWS Lambda
The Schema Registry consists of the following components:
- Schemas: A Schema is a representation of the structure and format of a data record.
- Registry: A Registry is a logical container for schemas. You can use registries to organize your schemas and manage access control for your applications.
Read more about AWS Glue and its major aspects.
Benefits and Limitations of AWS Glue Data Catalog
Benefits
Here are the benefits of leveraging AWS Glue Data Catalog:
- Increased Data Visibility: AWS Glue Data Catalog helps you monitor all your data assets by acting as the metadata repository for information on your data sources and stores.
- Automatic ETL Code: AWS Glue can automatically generate ETL Pipeline code in Scala or Python- based on your data sources and destination. This helps you streamline the data integration operations and parallelize heavy workloads.
- Job Scheduling: AWS Glue provides simple tools for creating and following up job tasks based on event triggers and schedules, or perhaps on-demand.
- Pay-as-you-go: AWS Glue doesn’t force you to commit to long-term subscription plans. Instead, you can minimize your usage costs by opting to pay only when you need to use it.
- Serverless: AWS Glue helps you save the effort and time required to build and maintain infrastructure by being a serverless Data Integration service. Amazon provides and manages the servers in AWS Glue.
Limitations
Here are the disadvantages of using AWS Glue:
- Limited Integrations: AWS Glue is only built to work with other AWS services. This means that you won’t be able to integrate it with platforms outside the Amazon ecosystem.
- Requires Technical Knowledge: A few aspects of AWS Glue are not very friendly to non-technical beginners. For example, since all the tasks are run in Apache Spark, you need to be well-versed in Spark to tweak the generated ETL jobs. Apart from this, the ETL code itself can only be worked on by developers who understand Scala or Python.
- Limited Support: When it comes to customizing ETL codes, AWS Glue provides support for only two programming languages: Scala and Python.

Steps to Add Metadata Tables to AWS Glue Data Catalog
Sign in to your AWS account, select AWS Glue Console from the management console, and follow the below-given steps:
- Step 1: Defining Connections in AWS Glue Data Catalog
- Step 2: Defining the Database in AWS Glue Data Catalog
- Step 3: Defining Tables in AWS Glue Data Catalog
- Step 4: Defining Crawlers in AWS Glue Data Catalog
- Step 5: Adding Tables in AWS Glue Data Catalog
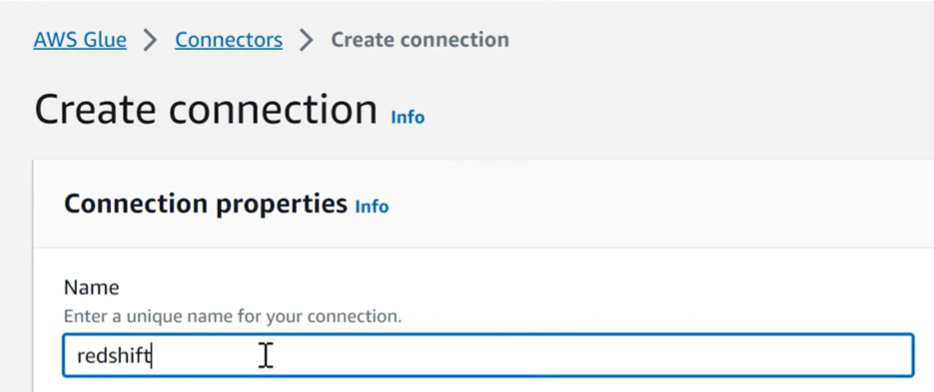
Step 1: Defining Connections in AWS Glue Data Catalog
- Creating connections helps you store the login credentials, URI string, and connection information for a particular data store (source or target).
- By creating connections, you don’t have to configure this every time you run a Crawler. Go to Connections in AWS Glue Console.
- In the connection wizard, specify the connection name and connection type and choose whether you require an SSL connection.
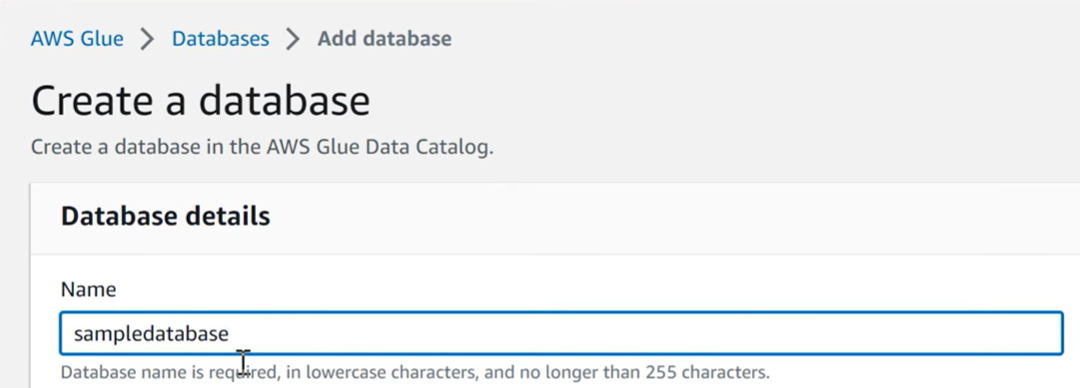
Step 2: Defining the Database in AWS Glue Data Catalog
- First, define a database in your AWS Glue Catalog. Select the Databases tab from the Glue Data console. In this Database tab, you can create a new database by clicking on Add Database.
- In the window that opens up, type the name of the database and its description.
- You can also edit an existing one with the Edit option and delete a database using the Delete option in the Action tab.
Step 3: Defining Tables in AWS Glue Data Catalog
- A single table in the AWS Glue Data Catalog can belong only to one database.
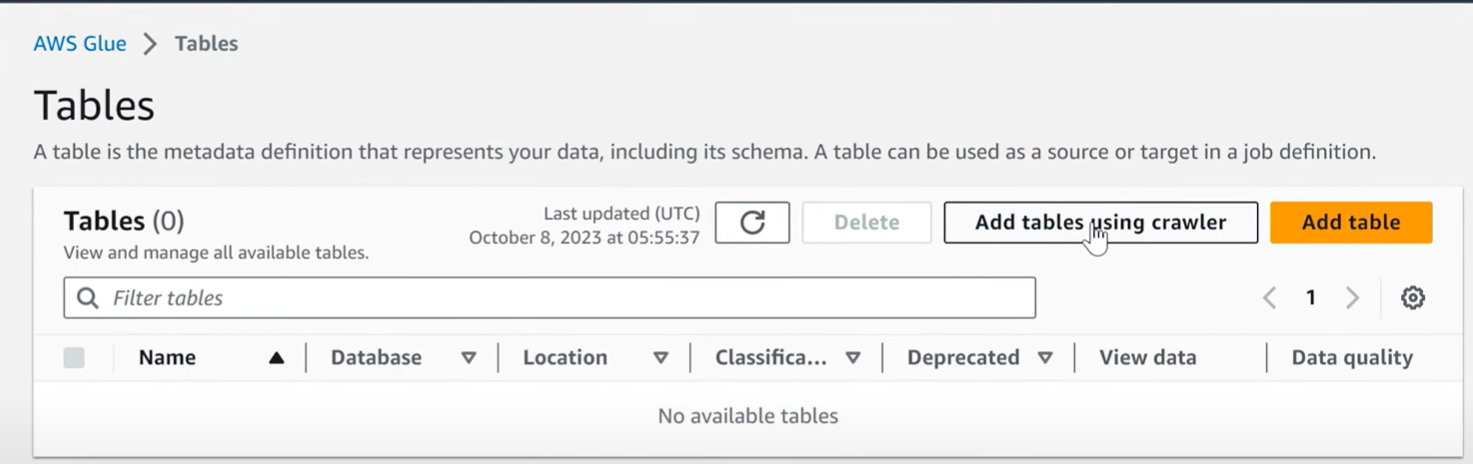
- To add a table to your AWS Glue Data Catalog, choose the Tables tab in your Glue Data console.
- In that, choose Add Tables using a Crawler. Now, an Add Crawler wizard pops up.
Step 4: Defining Crawlers in AWS Glue Data Catalog
- Before defining the Crawlers there are prerequisites you must implement first.
- You have to set the Identity and Access Management configurations first.
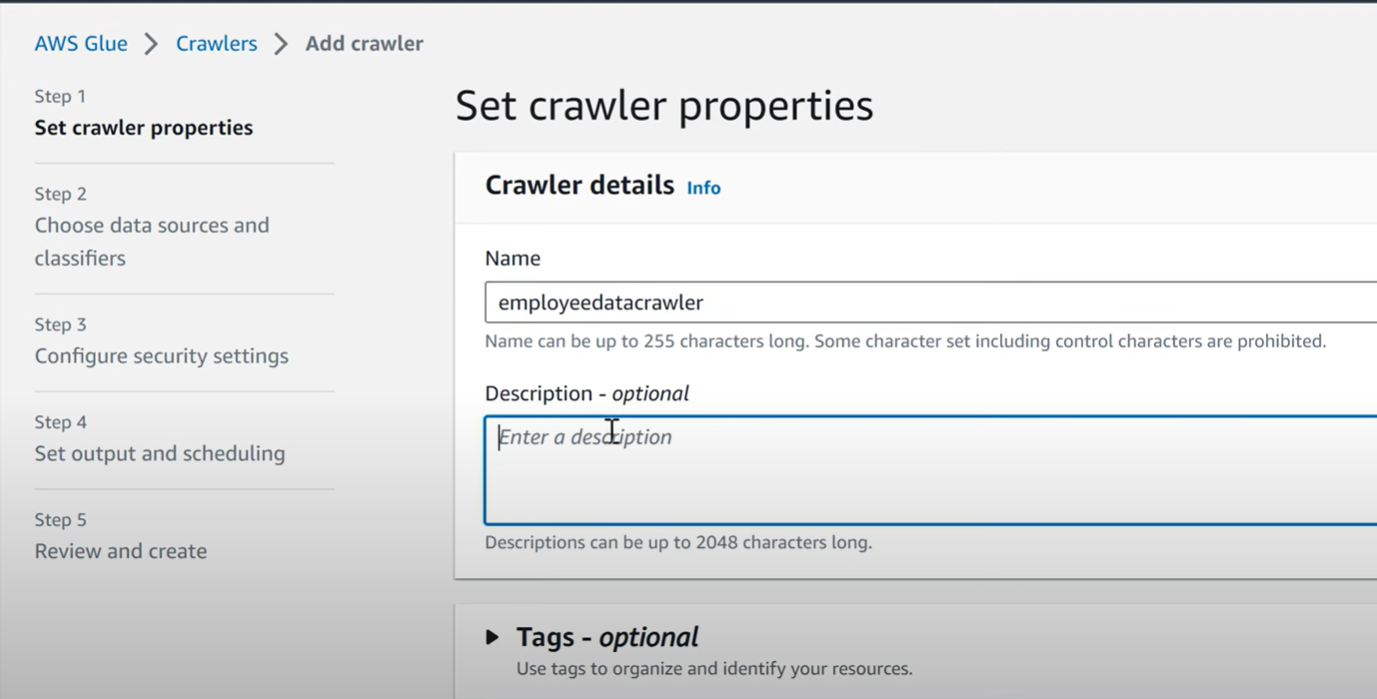
- Now, choose Crawlers in the AWS Glue Catalog Console.
- Choose Add Crawler. A Crawler wizard will take you through the remaining steps.
Step 5: Adding Tables in AWS Glue Data Catalog
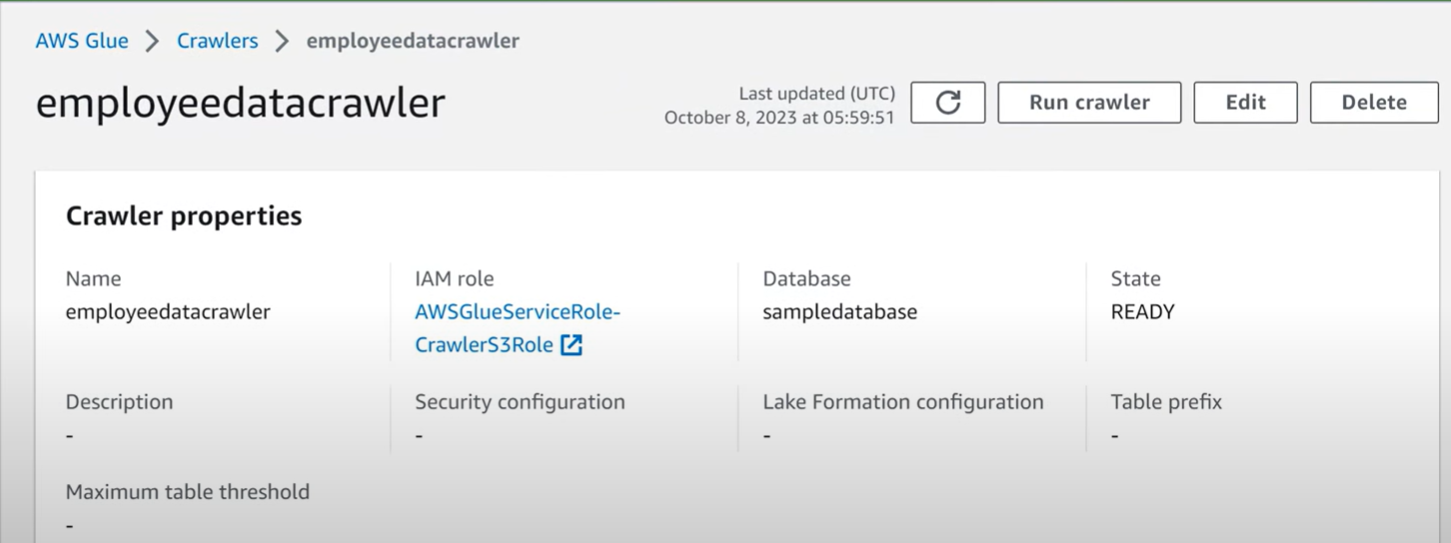
- After you define a Crawler, you can run the Crawler.
- If the Crawler runs successfully it creates metadata table definitions for your AWS Glue Data Catalog.
AWS Glue vs EMR: Key Differences
| Aspect | AWS Glue | AWS EMR |
| Type | Serverless ETL System | Managed Big Data platform |
| Pricing | Pay-as-you-go, approx. $21/DPU per day | Cost varies, approx. $14-$16 per configuration |
| Automation | Automates monitoring, writing, and executing ETL jobs | Requires manual setup and management |
| Infrastructure | It can be costly and complex | Requires setup of custom EC2 instance clusters |
| Flexibility | Limited configuration options | High flexibility and power |
| Ease of Use | Easy to get started with | Can be costly and complex |
| Use Cases | Suitable for automated ETL workflows | Ideal for processing and analyzing large data volumes |
| Querying | Not primarily designed for SQL queries | Supports SQL queries using Presto |
Conclusion
In this article, you learned about ETL tools, their benefits, and how AWS Glue Data Catalog helps store and work with metadata. Why create all these configurations and connections when you can use an ETL tool that manages its metadata independently?
Hevo Data is an all-in-one cloud-based ETL pipeline that will not only help you transfer data but also transform it into an analysis-ready form. Hevo’s native integration with 150+ sources (including 60+ free sources) ensures you can move your data without the need to write complex ETL scripts. Hevo’s automated data transfer, data source connectors, and pre-post transformations are advanced compared to Apache airflow. It will make your life easier and make data migration hassle-free.
Want to take Hevo for a ride? Sign Up for a 14-day free trial and simplify your data integration process. Do check out the pricing details to understand which plan fulfills all your business needs.
Share your experience of working with AWS Glue Data Catalog in the comments section below!
FAQs
1. Is the AWS Glue catalog a hive metastore?
You can use AWS Glue Data Catalog as a Hive metastore. It stores metadata about data in your data lakes and databases; hence, it is compatible with Hive and other big data tools.
2. How do I access my glue data catalog?
You can access your Glue Data Catalog from the AWS Management Console, AWS Glue API, or AWS CLI. In the console, navigate to the AWS Glue service, and you’ll find the Data Catalog in the “Databases” section.
3. What is the purpose of a glue crawler?
A Glue crawler automatically discovers and catalogs metadata from your data sources, such as S3 buckets or databases. It keeps your Data Catalog updated by identifying new or changed data and defining the schema for easier querying and analysis.




