About Ebury
Ebury is a Global FinTech company, they apply new technologies to enhance and automate financial services and processes to small and medium-sized businesses trade and transact internationally by eliminating boundaries related to more traditional procedures. Founded in 2009, Ebury is now positioned among the fastest-growing FinTech companies with over 1000 employees serving more than 45000 clients every day.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
Ebury was founded in 2009 with the aim to remove global financial barriers that many organizations face across various industries using technology solutions developed in line with its customers’ needs over the years and making it easily accessible to all on its online platform.
Meet Juan Ramos, Analytics Engineer at Ebury. Juan and his 14 member team consisting of 3 Analytics Engineers, 5 Data Analysts, 3 Data Engineers, a Data Product Manager, a Data Scientist, and a Machine Learning Engineer are together responsible for all data products used by Ebury. They build data products that enable fast, accurate decision-making and enforce data quality, freshness, and reproducibility standards.

Data Challenges
Data plays a critical role in ensuring the smooth execution of daily operations both internally and externally. All business verticals, ranging from sales to core platform products are reliant on data to function at an optimal level. Also, being a global firm handling financial data from over 49,000 businesses, Ebury needs to comply with the regulatory laws of multiple regions.

Our projects have a huge impact on Ebury. On the sales side, we are responsible for the sales transactions attribution model, which is used to enable a complex system of commissions that benefits over 400 sales people. Similarly, on the platform side, we have a reinforcement model in production that has allowed us to obtain greater revenue in different fields. Also, regulations obligate us to update data on an hourly basis at least.
We need an extremely reliable and high-performing data pipeline to keep up with our data needs. To meet these requirements we were using Fivetran before Hevo. But we decided to switch after being disappointed with some bugs in Fivetran’s History Mode and the lacking customer support after reaching out to them. Their high pricing didn't help either.
The Solution
After facing these issues for several months, Juan decided to look for a more reliable data pipeline solution. During this process, Juan evaluated Hevo with Stitch, Fivetran, and Matillion.
Juan had the following requirements from a data pipeline tool-
It should deliver data in SCD2 or SCD4 format as History data is required to meet regulatory requirements.
It should automatically adapt to schema changes as source schema changes are very often and pipelines would require a lot of maintenance if this feature wasn’t present
To meet regulatory requirements, it should have a minimum load frequency of at least 1 hour
Juan concluded that Hevo was the best available solution as it met all their requirements, with some added benefits -
Append-only mode: Allows Ebury to get the history of changes, enabling them to meet regulatory requirements without relying on an in-house solution.
Activate: Hevo’s Activate provides Ebury the ability to load data back to Salesforce eliminating the need for another tool, or an in-house solution.
Load frequency: Using Hevo, Juan can load data every 15 minutes, giving Ebury access to near real-time data.
Hevo was the most mature Extract and Load solution available, along with Fivetran and Stitch but it had better customer service and attractive pricing. Switching to a Modern Data Stack with Hevo as our go-to pipeline solution has allowed us to boost team collaboration and improve data reliability, and with that, the trust of our stakeholders on the data we serve.
Juan and his team now use a combination of Hevo and Airflow to load data from their HR System - Bob, Quantum, Netsuite, Salesforce, and Customer data to their BigQuery data warehouse. After undergoing a series of transformations using dbt, business users analyze this data using Looker. Using Hevo Activate, aggregated data is also loaded back to Salesforce.
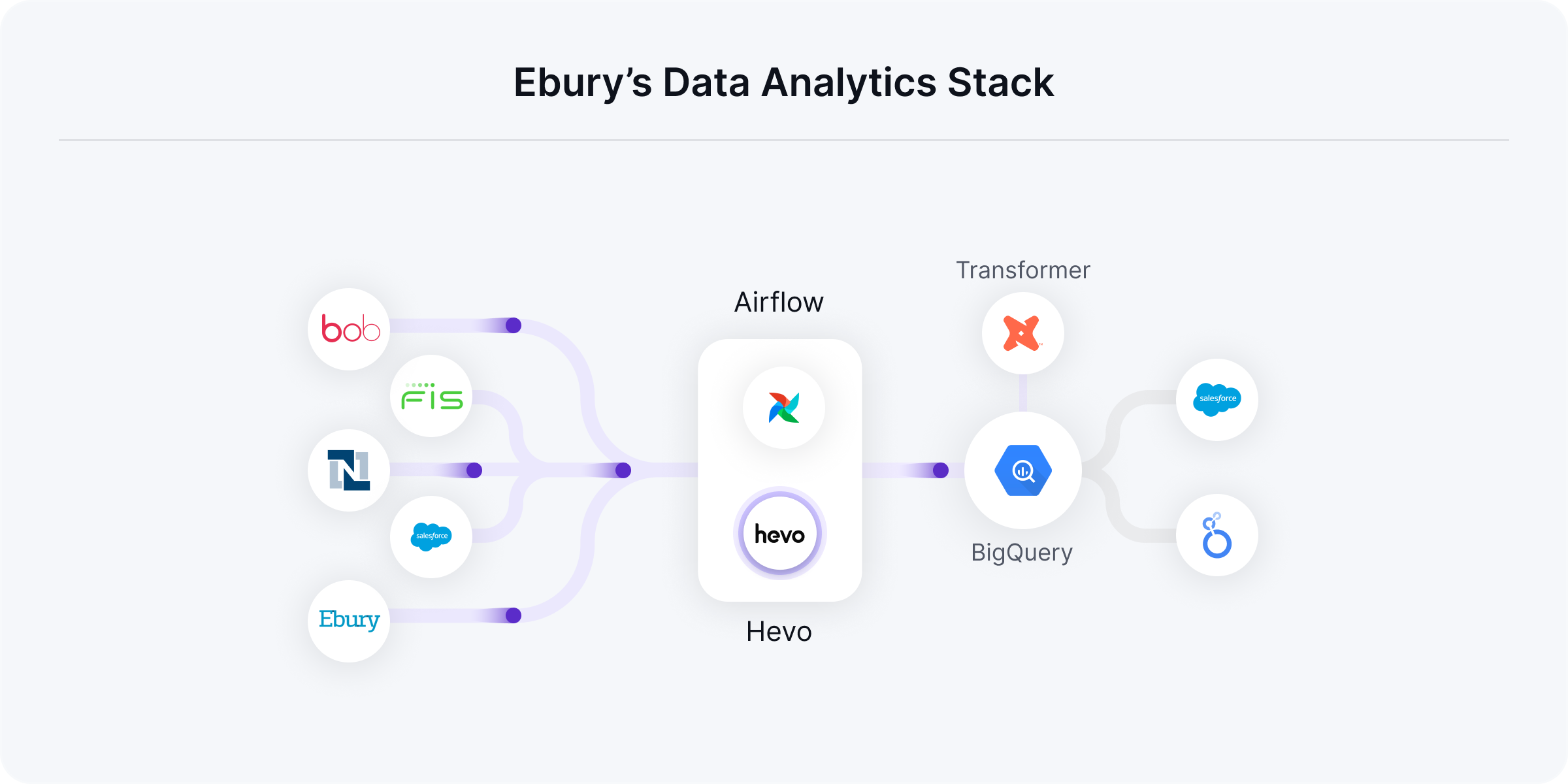
Key Results
Upgrading to a Modern Data Stack has enabled Ebury to achieve near real-time reporting, tightly-coupled run time, and reduce errors in production. Additionally, Hevo has helped improve data reliability and boost collaboration between different teams.
With Hevo, our data is more reliable as it was compared to Fivetran at a way better pricing. Hevo allows us to build complex pipelines with ease and after factoring in the excellent customer service and reverse ETL functionality, it is undoubtedly the best solution available in the market.
As a next step, Juan wants to start migrating all of Ebury’s data pipelines to Hevo to reduce dependency on its Airflow in-house solution to achieve a more reliable, maintenance-free data pipeline experience. Hevo is proud to be Ebury’s growth partner in their exciting journey to create a financial world without borders.
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.