About Hornblower
Hornblower Group is a global leader in experiences and transportation. Hornblower Group’s corporate businesses consist of three premier experience divisions: American Queen Voyages, its overnight cruising division; City Experiences, its land and water-based experiences as well as ferry and transportation services; and Journey Beyond, Australia’s leading experiential travel group. With a collection of brands spanning a 100 year history, Hornblower Group today has its footprint spanning 114 countries and territories, and 125 U.S. cities.
 What do they do?
What do they do?
 Industry
Industry
 Location
Location
With a collection of brands spanning a rich 100-year history, the Hornblower Group is a global experiences and transportation leader with an unmatched reputation for delivering amazing experiences for its guests. Hornblower Group’s corporate businesses are comprised of three premier experience divisions: American Queen Voyages®, its overnight cruising division; City Experiences, its land and water-based experiences as well as ferry and transportation services; and Journey Beyond, Australia’s leading experiential travel group.
With a company footprint that spans 114 countries and territories, and 125 U.S. cities, serving more than 30 million guests served annually across offerings including water and land-based experiences, overnight cruise experiences, and ferry and transportation services, data is critical for its marketing team to manage bookings and discover insights for growth.
Karan, a data scientist at Hornblower, manages the data infrastructure for the marketing and consumer insight team and delivers the required data, dashboard, and insights.

Data Challenges
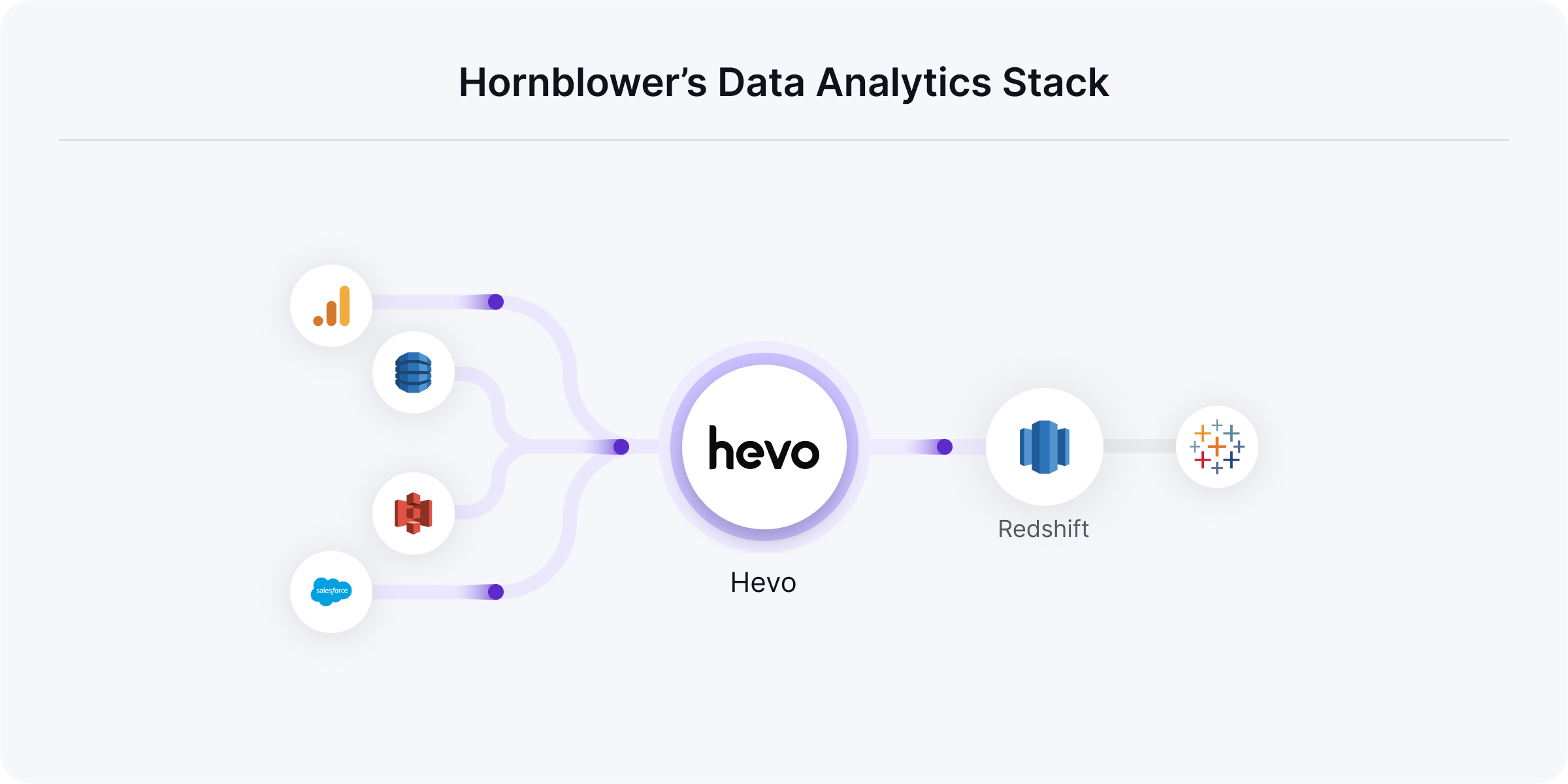
Most of Hornblower's data is produced by its booking platform, Anchor, which they store in DynamoDb. Additionally, the website, CRM, survey, loyalty rewards, and call center data are recorded on various tools like Google Analytics, Salesforce, and more.
All this data is super critical for the marketing team to gain insights on booking reservation history, website performance, customers, product performance, and more to improve marketing performance and deliver a fantastic customer experience.
The data team at Hornblower was using AWS Glue to move all the data to Redshift. It was economical to move data from DynamoDb using Glue (because of the AWS eco-system). However, it had a few challenges, especially for non-AWS sources.
Hornblower produces a massive volume of data because of the millions of customers they serve and thousands of products they offer. The cost of moving all this data to the warehouse was skyrocketing. And all this data was not useful, thus eating up unnecessary events.
Karan wanted to optimize the stack to strategically move only the required data to the warehouse and scale cost-effectively.
But, if Karan had used traditional methods to move data strategically, it would have become a huge hassle to create and manage pipelines - crawling only selected data from these sources is a highly manual task. He would have needed an engineering team, which would require additional investment.
Investing in hiring a few engineers over growth opportunities would have resulted in lower business impact and ROI. It was not wise, especially in the growth stage they are in.
The Solution
Hornblower started looking for a solution to strategically move data to the warehouse without investing much in engineering resources. They found Hevo Data to be the right solution for them, as it managed all the jobs and functions of data engineering without setting up a team.

Data engineering is like an orchestra where you need the right people to play each instrument of their own, but Hevo Data is like a band on its own. So, you don't need all the players.
The unparalleled harmony of pre-load transformation and automated schema management helps them move only the required data to the warehouse without manually creating tables. The no-code and highly intuitive interface enable them to set up pipelines instantly in just a few clicks.
Using Hevo Data, Karan can now effortlessly move critical marketing data from their key sources to the warehouse and deliver required dashboards and insights like reservation windows, website performance insights to different stakeholders.
Hornblower's website has 6 different properties. With Hevo Data, they move only the critical information about booking, products, etc. for each property from Google Analytics to the warehouse.
Karan and his team have also set up pipelines for Salesforce, using which they effortlessly load only 12-15 required objects, like contacts, orders, and leads out of 1000 available objects. Additionally, they use DynamoDB connector to move a few critical objects on top of the other important ones they are moving using Glue.
Now, Karan is super confident about handling any ad-hoc data pipeline requirements in no time. For example, he recently got a request to move 10,000 JSON files from S3, which would usually have required hours of work earlier because of the data partitioning involved. However, with Hevo Data, JSON files were intelligently parsed and loaded to the warehouse.
Key Results
Hornblower runs around 75 pipelines on Hevo Data and is able to move only the required data to the warehouse. Hevo Data fully manages all the data engineering duties, thus dismissing the need to hire at least 2-3 data engineers.
The result? It saves a lot of precious dollars by avoiding the movement of unnecessary events and saving on the cost of engineers. These dollars are now deployed on data-driven marketing activities that drive business growth.
We saved the cost of two or three data engineers with Hevo Data depending on connected sources and data volume we processed through Hevo.
The marketing team has access to all the required data and insights to make data-driven decisions, with a lesser cost of moving data. They can track 3500+ listed products to understand the ones selling well and calculate margins for each product to determine the ones to stop selling. They analyze their website funnel to optimize their conversion rate for more bookings. The team has complete insight into the booking window to discover trends and can plan marketing activities for each product.
They have created dashboards displaying each port's booking and website performance, which enables each port's general manager to manage bookings and deliver a seamless experience.
With Hevo Data, you create a connection out of 1000 objects, select 10 objects you really need, apply minimal transformations, and Hevo Data will take care of it. It will run every day, send you notifications, you can go back, you can restart the pipeline, and it will just refresh the data.
In the end, Karan is super happy to be able to mature the data stack by strategically moving data to the warehouse, where Hevo Data takes full responsibility for data pipelines.
Excited to see Hevo in action and understand how a modern data stack can help your business grow? Sign up for our 14-day free trial or register for a personalized demo with our product expert.