
DynamoDB is Amazon’s document-oriented, high-performance, NoSQL Database. Given that it is a NoSQL database, it is hard to run SQL queries to analyze the data. It is essential to move data from DynamoDB to Redshift and convert it into a relational format for seamless analysis.
This article will give you a comprehensive guide to set up DynamoDB to Redshift Integration. It will also provide you with a brief introduction to DynamoDB and Redshift. You will also explore 2 methods to Integrate DynamoDB and Redshift in the further sections. Let’s get started.
Table of Contents
Prerequisites
You will have a much easier time understanding the ways for setting up DynamoDB to Redshift Integration if you have gone through the following aspects:
- An active AWS (Amazon Web Service) account.
- Working knowledge of Database and Data Warehouse.
- A clear idea regarding the type of data is to be transferred.
- Working knowledge of Amazon DynamoDB and Amazon Redshift would be an added advantage.
Method 1: Using Copy Utility to Manually Set up DynamoDB to Redshift Integration
This method involves the use of COPY utility to set up DynamoDB to Redshift Integration. This process of writing custom code to perform DynamoDB to Redshift replication is tedious and needs a whole bunch of precious engineering resources invested in this. As your data grows, the complexities will grow too, making it necessary to invest resources on an ongoing basis for monitoring and maintenance.
Method 2: Using Hevo Data to Set up DynamoDB to Redshift Integration
Hevo Data is an Automated Data Pipeline platform that provides you with a hassle-free solution to replicate data from DynamoDB to Redshift within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of not only loading data from 150+ sources such as DynamoDB but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
Get Started with Hevo for FreeIntroduction to Amazon DynamoDB

Fully managed by Amazon DynamoDB is a NoSQL database service that provides high-speed and highly scalable performance. DynamoDB can handle around 20 million requests per second. Its serverless architecture and on-demand scalability make it a solution that is widely preferred.
Introduction to Amazon Redshift

A widely used Data Warehouse, Amazon Redshift is an enterprise-class RDBMS. Amazon Redshift provides a high-performance MPP, columnar storage set up, highly efficient targeted data compression encoding schemes, making it a natural choice for Data Warehousing and analytical needs.
Amazon Redshift has excellent business intelligence abilities and a robust SQL-based interface. Amazon Redshift allows you to perform complex data analysis queries, complex joins with other tables in your AWS Redshift cluster and queries can be used in any reporting application to create dashboards or reports.
Method 1: Using Copy Utility to Manually Set up DynamoDB to Redshift Integration
As a prerequisite, you must have a table created in Amazon Redshift before loading data from the DynamoDB table to Redshift. As we are copying data from NoSQL DB to RDBMS, we need to apply some changes/transformations before loading it to the target database. For example, some of the DynamoDB data types do not correspond directly to those of Amazon Redshift. While loading, one should ensure that each column in the Redshift table is mapped to the correct data type and size. Below is the step-by-step procedure to set up DynamoDB to Redshift Integration.
Step 1.1: Before you migrate data from DynamoDB to Redshift create a table in Redshift using the following command as shown by the image below.
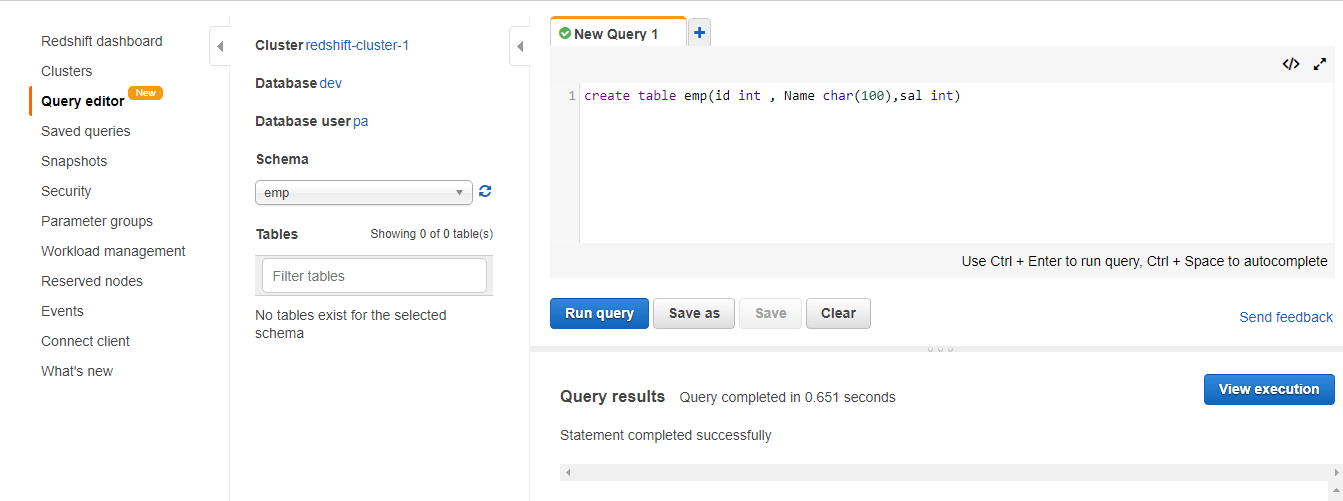
Step 1.2: Create a table in DynamoDB by logging into the AWS console as shown below.

Step 1.3: Add data into DynamoDB Table by clicking on Create Item.
Step 1.4: Use the COPY command to copy data from DynamoDB to Redshift in the Employee table as shown below.
copy emp.emp from 'dynamodb://Employee' iam_role 'IAM_Role' readratio 10; 
Step 1.5: Verify that data got copied successfully.

Limitations of using Copy Utility to Manually Set up DynamoDB to Redshift Integration
There are a handful of limitations while performing ETL from DynamoDB to Redshift using the Copy utility. Read the following:
- DynamoDB table names can contain up to 255 characters, including ‘.’ (dot) and ‘-‘ (dash) characters, and are case-sensitive. However, Amazon Redshift table names are limited to 127 characters, cannot include dots or dashes, and are not case-sensitive. Also, we cannot use Amazon Redshift reserved words.
- Unlike SQL Databases, DynamoDB does not support NULL. Interpretation of empty or blank attribute values in DynamoDB should be specified to Redshift. In Redshift, these can be treated as either NULLs or empty fields.
- Following data parameters are not supported along with COPY from DynamoDB:
- FILLRECORD
- ESCAPE
- IGNOREBLANKLINES
- IGNOREHEADER
- NULL
- REMOVEQUOTES
- ACCEPTINVCHARS
- MANIFEST
- ENCRYPT
However, apart from the above-mentioned limitations, the COPY command leverages Redshift’s massively parallel processing(MPP) architecture to read and stream data in parallel from an Amazon DynamoDB table. By leveraging Redshift distribution keys, you can make the best out of Redshift’s parallel processing architecture.
Method 2: Using Hevo Data to Set up DynamoDB to Redshift Integration
Step 2.1: Set up Amazon DynamoDB as your Source

Step 2.2: Configure Amazon Redshift as your Destination

Get more details about Configuring Redshift with Hevo Data.
You now have a real-time pipeline for syncing data from DynamoDB to Redshift.
What Makes Hevo Amazing?
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Auto Schema Mapping: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data from Salesforce and replicates it to the destination schema.
- Quick Setup: Hevo with its automated features, can be set up in minimal time. Moreover, with its simple and interactive UI, it is extremely easy for new customers to work on and perform operations.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.

Conclusion
The process of writing custom code to perform DynamoDB to Redshift replication is tedious and needs a whole bunch of precious engineering resources invested in this. As your data grows, the complexities will grow too, making it necessary to invest resources on an ongoing basis for monitoring and maintenance. Hevo handles all the aforementioned limitations automatically, thereby drastically reducing the effort that you and your team will have to put in.
Businesses can use automated platforms like Hevo Data to set this integration and handle the ETL process. It helps you directly transfer data from a source of your choice to a Data Warehouse, Business Intelligence tools, or any other desired destination in a fully automated and secure manner without having to write any code and will provide you a hassle-free experience.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQ
Q1) Is it possible to load data from Amazon DynamoDB into Amazon Redshift?
Yes, you can load data from DynamoDB into Redshift! You can do this by exporting DynamoDB data to S3 and then loading it into Redshift. A tool like Hevo can simplify this, automating the data transfer for you and saving setup time.
Q2) Is Redshift faster than DynamoDB?
Redshift can be faster for analytical queries and large-scale data analysis, as it’s built for high-performance analytics. DynamoDB, however, is optimized for real-time, fast operations on single records rather than complex analysis.
Q3) What is the difference between Amazon RDS, Redshift, and DynamoDB?
Amazon RDS is for relational databases with traditional SQL support. Redshift is designed for data warehousing and analytics on large datasets, while DynamoDB is a NoSQL database for fast, single-record operations with high availability.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




