
 Key Takeaways
Key TakeawaysIntegrating Amazon DynamoDB with Amazon Redshift is being done using methods like Zero-ETL, DynamoDB Streams with Lambda, or AWS Data Pipeline. Zero-ETL is simplifying real-time transfers, while Lambda and Data Pipeline are offering more flexibility for transformations.
Breakdown of methods:
Method 1: DynamoDB to Redshift Using Hevo Data
Method 2: DynamoDB to Redshift Using Redshift’s COPY Command
Method 3: DynamoDB to Redshift Using AWS Data Pipeline
Method 4: DynamoDB to Redshift Using Dynamo DB Streams
In today’s big data world, companies use various kinds of databases and migrate between them frequently. A common use case that comes up is transferring transactional data from your database to your data warehouse, such as transferring/copying data from DynamoDB to Redshift. In this blog, we provided you with 4 step-by-step methods on how you can integrate your DynamoDB data to Redshift.
Table of Contents
Amazon DynamoDB Overview

Amazon DynamoDB is a serverless NoSQL database service that works on the key-value and document data models. It allows developers to build modern, serverless applications that start small but eventually scale globally. Amazon DynamoDB applies automated horizontal scaling, guaranteeing unlimited scaling capability to support virtually any table size.
Key Features:
- Performance at scale
- Designed for 99.9999% SLA
- Serverless performance with limitless scalability
- On-demand backup and restore
- Private network connectivity
Amazon Redshift Overview
Amazon Redshift is a fully managed cloud data warehouse service for large-scale data analysis. It provides fast query performance and cost-effectiveness, making it perfect for business intelligence and data warehousing.
Key Features:
- Highly Scalable with less downtime.
- Optimized Query Performance because columnar storage and data compression are enabled.
- Flexible pricing options for what you use.
- Automated backups, patching, and updates.
- Encryption at rest and in transit, VPC isolation, and IAM integration.
Automate your DynamoDB to Redshift data pipeline with Hevo’s no-code platform and eliminate the complexity of manual integrations.
- No-Code Setup: Connect DynamoDB and Redshift effortlessly without writing a single line of code.
- Real-Time Sync: Stream changes from DynamoDB to Redshift instantly for up-to-date analytics.
- Built-In Transformations: Clean and enrich data on the fly using pre-built transformations or custom Python scripts.
- Auto-Schema Mapping: Automatically align DynamoDB data with your Redshift schema for smooth ingestion.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration. Try out the 14-day free trial today to experience hassle-free data integration.
Get Started with Hevo for Free
Methods to Copy Data from DynamoDB to Redshift
Method 1: DynamoDB to Redshift Using Hevo Data
Method 2: DynamoDB to Redshift Using Redshift’s COPY Command
Method 3: DynamoDB to Redshift Using AWS Data Pipeline
Method 4: DynamoDB to Redshift Using Dynamo DB Streams
Method 1: DynamoDB to Redshift Using Hevo Data
Here are the 2 simple steps you need to use to move data from DynamoDB to Redshift using Hevo:
- Step 1) Authenticate Source: Connect your DynamoDB account as a source for Hevo by entering a unique name for Hevo Pipeline, AWS Access Key, AWS Secret Key, and AWS Region. This is shown in the image below.

- Step 2) Configure Destination: Configure the Redshift data warehouse as the destination for your Hevo Pipeline. You must provide the warehouse name, database password, database schema, database port, and database username. This is shown in the image below.

Method 2: DynamoDB to Redshift Using Redshift’s COPY Command
This is by far the simplest way to copy a table from DynamoDB stream to Redshift. Redshift’s COPY command can accept a DynamoDB URL as one of the inputs and manage the copying process independently. The syntax for the COPY command is as follows.
copy <target_tablename> from 'dynamodb://<source_table_name>'
authorization
read ratio '<integer>';For now, let’s assume you need to move the “product_details_v1” table from DynamoDB to Redshift (to a particular target table) named “product_details_tgt”. The command to move data will be as follows.
COPY product_details_v1_tgt from dynamodb://product_details_v1
credentials ‘aws_access_key_id = <access_key_id>;aws_secret_access_key=<secret_access_key>
readratio 40;The “readratio” parameter in the above command specifies the amount of provisioned capacity in the DynamoDB instance that can be used for this operation. This operation is usually a performance-intensive one, and it is recommended to keep this value below 50% to avoid the source database getting busy.
Limitations of Using Redshift’s Copy Command to Load Data from DynamoDB to Redshift
The above command may look easy, but in real life, there are multiple problems that a user needs to be careful about while doing this. A list of such critical factors that should be considered is given below.
- DynamoDB and Redshift follow different sets of rules for their table names. While DynamoDB allows for the use of up to 255 characters to form the table name, Redshift limits it to 127 characters. It prohibits the use of many special characters, including dots and dashes. In addition to that, Redshift table names are case-insensitive.
- While copying data from DynamoDB to Redshift, Redshift tries to map between DynamoDB attribute names and Redshift column names. If there is no match for a Redshift column name, it is populated as empty or NULL, depending on the value of the EMPTYASNULL parameter configuration parameter in the COPY command.
- All the attribute names in DynamoDB that cannot be matched to column names in Redshift are discarded.
- At the moment, the COPY command only supports STRING and NUMBER data types in DynamoDB.
- The above method works well when the copying operation is a one-time operation.
Method 3: DynamoDB to Redshift Using AWS Data Pipeline
AWS Data Pipeline is Amazon’s service that executes data migration from one point to another in the AWS Ecosystem. Unfortunately, it does not directly provide us with an option to copy data from DynamoDB to Redshift, but gives us an option to export DynamoDB data to S3. From S3, we must use a COPY command to recreate the table in S3. Follow the steps below to copy data from DynamoDB to Redshift using AWS Data Pipeline:
- Create an AWS Data pipeline from the AWS Management Console and select the option “Export DynamoDB table to S3” in the source option as shown in the image below. A detailed account of how to use the AWS Data Pipeline can be found in the blog post.

- Once the Data Pipeline completes the export, use the COPY command with the source path as the JSON file location. The COPY command is intelligent enough to autoload the table using JSON attributes. The following command can be used to accomplish the same.
COPY product_details_v1_tgt from s3://my_bucket/product_details_v1.json credentials ‘aws_access_key_id = <access_key_id>;aws_secret_access_key=<secret_access_key> Json = ‘auto’In the above command, product_details_v1.json is the output of AWS Data Pipeline execution. Alternately, instead of the “auto” argument, a JSON file can be specified to map the JSON attribute names to Redshift columns, in case those two do not match.

Method 4: DynamoDB to Redshift Using DynamoDB Streams
The following are the steps to migrate Amazon Dynamo to Amazon Redshift using DynamoDB Stream:
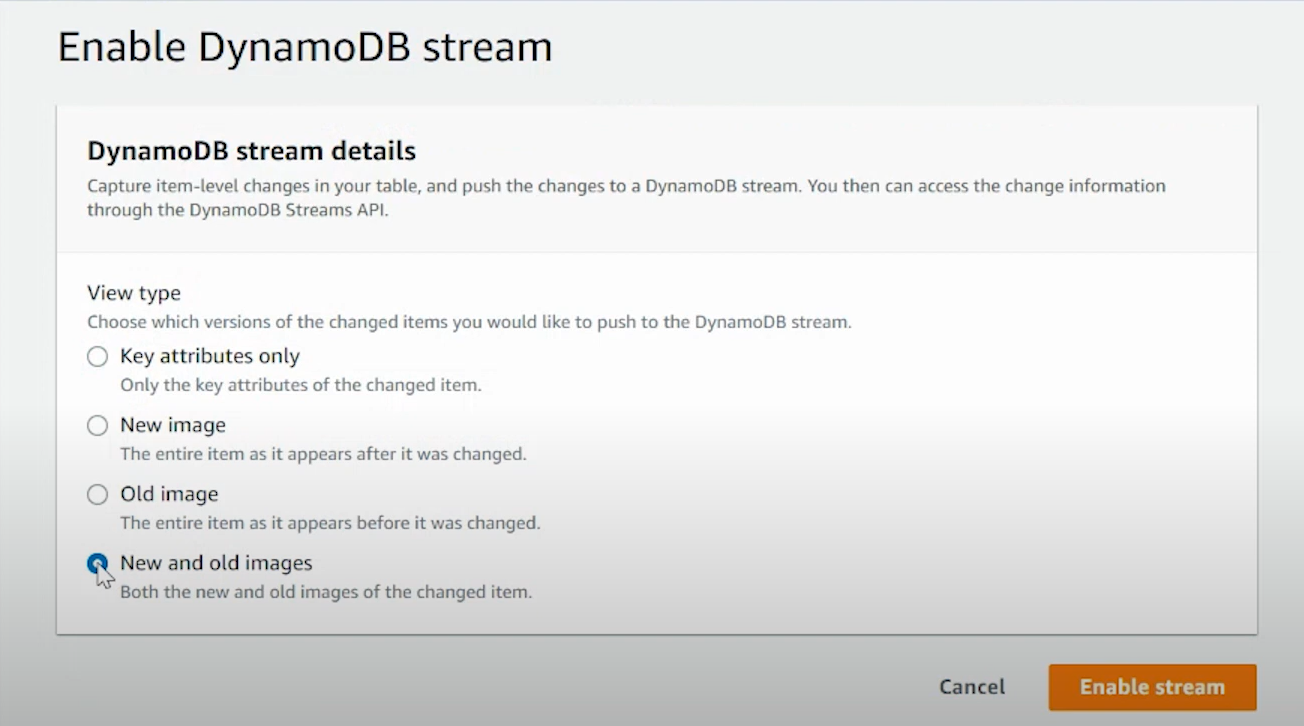
- Go to the DynamoDB console dashboard and turn on DynamoDB Streams for the source table to capture real-time changes
- Create an AWS Lambda function and configure it using the AWS Lambda Service. AWS Lambda can execute code triggered by events and triggers from various AWS services or custom-defined events. It will look something like this:
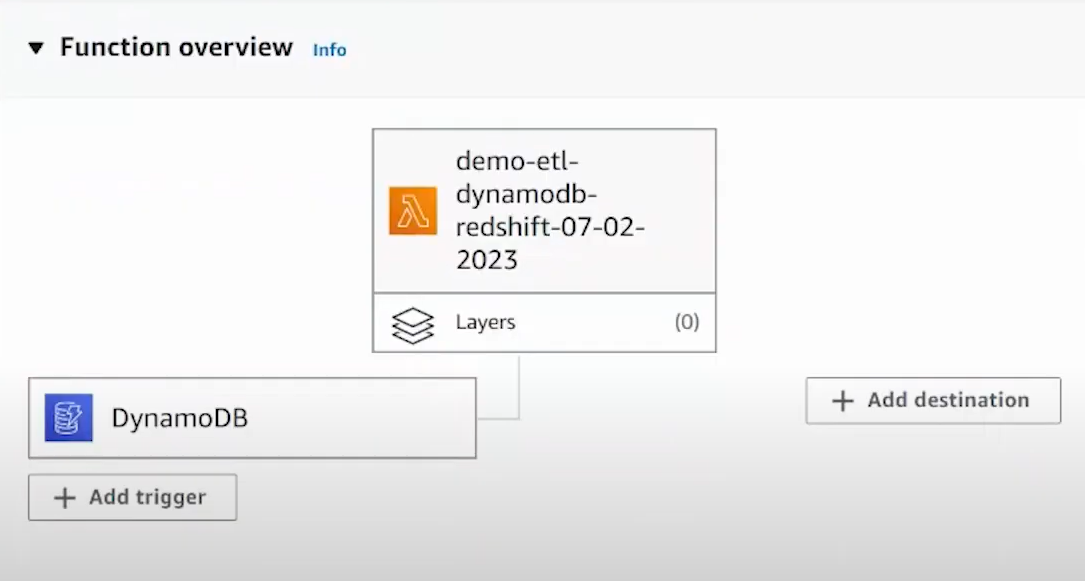
- The Lambda function processes the stream records and transforms data into a form usable in Redshift. This may comprise formatting, enriching data, and other changes.
- Configure an Amazon S3 bucket to store the Lambda function’s results temporarily.
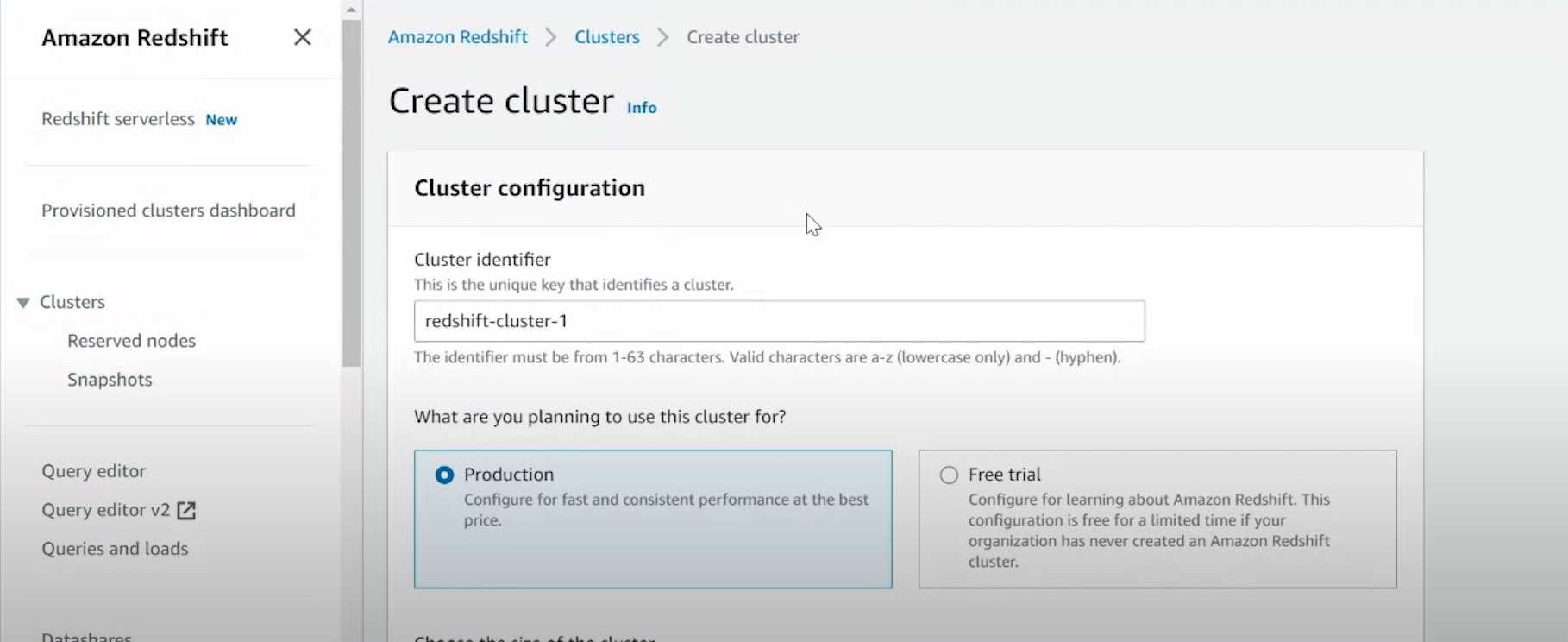
- If you don’t have an Amazon Redshift cluster, create one. Design the table schema to match the transformed data from DynamoDB.
- Create the delivery stream by giving the relevant details.
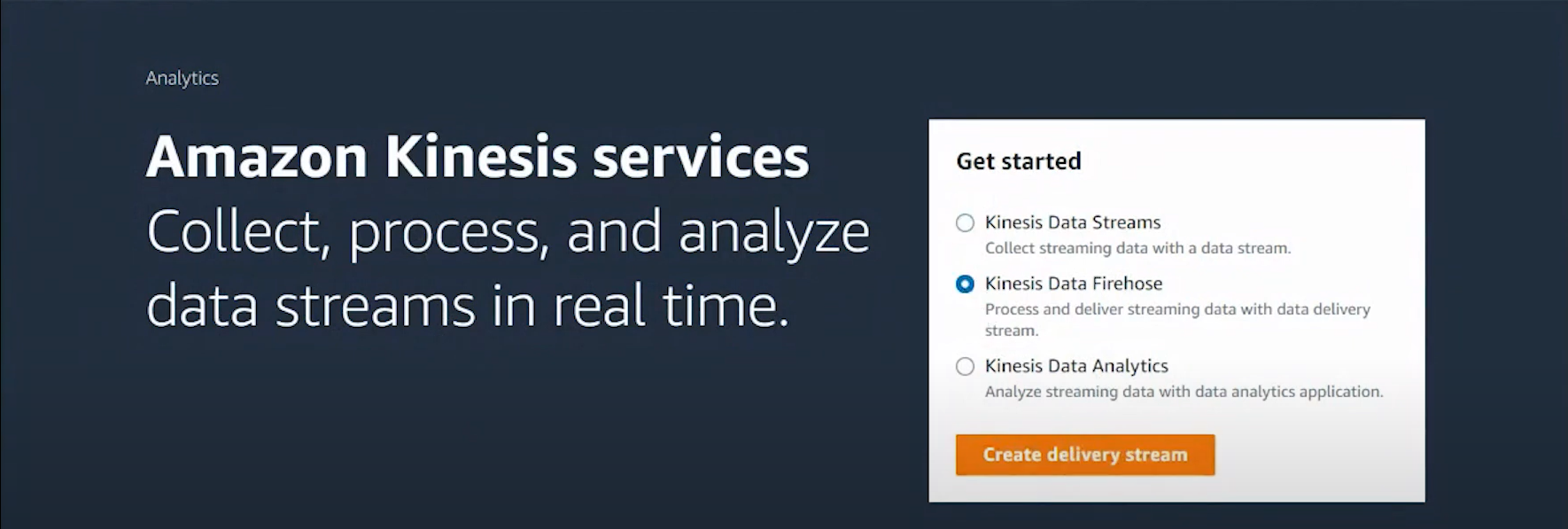
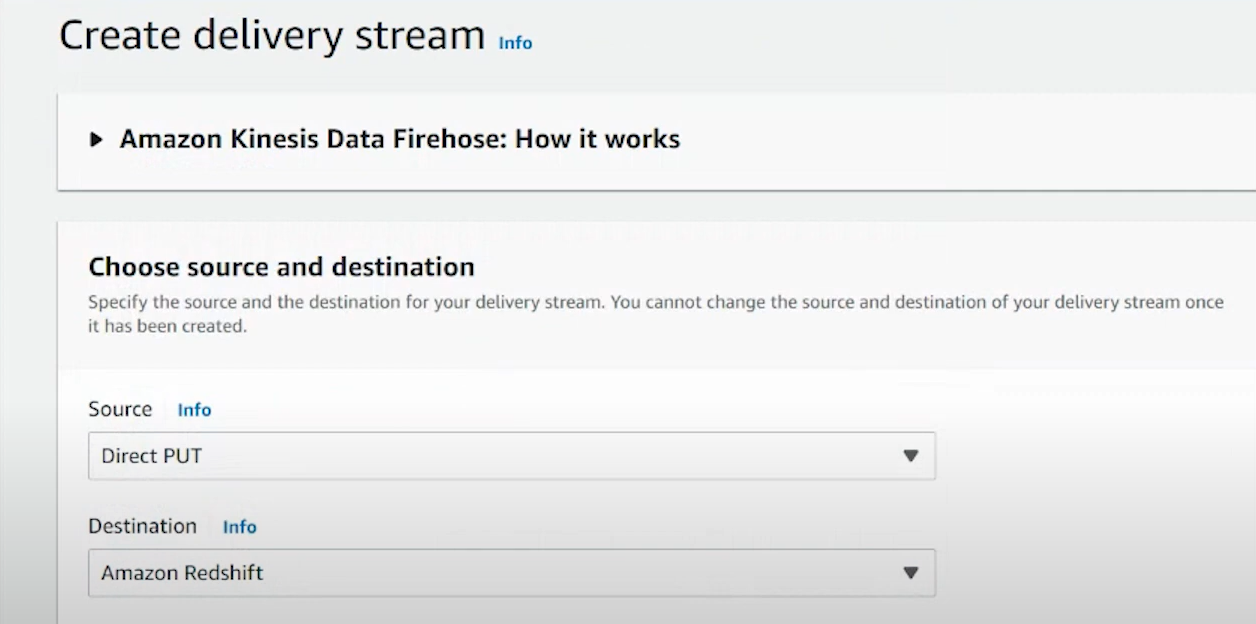
- After you configure the source and destination details and provide relevant details, click on ‘Create Delivery Stream’.
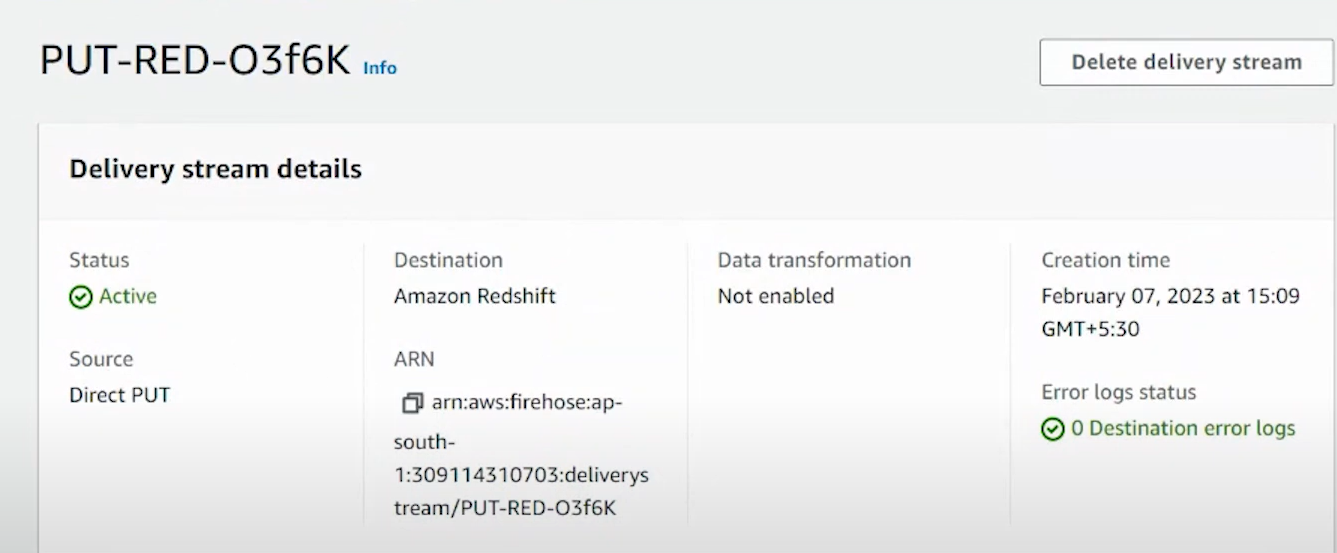
- The data stream is successfully created after the status shows ‘Active’.
Limitations of Using DynamoDB Streams
- The development includes setting up a Lambda function, processing DynamoDB Streams, and transforming data, which could be time-consuming.
- It requires knowledge of coding, error handling, and concepts of event-driven architecture. The development and maintenance of these functions are tricky.
- There can be complexity in the NoSQL data of DynamoDB mapping to the relational database of Redshift.
- Some data types will require additional processing to transform and map; it won’t have a straightforward one-to-one mapping.
Conclusion
In this blog, we have provided you with a step-by-step method of integrating your data from DynamoDB to Amazon Redshift using AWS Data Pipeline. This method involves transferring data from DynamoDB to Amazon S3 and loading it into Redshift using the COPY command. While this approach is effective for batch processing, it requires manual setup, lacks real-time synchronization capabilities, and requires coding knowledge.
For those seeking a more streamlined and automated solution, Hevo offers a no-code platform that simplifies the data migration process. With Hevo, you can set up real-time data pipelines between DynamoDB and Redshift without writing any code, ensuring continuous data synchronization and reducing manual effort.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. You can also have a look at our unbeatable pricing that will help you choose the right plan for your business needs!
Frequently Asked Questions
1. How to transfer data from DynamoDB to Redshift?
You can transfer data from DynamoDB to Redshift using the following methods:
– Using automated platforms like Hevo
– Using Copy command
– Using AWS Data Pipeline
– Using DynamoDB streams
2. What is the difference between Redshift and DynamoDB?
Redshift: A managed data warehouse for complex queries and large datasets, optimized for analytics.
DynamoDB: Managed NoSQL database for fast, scalable key-value and document data storage, optimized for high-velocity applications.
3. How do I transfer data to Redshift?
You can transfer data to Redshift using the following methods:
– Using automated platforms like Hevo
– Using Copy command
– Using AWS Data Pipeline
– Using AWS Glue
4. How to push dynamodb data to Redshift (without involving custom code)?
To push DynamoDB data to Amazon Redshift without involving custom code, you can use Hevo Data, a no-code data integration platform that simplifies the process. Hevo offers seamless integration between DynamoDB and Redshift, allowing you to set up data pipelines in just a few clicks.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Checkout the Hevo pricing to choose the best plan for you.
Share your experience of copying data from DynamoDB to Redshift in the comment section below!
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




