

Are you trying to derive deeper insights by replicating your data to large Data Warehouses like Amazon Redshift? Well, you’ve come to the right place. Now, it has become easier to replicate data to Amazon Redshift.
This article will give you a comprehensive guide to Amazon Redshift Replication. You will also explore 3 methods with their pros and cons to set up your Amazon Redshift Replication. Moreover, you will be able to find the best method for your business based on the requirements. Let’s get started.
Table of Contents
Prerequisites
You will have a much easier time understanding the ways for setting up Amazon Redshift Replication if you have gone through the following aspects:
- An active account on Amazon Web Services.
- Working knowledge of SQL (Structured Query Language).
- Working knowledge of at least one scripting language.
- Working knowledge of Databases and Data Warehouses.
Method 1: Using Amazon Kinesis to Set Up Amazon Redshift Replication
This method involves the use of Amazon Kinesis to replicate the data to Amazon Redshift. This method allows you to run queries concurrently. The disadvantage of this technique is that it may lead to overkill situations if you aren’t handling online transactions and as a result, infrastructure costs might increase.
Method 2: Using Open-Source Kafka to Set Up Amazon Redshift Replication
This method involves the use of Open-Source Kafka to replicate the data to Amazon Redshift. The advantage of using Kafka is that it provides reliability and availability at all times. However, this method involves a lot of programming and configurations to replicate the data.
Method 3: Using Hevo Data to Set Up Amazon Redshift Replication
Hevo Data is an automated Data Pipeline platform that can replicate data to Amazon Redshift very quickly without writing a single line of code. It is simple, hassle-free, and reliable.
Get Started with Hevo for FreeIntroduction to Amazon Redshift Replication

Amazon Redshift is a fully managed, petabyte-scale, cloud-based Data Warehouse service. Amazon Redshift is based on PostgreSQL. Its scalability, interoperability, and fast query performance make it one of the most sought-after Data Warehousing solutions.
Amazon Redshift automatically takes incremental snapshots that track changes to the cluster since the previous automated snapshot. All of the data required to restore a cluster is retained by an automated snapshot.
Users can specify a snapshot schedule to control when automated snapshots are taken, and they can take a manual snapshot at any time. These snapshots can be used to create a new replica cluster and make the new cluster available before all of the data is loaded, so you can begin querying the new cluster immediately.
Amazon Redshift remembers your most-used data and queries, restores them so that the most frequent queries can be serviced as soon as possible. This default backup and replication service are not sufficient in many real-life cases.
There are times when a faster recovery point with full-scale capabilities is required. In these cases, one needs to make exact replicas of Amazon Redshift clusters and keep them in sync.
Methods to Set Up Amazon Redshift Replication
Some custom Redshift replication strategies can be used and fine-tuned to your application needs. Here are 3 methods for Amazon Redshift Replication:
Method 1: Using Amazon Kinesis to Set Up Amazon Redshift Replication
Amazon Kinesis is a fully managed, and scalable platform for processing streaming data on AWS (Amazon Web Services). It enables you to ingest, buffer and process streaming data in real-time.
Amazon Kinesis can be used as an ingestion service at one end, with subscribers at the other end which will retrieve from Amazon Kinesis and process this data. Another hitherto use of Amazon Kinesis is to develop custom streaming applications with specific business logic.
We can use Amazon Kinesis to replicate Amazon Redshift and ensure that multiple Amazon Redshift instances, in different availability zones/geographies, act as replicas and are in sync with each other always.
The proposed architecture will use multiple Amazon Kinesis “Update Subscriber” instances. Amazon Kinesis becomes the ingestion point for all database modifications.
The diagram below illustrates the basic idea of this solution.

As the data is received by Amazon Kinesis, this incoming data will trigger status changes in Amazon Kinesis, then each the “Update Subscriber” instance receives the change notification and reads the latest data slice from Amazon Kinesis.
Then each “Update Subscriber” instance would apply/write this data into its associated Amazon Redshift instance.
The updated subscriber and its associated Amazon Redshift instance reside in the same zone and in an autoscaling group, such that any failed subscriber is replaced with a new one, which would continue from where the previous one left.
An important advantage of this technique is that it can support more concurrent queries than one cluster can provide. Also, with some intelligence, you can serve queries with a cluster that is nearer to their origin.
The downside of this solution is that it could be overkill if you are not processing online transactions, and increase the cost of infrastructure.
Method 2: Using Open-Source Kafka to Set Up Amazon Redshift Replication
Kafka is a stream-processing platform that ingests huge real-time data feeds and publishes them to subscribers.
Kafka can act as a smart middle layer and decouple your diverse, real-time data pipelines. Here, you can collect data from data sources, pre-process them, and feed them to your multiple Amazon Redshift instances.

Kafka is used here as a multi-subscription system. The same published data set can be consumed multiple times, by different consumers which are Amazon Redshift instances.
Kafka’s built-in redundancy offers reliability and availability, at all times. Kafka will ensure that all your Amazon Redshift replicas are in sync and can be used to increase fault tolerance and availability.
The downside here is that you will have to do a lot of configuration and programming to get things right.
Method 3: Using Hevo Data to Set Up Amazon Redshift Replication

You can choose Amazon Redshift as your destination in the pipeline.
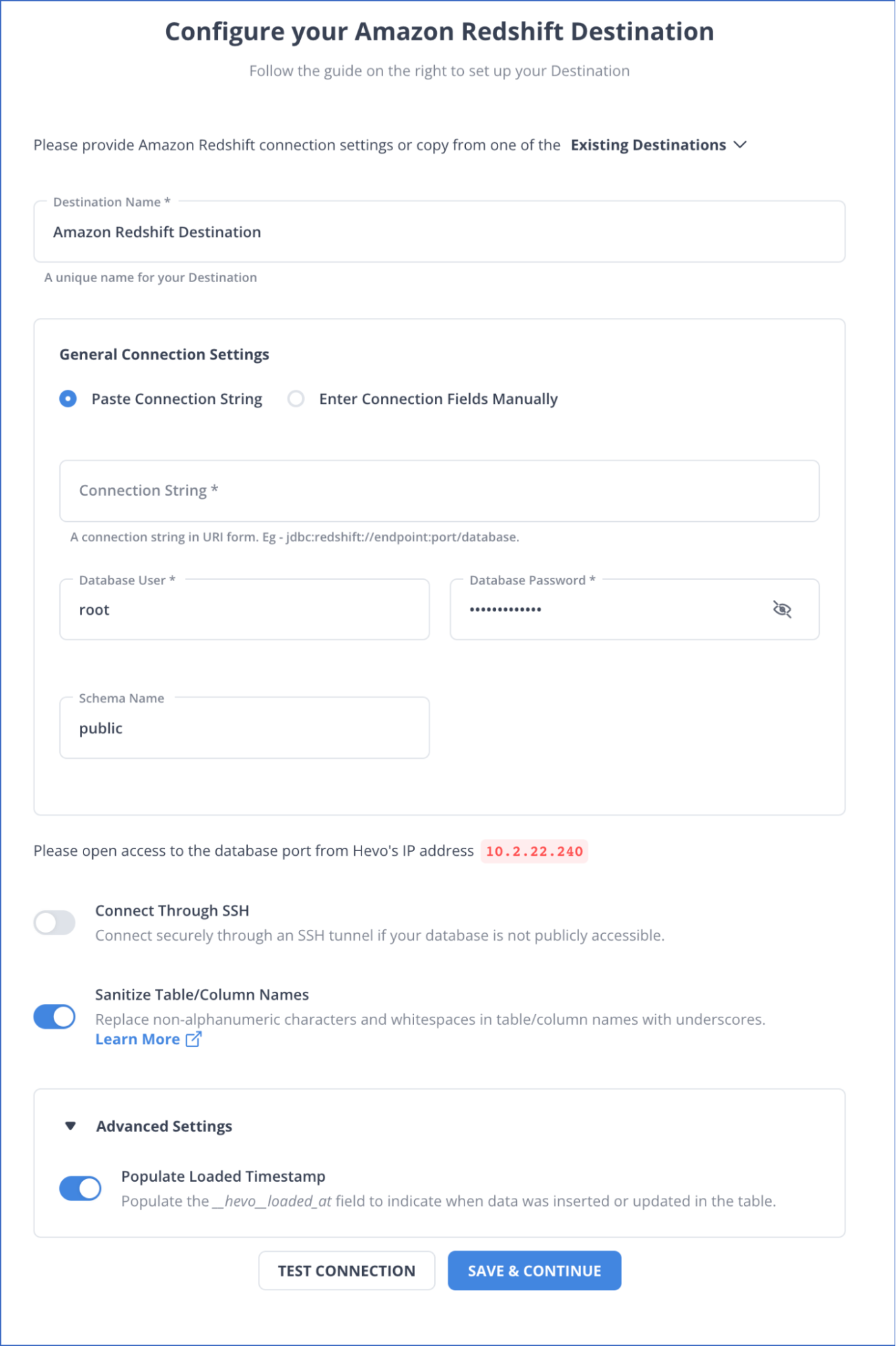
Hevo will take all groundwork of replicating data to Amazon Redshift in a Secure, Consistent, and Reliable fashion. Sign up for a 14-day free trial to try Hevo today.
Reasons to try Hevo
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Minimal Learning: Hevo, with its simple and interactive UI, is extremely simple for new customers to work on and perform operations.
- Hevo Is Built To Scale: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
- Live Monitoring: Hevo allows you to monitor the data flow and check where your data is at a particular point in time.

Conclusion
This article gave an insight into Amazon Redshift Replication.You also got to know various methods for Amazon Redshift Replication. The first method involves the use of Amazon Kinesis and the second method involves the use of Kafka. These two methods require a lot of configurations and manual troubleshooting.
If you want a hassle-free data transfer to Amazon Redshift, you can try the third method. Hevo Data can replicate your data to any Data Warehouse such as Amazon Redshift, Google BigQuery, Snowflake, or a destination of your choice without writing code in just a few minutes.
Try Hevo’s 14-day free trial today.
FAQ on Amazon Redshift Replication
1. Does Redshift support replication?
Yes, Amazon Redshift supports replication for data recovery and high availability through snapshot and automated backup replication.
2. How do I duplicate a database in Redshift?
You can duplicate a database in Redshift by creating a snapshot of the source database and restoring it to a new cluster. You can also use the CREATE TABLE AS or UNLOAD and COPY commands for data duplication.
3. Why use Redshift instead of RDS?
Redshift is optimized for online analytical processing (OLAP) and handling large-scale data warehousing, making it ideal for complex queries and big data analytics. RDS is better for online transaction processing (OLTP) and general-purpose databases.
4. Can we duplicate the schema in Redshift?
Yes, you can duplicate a schema in Redshift using the CREATE SCHEMA command, copy tables with the CREATE TABLE AS command, or use tools like pg_dump and pg_restore.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





