

 KEY TAKEAWAY
KEY TAKEAWAYHevo Data: Helps you set up no-code ELT pipelines that run in real time and scale easily when your workloads grow.
Matillion: Lets engineers build cloud-based pipelines with a simple, low-code, drag-and-drop interface.
AWS Glue: Works well if you’re in AWS and want serverless ETL with automation and flexible job scheduling.
Talend: Used when teams need strong data quality and governance across hybrid or multi-cloud setups.
Informatica IDMC: Suited for enterprise environments that rely on AI-driven automation and large-scale data operations.
Raw data rarely arrives in a neat package. It pours in from CRMs, analytics tools, APIs, and databases like a storm, scattered across formats, riddled with duplicates, missing fields, and inconsistent values. Teams end up spending hours wrangling this mess, stitching together spreadsheets, scripts, and reports just to make it usable.
Modern data transformation platforms step in like a master mechanic, tuning, cleaning, and organizing raw data into structured, ready-to-use tables. They handle schema changes on the fly and eliminate duplicates, letting your team focus on insights instead of babysitting pipelines. With dozens of tools shouting faster setup and smarter automation, choosing the right one can feel like finding a needle in a haystack.
This guide breaks down the top 12 data transformation platforms of 2025, highlighting their strengths, costs, and practical value so you can make decisions with confidence.
Table of Contents
What Are Data Transformation Tools?
Data-transformation tools are the software engines that take raw, mismatched data and reshape it, cleaning, standardizing, and merging records so everything lines up in one consistent format. Whether they run on code, drag-and-drop canvases, or cloud APIs, their job is to turn scattered inputs into tidy, analytics-ready datasets.
You’ll often see them used as part of an ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) workflow. These tools don’t just move data, they prepare it.
Most teams today work with 10 or more data sources. CRMs. Product logs. Excel sheets. Marketing platforms. The problem? These sources don’t match. Column names differ. Timestamp formats vary. And pulling it all together manually just doesn’t scale.
Data transformation tools help by:
- Saving hours of manual cleaning
- Making sure reports use consistent formats and definitions
- Scaling your data workflows without breaking pipelines
They’re essential for teams that want to stop fixing broken scripts and start focusing on insights.
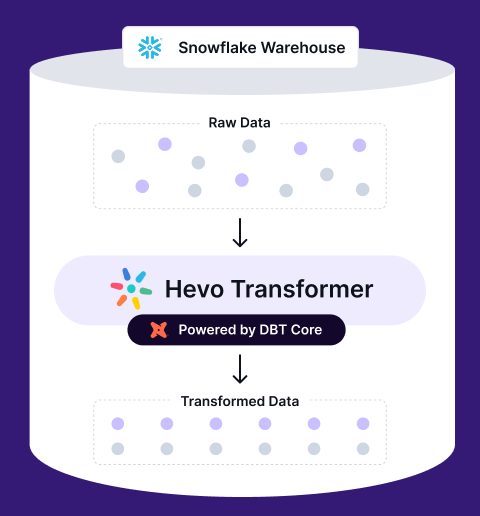
Transform, automate, and optimize your Snowflake data with Hevo Transformer—the ultimate no-code tool for dbt workflows. Experience lightning-fast integrations, real-time previews, and seamless version control with Git. Get results in minutes, not hours.
🚀 Instant Integration – Connect and start transforming in minutes
⚡ Effortless dbt Automation – Build, test, and deploy with a click
🔧 Git Version Control – Collaborate and track changes effortlessly
⏱️ Real-Time Data Previews – See and push updates in an instant
Top 12 Data Transformation Tools
Automated Transformation Tools
- Automated tools help you convert and clean data automatically.
- Handling repetitive tasks without manual effort saves you time.
- These tools ensure your data is accurate and ready for analysis.
- They also allow you to focus on more important tasks while they manage the data transformation.
Invalid or missing JSON data for Tabular Comparison.
1. Hevo Data

Hevo Data is a simple, reliable, and transparent ELT solution that turns raw data into analysis-ready tables without requiring code or engineering overhead. Its no-code pipelines automate end-to-end extraction, loading, and transformation, making it easy for teams to move data at scale without managing scripts or infrastructure.
Hevo’s reliability comes from its fault-tolerant architecture, automatic schema handling, and Smart Assist monitoring, which proactively detects issues before they impact analytics. Its transparent, event-based pricing and On-Demand Credits ensure predictable costs and uninterrupted pipeline runs.
Paired with Multi-Workspace and Multi-Region support and 150+ prebuilt connectors, Hevo stands out as an ideal contender for teams that want fast, trustworthy, and maintenance-free ELT.
Key Features
- Simple to Use: Hevo removes engineering bottlenecks with a no-code Visual Flow Builder that lets you drag, drop, and map data in real time. You can build and test logic gradually using Draft Pipelines, so workflows move to production faster without writing any code.
- Reliable: Hevo delivers accurate data using log-based CDC and automated schema handling that adapts as your sources change. With built-in deduplication and fault-tolerant retries, pipelines stay stable and self-healing even when schemas evolve.
- Transparent: You can stay in control with flexible replication that lets you include or skip tables and fields instantly. Hevo’s real-time dashboards and detailed logs show exactly how data moves, making your warehouse a trusted single source of truth.
- Predictable Pricing: Hevo charges only for records that are successfully loaded, with no surprise costs during backfills or edits. This clear, event-based pricing makes it easy to forecast spend as your data grows.
- Scalable: Built for scale, Hevo processes billions of records across 150+ sources with low latency and high reliability. Advanced transformations and a performance-first design ensure your pipelines stay fast as complexity increases.
Pricing
- Free Plan: Up to 1 million events per month.
- Usage-Based: Pay as you scale beyond the free quota.
- Flexible Scaling: Add workspaces, regions, or event capacity as needed.
Pros
- Friendly for non-engineers
- Setup takes less than an hour
- Fully managed, no-code ELT for fast data availability.
- Smart Assist and On-Demand Credits minimize downtime and keep pipelines reliable.
- Multi-Workspace and Multi-Region enable seamless scaling and organization.
- Embedded Python allows for advanced transformations when needed.
Cons
- Costs can rise at very high data volumes.
- Custom scripting is limited compared to fully developer-focused tools.
Case Study
Postman used Hevo to automate reporting across teams. They brought together data from product, marketing, and support without involving engineers for every pipeline tweak.

2. Matillion

Matillion’s Data Productivity Cloud is a cloud-native integration and transformation platform built for warehouses such as Snowflake, Amazon Redshift, Google BigQuery, and Databricks. Leveraging a push-down ELT architecture, it loads raw data first and then executes the SQL it generates, along with any custom Python code, directly on the warehouse engine.
A low-code drag-and-drop Designer with dozens of pre-built components, optional hand-written SQL or Python, and new AI-assisted transformer nodes allows data engineers and analysts to collaboratively build, orchestrate, and monitor pipelines that convert raw feeds into trusted, analysis-ready models at cloud scale.
Matillion is best suited for data engineers and technically-skilled data analysts who are responsible for building and maintaining structured, reliable data pipelines. It thrives in organizations that have already invested in a cloud data warehouse and need a robust tool to manage the transformation layer.
Key Features
- Pre-built Connectors: Matillion offers a vast library of pre-built connectors for various data sources, simplifying the data ingestion process.
- ELT Capabilities: The platform supports Extract, Load, and Transform (ELT) processes, allowing data transformations to occur within the target data warehouse for improved performance.
- Scalability: Matillion’s architecture is designed to handle large volumes of data, ensuring scalability as data needs grow.
- User-Friendly Interface: With its intuitive drag-and-drop interface, users can design complex data workflows without extensive coding knowledge.
- Real-Time Data Processing: Matillion supports real-time data transformation and loading, ensuring your data is always up-to-date.
Pricing
Matillion offers a consumption-based pricing model, allowing users to pay for the resources they utilise. This flexible approach helps organisations manage costs effectively.
Pros
- Easy to use with a minimal learning curve.
- Strong integration with major cloud platforms.
- Scalable to handle large data volumes.
- Active community and responsive support.
Cons
- Some users have reported challenges with error handling and debugging.
- The platform may require additional customisation for complex transformations.
What People Say

Enterprise Transformation Tools (COTS)
- These tools are powerful software designed for big businesses.
- They must perform extensive data transformations, usually to centralize and store data in a data warehouse.
- These tools require minimal setup and configuration, and they help you to quickly turn raw data into valuable insights without a lot of extra work.
3. AWS Glue

AWS Glue is Amazon’s fully managed, serverless data-integration service that discovers, prepares, and transforms petabyte-scale data entirely inside the AWS cloud; it provisions Apache Spark clusters on demand, executes PySpark or Scala code you author, and then writes clean, analysis-ready results back to Amazon S3, Redshift, or Athena without any infrastructure to manage.
The service revolves around the Glue Data Catalog: crawlers scan sources such as S3, JDBC stores, and streaming feeds to infer schemas and store them as searchable metadata. Recent additions including the drag-and-drop Glue Studio interface and Amazon Q Data Integration, which turns natural-language prompts into runnable Spark jobs.
AWS Glue is best suited for data engineers and developers who are proficient in scripting with PySpark or Scala and are building solutions within the AWS ecosystem. It is an excellent choice for organizations that need to run scalable, event-driven, or scheduled transformation jobs without the overhead of managing servers.
Key Features
- Serverless Autoscaling ETL Engine: Glue automatically spins Spark workers up and down during job execution, so you only pay for the compute you use and never have to manage capacity.
- Central Data Catalog & Crawlers: Built-in crawlers scan S3 buckets and other data stores to infer schemas and populate a unified catalog, ensuring consistent metadata across all jobs.
- Glue Studio Visual Designer: A low-code, drag-and-drop interface generates PySpark or Scala automatically, enabling users to build complex transformations without deep Spark expertise.
- Amazon Q Data Integration Assistant: Describe your intent in plain English and Glue generates ready-to-run Spark code, helping you develop and deploy faster.
- Job Scheduling, Triggers & Monitoring: Native triggers can launch jobs on demand, on a schedule, or in response to upstream events, while CloudWatch provides detailed performance metrics and alerts.
Pricing
- Pay-as-you-go pricing based on usage
- No upfront costs or long-term commitments
Pros
- Fully managed, serverless infrastructure
- Easy integration with other AWS services
- Automated data cataloguing and schema handling
Cons
- Limited flexibility outside of the AWS environment
- Costly if workflows are poorly optimised
- Debugging jobs can be difficult due to abstracted infrastructure
What People Say
4. Talend

Talend, now branded Qlik Talend Data Fabric is a cloud-independent data integration platform that weaves data quality and governance directly into every transformation job. Talend’s primary development environment is a low-code, graphical interface where users design transformation workflows by connecting pre-built components for tasks like data cleansing, enrichment, and complex mapping.
A low-code Studio and browser-based Pipeline Designer let teams ingest, cleanse, map, and enrich data across on-prem, multi-cloud, and hybrid environments, then push native SQL, Spark, or ELT logic down to the target engine for scale.
Enterprises choose Talend when they must prove that every column feeding analytics or AI is profiled, lineage-tracked, and compliant whether the pipeline runs in nightly batch mode or as a real-time stream.
Key Feature
- Low-code Studio & Pipeline Designer: Drag-and-drop components such as joins, filters, Spark, and Python compile into warehouse-native SQL or Spark jobs, reducing pipeline build time for both ETL and ELT.
- Built-in Data Quality & Profiling: Automated rules, standardization, and the Talend Trust Score validate and score every dataset as it flows through the pipeline.
- Central Metadata Catalog & Lineage: A unified catalog indexes assets and captures column-level lineage, enabling auditors to trace any field back to its source.
- Cloud-agnostic & Hybrid Deployment: Run the same pipeline across AWS, Azure, GCP, Databricks, Spark clusters, or on-premises without rewriting code, avoiding vendor lock-in.
- Talend Trust Score: A built-in reliability metric appears alongside every dataset, helping stakeholders assess data readiness at a glance.
Pricing
Talend offers a range of pricing options, including:
- Talend Cloud: Subscription-based pricing tailored to organisational needs.
- Enterprise Edition: Custom pricing based on specific requirements and scale.
Pros
- Comprehensive data integration and quality tools.
- Scalable for large enterprise environments.
- Strong community and support resources.
Cons
- It can be complex for new users or small teams without dedicated data engineering support.
- Cost structure may be unclear due to custom pricing.
- Performance tuning requires expertise, especially for large datasets.
- The interface and UI could be more intuitive for frequent users.
What People Say
5. Informatica

Informatica’s Intelligent Data Management Cloud (IDMC) is an enterprise-grade platform that ingests, standardizes, and reshapes massive data volumes across hybrid and multi-cloud environments, then pushes the work down to warehouse or Spark engines so transformation happens close to the data.
At the core is CLAIRE, an AI engine that studies unified metadata to suggest mappings, tune performance, and automate repetitive tasks, keeping pipelines efficient even at the petabyte scale. A built-in catalog, end-to-end lineage, data-quality profiling, and granular security controls wrap every job in governance, giving large organizations the auditability and policy enforcement they need for regulated, mission-critical workloads.
Informatica is best suited for large enterprises and organizations with mature data practices and stringent security and compliance requirements. Its primary users are typically IT departments, data engineering teams, and data governance specialists who are responsible for building and maintaining mission-critical, high-volume data pipelines.
Key Features
- Low-code Cloud Studio: Drag-and-drop components compile into native SQL, Spark, or ELT code, speeding up pipeline development without compromising performance.
- CLAIRE AI Recommendations: Machine learning–powered suggestions help with field mappings, transformation logic, and resource optimization to accelerate and standardize development.
- Intelligent Data Catalog & Lineage: Automated data discovery, profiling, and column-level lineage allow teams to quickly find data and trace every change for audit and compliance needs.
- Built-in Data Quality & Privacy: Real-time validation rules, data masking, and policy enforcement ensure clean, compliant data throughout the pipeline.
- Hybrid & Multi-cloud Execution: Deploy the same pipeline across AWS, Azure, GCP, on-prem Hadoop, or Spark environments without code changes, avoiding vendor lock-in.
- Role-based Governance & Version Control: Fine-grained access controls and Git integration support secure, collaborative development at scale.
Pricing
- Quote-based pricing for Informatica Intelligent Data Management Cloud
Pros
- Comprehensive platform for large-scale needs
- Strong focus on data governance
- Automation with AI-based insights
Cons
- Expensive for mid-size teams
- Requires time and training to fully utilise
What People Say
Open Source Transformation Tools
- Free and customizable software that you use to transform data.
- They let you modify and improve the tool’s underlying source code to fit your needs.
- With community support, you can find solutions and add new features.
- These tools help you manage data without the cost of commercial software.
6. dbt

dbt (Data Build Tool) is an open-source transformation framework and accompanying cloud platform that focuses exclusively on the “T” in ELT. It enables teams to write modular SQL models that run natively inside modern cloud data warehouses such as Snowflake, BigQuery, Redshift, Databricks, and others.
By treating analytics code like software, dbt introduces version control, automated testing, documentation, and a Directed Acyclic Graph (DAG) to manage dependencies. This enables analytics engineers, data analysts, and data scientists to collaborate more safely and deploy changes with confidence.
Teams choose dbt because it keeps transformations close to the data while layering on advanced capabilities. These include a governed Semantic Layer for consistent metrics, cross-platform dbt Mesh for multi-project governance, and AI-powered tools like Canvas and Explorer. The result is a unified, SQL-first workflow that blends engineering rigor with self-service analytics.
Key Features
- SQL + Jinja Templating: Write reusable, parameterized SELECT statements that dbt compiles into warehouse-specific SQL at runtime.
- Built-in Tests and Documentation: Define tests and documentation in code. dbt runs these tests on every build and automatically generates a searchable documentation site.
- Directed Acyclic Graph (Lineage Views): dbt maps model dependencies into an interactive DAG, helping teams trace data flow and assess impact before deployment.
- Semantic Layer Powered by MetricFlow: Define business metrics centrally and query them consistently across BI tools like Power BI and Looker.
- dbt Mesh for Multi-Project Governance: Coordinate, test, and share models across teams and data platforms while maintaining team autonomy.
- Visual Canvas & Explorer: Use drag-and-drop model building and interactive lineage exploration to lower the barrier for analysts and speed up debugging.
Pricing
- Free open-source version
- Cloud starts at $100 per developer/month
Pros
- Clean, testable transformations
- Encourages best practices
- Supported by a strong community
Cons
- Doesn’t help with data extraction or loading
- Takes time to learn for new users
What People Say
7. Apache NiFi
Apache NiFi is an open-source, flow-based automation platform that lets you design, run, and tweak streaming pipelines in real time. Its drag-and-drop canvas, 400-plus pre-built “Processors,” and live queue controls mean you can enrich, split, route, or filter data while it’s still in motion.
What makes NiFi distinct is its interactive, real-time control; users can inspect data queues between processors and adjust logic on the fly. Furthermore, its built-in data provenance automatically records a detailed history of every piece of data, tracking every transformation and routing decision, which is invaluable for debugging and auditing.
Apache NiFi is best suited for data engineers and operations teams who need to manage and transform high-volume, continuous streams of data. It excels in scenarios like ingesting log data and standardizing it before storage, routing IoT sensor data based on its content, or performing lightweight data cleansing as part of a larger data distribution network.
Key Features
- Visual Flow Canvas & 400+ Processors: Design pipelines visually by wiring together processors like SplitJSON, ExecuteScript, PutKafka, or DetectImageLabels—no coding needed.
- Real-Time Back-Pressure & Queue Inspection: Set thresholds on object count or size, monitor queues in real time, and dynamically throttle or reroute data flow as needed.
- End-to-End Data Provenance & Replay: Track every FlowFile’s journey through the system and replay any step for auditing, debugging, or recovery.
- Python Processors & Jupyter-Style Scripting (v2.0): Embed Python code—including libraries like Pandas or Torch—directly within processors for flexible, script-based transformations.
- Cluster, Stateless & Kubernetes Operator Support: Scale from a single machine to a distributed cluster, or deploy stateless flows as microservices in Kubernetes.
- Enterprise-Grade Security: Ensure secure operations with TLS encryption, fine-grained role-based access control, and integration with OIDC, SAML, LDAP, and flow-level policies.
Pricing
- Core project: Apache Licence 2.0 — free to download and run.
- Commercial options: Cloudera Flow Management (CFM) wraps NiFi with support and cloud billing (contact sales for CCU-based pricing). cloudera.comcloudera.com
Pros
- Intuitive, visual design accelerates build time.
- Live edits, back-pressure, and provenance give ops-grade observability.
- Strong security stack and deployment flexibility (bare metal, VM, K8s, serverless).
Cons
- Memory tuning is essential on very large, bursty streams.
- Heavy analytics often require an external engine (Spark, Flink) or custom script.
- Debugging complex nested Process Groups can be daunting for newcomers.
What People Say
8. Airbyte

Airbyte is an open-source data integration platform built to automate the movement of data between systems. It is best known for its extensive library of pre-built connectors that simplify extracting data from hundreds of sources and loading it into destinations like data warehouses and databases.
Its standout feature is its open-source, connector-centric architecture. While it offers a vast catalog of pre-built connectors, anyone can build new ones using its Connector Development Kit (CDK) or even a no-code builder.
Airbyte is designed for teams that need to reliably replicate data from various sources like APIs, databases, and SaaS applications into a centralized repository.
Key Features
- Large Library of Open-Source Connectors: A marketplace of over 600 pre-built, community-maintained connectors allows you to ingest data from SaaS applications, databases, files, and event streams without writing custom integration code.
- Seamless Integration with dbt: Built-in hooks can trigger dbt Core or dbt Cloud runs immediately after a sync completes, enabling a fully automated flow from raw data ingestion to transformation.
- Cloud and Self-Hosted Deployment Options: Choose between the fully managed Airbyte Cloud or deploy the open-source version on your own Kubernetes cluster, virtual machine, or local environment for complete control and data sovereignty.
- Self-Service Debugging and Connector Modification: The Python-based Connector Development Kit, detailed logging, and one-click reset tools empower engineers to build, test, and modify connectors without relying on vendor updates.
- Automated Schema Drift Detection and Handling: Airbyte checks for schema changes before each sync, alerts on added or removed columns, and guides users through updating mappings to keep data pipelines stable and reliable.
Pricing
- The open-source version is free to self-host
- Airbyte Cloud uses a credit-based, pay-as-you-go model. Pricing scales with the volume of data synchronized, with one credit ($2.50) covering approximately 250 MB of database data or ~167,000 API rows.
Pros
- Vast and growing library of connectors saves significant development time
- Open-source model allows for customization and avoids vendor lock-in
- Strong integration with dbt for handling the “T” in ELT
- Simple, usage-based pricing for the cloud version
Cons
- Does not perform data transformation natively; requires a separate tool
- Self-hosting requires infrastructure management and maintenance
- Connector quality and maturity can vary, especially for less common sources
- Can be resource-intensive when running many concurrent syncs
What People Say
Custom Transformation Solutions
- You can build these solutions from scratch for your business’s specific use cases.
- Lets you work with developers to create tools that perfectly fit your data processes.
- These solutions offer flexibility and precise functionality, effectively helping you handle unique data challenges.
9. Python

Python is a general-purpose, high-level language whose clean syntax and enormous package ecosystem turn it into the Swiss-army knife of data work. Libraries such as pandas, Polars, PyArrow, Dask, scikit-learn, and PySpark let you code transforms that GUI ETL tools struggle withoutlier imputation, fuzzy matching, ML-driven feature engineering, you name it.
The 2025 releases of Python 3.13 (experimental no-GIL build and a brand-new colour REPL) and pandas 3.0 (Arrow-backed columns, copy-on-write by default) push performance forward without changing the language’s gentle learning curve.
That blend of flexibility and power makes Python the go-to for data scientists, analytics engineers, and platform teams who need full control over complex, evolving pipelines.
Key Features
- Rich Library Ecosystem: Access powerful tools like pandas for tabular wrangling, NumPy for vector math, scikit-learn for machine learning, PyArrow for zero-copy columnar data, and Polars for blazing-fast, Rust-backed DataFrames, plus 400K+ packages on PyPI.
- DataFrame Semantics: Use pandas and Polars DataFrame APIs to chain filters, joins, and window operations in clear, readable one-liners. With pandas 3.0, Arrow memory sharing brings significant performance gains.
- First-Class Cloud & Database Hooks: Integrate seamlessly with SQLAlchemy, DuckDB, psycopg, boto3, and cloud SDKs for GCP and Azure, enabling in-place transformations and cross-cloud orchestration from a single script.
- Unbounded Extensibility: Write custom UDFs for Spark, Snowflake, BigQuery, and Postgres. Embed high-performance C, C++, or Rust code using Cython or PyO3 when native speed is critical.
Pricing
- Language & libraries: Completely free and open source.
- Runtime costs: Only the compute you execute on local CPU/GPU, on-prem clusters, or cloud instances (e.g., AWS EC2, Azure Batch, GCP Cloud Run).
Pros
- Unlimited flexibility for bespoke logic and niche file formats.
- Vast ecosystem spanning ETL, ML, viz, APIs, orchestration.
- Huge talent pool; easy to hire and ramp up.
- Works everywhere from Jupyter notebooks to Airflow DAGs to Lambda functions.
- Massive community and learning resources
Cons
- Steeper learning curve than drag-and-drop tools; must write code.
- Single-machine pandas workloads can hit RAM ceilings; you may need Polars, DuckDB, Dask, or Spark for big data.
- No native visual pipeline monitor, you rely on notebooks, logs, or an orchestrator (Airflow, Dagster, Prefect).
- Dependency management (virtualenvs, Conda, poetry) can trip up large teams if not standardised.
10. PostgreSQL

PostgreSQL (or simply Postgres) is a free, community-driven object-relational database that’s famous for rock-solid ACID compliance and an ever-growing SQL feature set.
What makes it stand out for data transformation is that almost every modern analytic construct window functions, common-table expressions (CTEs), SQL/JSON, partition pruning, parallel query, logical replication runs inside the engine, so you can clean, join, aggregate, and reshape data without shipping it anywhere.
This “transform-in-place” model is perfect for engineers, analysts, and backend developers who already store raw data in Postgres and want ELT workflows that stay close to the source.
Key Features
- Advanced SQL: CTEs & Window Functions: Build multi-step pipelines like ranking, rolling sums, and sessionization in a single readable query, eliminating the need for temp tables or procedural code.
- User-Defined Functions: Write custom logic in PL/pgSQL, Python, JavaScript, or Rust. Reuse functions across queries and keep transformations version-controlled within the database.
- Logical Replication & Zero-Downtime Failover: Stream changed rows to other Postgres clusters or downstream systems while keeping jobs online during upgrades. Version 17 introduces slot failover and pg_createsubscriber.
- Partitioning & Parallel Query Execution: Break massive tables into partitions (by time or key) and scan them in parallel, enabling fast roll-ups even on billions of rows.
- Granular Security & Full ACID Compliance: Enforce row-level access, encrypt connections, use transactional DDL, and ensure data consistency even if an ETL job crashes mid-run with replayable WAL.
Pricing
- Core engine: 100 % open source, no licence fees.
- Managed options: Pay-as-you-go on major clouds.
- Enterprise support: Available from vendors such as EDB, Crunchy, and Azure Database for PostgreSQL (custom quotes).
Pros
- Transformations run where the data lives, eliminating network hops.
- Declarative SQL keeps complex logic concise and self-documenting.
- Mature optimiser handles terabyte-scale joins and aggregations efficiently.
- Huge ecosystem of extensions (Timescale, Citus, PostGIS) for specialised workloads.
Cons
- Requires solid SQL skills.
- Long, CPU-heavy transforms can starve OLTP traffic unless workloads are isolated.
- Limited for tasks that need external API calls or heavy procedural branching.
- Version-controlling SQL scripts and database objects takes more discipline than with code-centric ETL frameworks.
11. Qlik Compose

Qlik Compose leads with automated ETL generation, turning complex data warehouse builds into a few clicks. It removes the grind of hand-coded ETL scripts and gets your data warehouse analytics-ready faster than traditional setups. Its model-driven warehousing helps teams design scalable data architectures from logical models that evolve with business needs.
Whether you’re setting up a Data Vault or generating analytical marts, Qlik Compose adjusts seamlessly. Paired with Qlik Replicate, it delivers real-time updates with CDC, so your dashboards never lag behind reality. The visual transformation designer is a game changer for teams who want flexibility without complexity.
You can design transformations visually or use SQL for deeper logic, manage datasets, profile data quality, and even track lineage to see how every field evolves. With push-down SQL execution and automated DTAP deployment, Qlik Compose keeps your transformations fast, governed, and production-ready.
- Data Mart Automation: Automatically generates transactional, aggregated, and state-based marts with built-in star schemas.
- Materialized Data Options: Define how data is stored using tables or views for optimized access and performance.
- Data Lineage and Impact Analysis: Understand how changes ripple across datasets with complete traceability.
- Data Profiling and Quality Enforcement: Detect inconsistencies and enforce quality standards during transformation.
- Automated DTAP Capabilities: Move effortlessly across dev, test, acceptance, and production environments.
Pricing
- Starter: $200/month for 10 users and 25 GB of data.
- Standard: $825/month for 25 GB of data (expandable).
- Premium: $2,750/month for 50 GB of data, with advanced AI and predictive analytics.
- Enterprise: Custom quote; starts at 250 GB of data with large-scale flexibility.
- Model: Subscription and capacity-based pricing with scalable add-ons.
Pros
- Simplifies complex data transformations with automation.
- Supports real-time data sync through CDC integration.
- Works efficiently with major cloud data warehouses.
Cons
- Best suited for mature data environments.
- Requires upfront modeling setup for maximum benefit.
12. IBM InfoSphere DataStage

IBM InfoSphere DataStage stands out for its parallel processing engine that powers through massive data volumes with ease. It’s built for enterprises that can’t afford latency, offering a fine balance between speed, accuracy, and flexibility. What makes it special is its Transformer Stage, which lets you apply complex business logic, perform data type conversions, or design custom transformations without heavy coding.
If you’re a visual thinker, the graphical job design makes integration intuitive. You can drag, connect, and shape transformations visually, while the Balanced Optimization feature quietly enhances job performance behind the scenes. For teams working across business and IT, its FastTrack integration bridges that gap by turning business rules into ready-to-run transformation jobs.
Paired with robust metadata management and ELT flexibility, DataStage ensures every change remains traceable and enterprise-grade.
Key Features
- Transformer Stage: Apply complex logic, perform conversions, and design transformations through a flexible expression editor.
- Parallel Processing Engine: Process huge datasets at high speed while maintaining scalability.
- Balanced Optimization: Automatically optimize job performance without modifying job logic.
- Graphical Job Design: Build integration pipelines visually with an intuitive interface.
- InfoSphere FastTrack Integration: Convert business specifications into prebuilt transformation jobs for faster delivery.
Pricing
- DataStage as a Service: Starts at $1.75 per CUH, with free Lite and bundled enterprise plans offering discounted rates.
- Cloud Pak for Data: Annual subscription or marketplace pricing, around $199K/year for 6 VPCs on AWS.
- Enterprise (On-premises): Subscription-based, priced by Processor Value Units (PVU) and support terms.
- Model: Flexible pay-as-you-go or bundled pricing based on usage and deployment.
Pros
- Excellent for large-scale enterprise data workloads.
- Strong visual design tools and automated optimization.
- Integrates deeply with IBM’s broader InfoSphere ecosystem.
Cons
- Requires experienced teams for advanced optimization.
- Setup and licensing can be complex.
How Do You Choose the Right Data Transformation Tool?
1. Integration Capabilities
Ensure the tool seamlessly integrates with your existing data sources, destinations, and infrastructure. Compatibility with various databases, cloud services, and APIs is essential for smooth data flow.
2. Scalability and Performance
Assess whether the tool can handle your current data volume and scale as your data grows. Performance metrics, such as processing speed and resource utilisation, are crucial for large datasets.
3. User Interface and Usability
A user-friendly interface can significantly reduce the learning curve. Tools offering visual workflows or drag-and-drop features can be beneficial for teams with limited coding expertise.
4. Data Quality and Validation Features
Robust data validation, cleansing, and profiling features help maintain data integrity and reliability throughout the transformation process.
5. Security and Compliance
Ensure the tool adheres to security standards and compliance regulations relevant to your industry, such as GDPR or HIPAA. Features like data encryption and access controls are vital.
6. Cost and Licensing
Evaluate the total cost of ownership, including licensing fees, maintenance, and potential scalability costs. Open-source tools may offer cost advantages, but consider the support and community activity.
Check out our blog on data transformation best practices to learn how to standardize and optimize your data for seamless integration and analysis.
How Do Data Transformation Tools Work?
Data transformation tools typically follow a structured process to convert raw data into a usable format:
1. Data Extraction
The tool connects to various data sources (databases, APIs, flat files) to retrieve raw data for processing.
2. Data Profiling and Discovery
Analysing the data to understand its structure, quality, and content. This step helps in identifying anomalies, missing values, and data types.
3. Data Mapping
Defining how data fields from the source correspond to those in the destination. This involves setting transformation rules and relationships between datasets.
4. Data Transformation
Applying various operations such as filtering, aggregating, joining, and converting data types to meet the desired format and structure.
5. Data Validation and Quality Checks
Implementing rules to ensure data accuracy and consistency. This may include checking for duplicates, validating data ranges, and ensuring referential integrity.
6. Data Loading
The transformed data is then loaded into the target system, such as a data warehouse, for further analysis or reporting.
7. Monitoring and Logging
Continuous monitoring of the transformation process to detect errors, performance issues, and to maintain logs for auditing purposes.
Conclusion
If you’ve ever opened a raw dataset and felt a little overwhelmed, that’s exactly where transformation tools come in. They turn all that chaos into clean, structured tables your team can actually work with. And depending on your setup and skill levels, the “right” tool will look different.
Some teams love the simplicity of no-code tools like Hevo because real-time updates come without extra engineering effort. Others stick to Python, dbt, or enterprise platforms like Qlik Compose or IBM DataStage when things get heavier or more regulated.
In the end, picking the right tool doesn’t just make your data cleaner. It makes your entire business faster.
FAQs
What is data lineage, and why does it matter?
Data lineage is the fine-grained record of every hop, join, cast, and filter a dataset undergoes, from its raw origin all the way to the metric a stakeholder sees. With column-level lineage you can pinpoint exactly where a broken figure or PII leak entered the pipeline, satisfy regulatory audits that require proof of data handling, and accelerate impact analysis before deploying model changes reducing both compliance risk and downtime.
Can DevOps improve data transformation?
Applying DevOps principles means treating pipeline code like any other software artifact: you store SQL or Spark scripts in Git, run unit and data-quality tests in CI, and promote builds with automated approvals. This tight feedback loop catches schema drift and logic errors before they hit production, thus improving data transformation.
How do AI and ML help with data transformation?
Machine-learning models can profile incoming datasets to suggest type casts, fuzzy-match dimensions, and flag outliers far faster than manual rules. More advanced systems learn mapping patterns across pipelines, auto-generate transformation code or SQL, and continuously retrain on ground-truth corrections reducing the tedium of data wrangling while absorbing domain knowledge at scale.
What’s the biggest challenge with legacy data systems?
Older platforms lock data into proprietary formats and overnight batch windows, with business logic hard-coded in COBOL or stored procedures that few engineers still understand. Their rigidity makes real-time CDC, schema evolution, and cloud-native analytics nearly impossible, forcing teams to adopt stop-gap layers such as replication gateways or staged dual-writes until a full re-platform can be executed.
How Do Data Transformation Tools Work?
Data transformation tools extract raw data from sources, profile and map it, apply transformations like filtering and aggregation, validate quality, load it into target systems, and continuously monitor the process to ensure accuracy, consistency, and reliable analytics.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





