

Unlock the full potential of your Adroll data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
As a data engineer, you hold all the cards to make data easily accessible to your business teams. Your team just requested an Adroll to BigQuery connection on priority. We know you don’t wanna keep your data scientists and business analysts waiting to get critical business insights. As the most direct approach, you can leverage Adroll APIs. Or, hunt for a no-code tool that fully automates & manages data integration for you while you focus on your core objectives.
Well, look no further. With this article, get a step-by-step guide to connecting Adroll to BigQuery effectively and quickly, delivering data to your marketing team.
Method 1: Use Hevo to Load Data from Adroll to BigQuery
With Hevo, you can move data from Adroll to BigQuery without writing any code. It also keeps your data synced in real time, saving you the hassle of doing it manually.
Method 2: Manually Load Data from Adroll to BigQuery Using the Adroll API
This method requires coding skills and experience with APIs. You’ll need to create scripts, pull data in JSON format, and manage the entire process manually. It can take a lot of time and effort to get everything set up and keep it running smoothly.
Get Started with Hevo for FreeTable of Contents
Method 1: Automate the Data Replication process using Hevo
Prerequisites:
- Configure Adroll as a Source: Authenticate and set up Adroll for data extraction.
- Configure BigQuery as a Destination: Set up BigQuery for data replication.
- Complete Data Pipeline Setup: Hevo starts syncing the data in minutes.
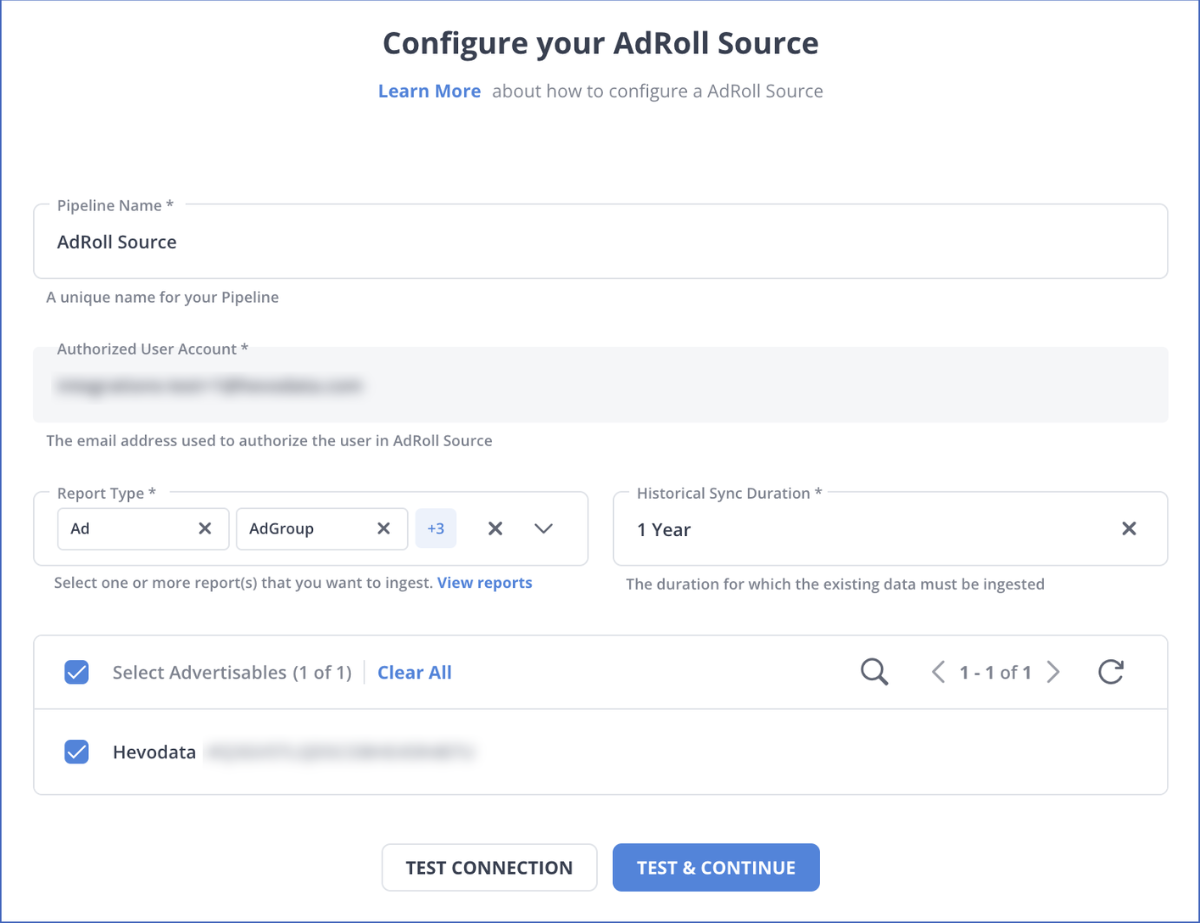
Step 1: Configure Adroll as a Source
Authenticate and configure your Adroll Source.
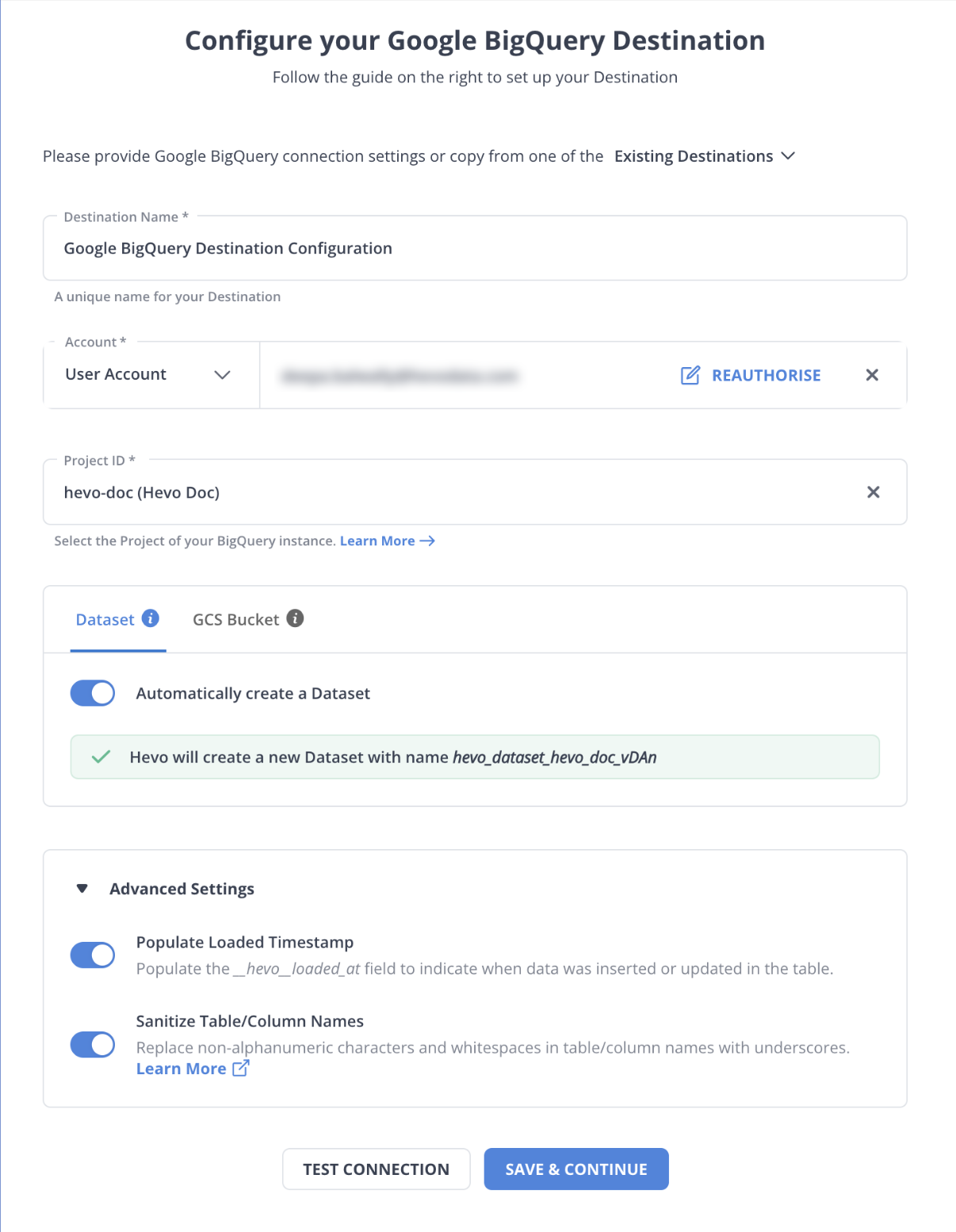
Step 2: Configure BigQuery as a Destination
In the next step, we will configure BigQuery as the destination.
Once your Adroll to BigQuery ETL Pipeline is configured, Hevo will collect new and updated data from Adroll every five minutes (the default pipeline frequency) and duplicate it into BigQuery. Depending on your needs, you can adjust the pipeline frequency from 5 minutes to an hour.
Data Replication Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 1 Hr | 15 Mins | 24 Hrs | 1-24 |
In a matter of minutes, you can complete this no-code & automated approach of connecting Adroll to BigQuery using Hevo Data and start analyzing your data.
Why consider Hevo
- Fully Managed: You don’t need to dedicate time to building your pipelines. With Hevo Data’s dashboard, you can monitor all the processes in your pipeline, thus giving you complete control over it.
- Data Transformation: Hevo Data provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Faster Insight Generation: Hevo Data offers near real-time data replication, so you have access to real-time insight generation and faster decision-making.
- Schema Management: With Hevo Data’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increase in the number of sources and volume of data, Hevo Data can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Transparent pricing: You can select your pricing plan based on your requirements. Different plans are clearly put together on its website, along with all the features it supports. You can adjust your credit limits and receive notifications for any increased data flow.
- Live Support: The support team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Method 2: Replicate Data from Adroll to BigQuery Using APIs
Prerequisites
- Adroll Account and API Access: Access to Adroll account with API access and obtain your API key and authentication token.
- BigQuery Access: Access to a Google Cloud project with permissions to create and manage BigQuery tables.
- Command Line Tool: A tool like Curl or Postman to send API requests and retrieve JSON data from Adroll.
- Basic JSON Knowledge: Understanding of JSON format and schema definition for configuring BigQuery tables.
To start replicating data from Adroll to BigQuery, you need to use one of the Adroll APIs, depending on your needs. In the following example, you can use the Audience API:
Step 1: Retrieve and Store Adroll Data as JSON
Data in Adroll can be exported as JSON data with the help of API keys. Use the Audience API provided by Adroll to retrieve data by running the following curl command:
curl -H 'Authorization: Token YOUR_TOKEN' \
"https://services.adroll.com/audience/v1/target_accounts?apikey=MYAPIKEY&advertisable=MY_ADVERTISABLE_EID"
- curl: A command-line tool for making HTTP requests.
- -H ‘Authorization: Token YOUR_TOKEN’: Adds a header for authorization, where
YOUR_TOKENis your authentication token. - URL:
"https://services.adroll.com/audience/v1/target_accounts?apikey=MYAPIKEY&advertisable=MY_ADVERTISABLE_EID"– The API endpoint for fetching target accounts, with:apikey=MYAPIKEY: Your API key.advertisable=MY_ADVERTISABLE_EID: The ID of your advertisable entity.
You will retrieve the following JSON response after hitting the endpoint in curl:
{
"results": [
{
"advertisable_eid": "MY_ADVERTISABLE_EID",
"eid": "TARGET_ACCOUNT_LIST_EID",
"items_count": 10000,
"name": "Top 10K",
"scoring_at": "2019-07-01T16:34:27.448382+00:00",
"scoring_auc": 0.99100798368454,
"scoring_by_user_eid": "USER_EID",
"scoring_filename": "top-1k-domains.csv",
"scoring_grades": {
"A": {
"threshold": 30,
"items_count": 468,
"min_item": {
"domain": "theglobeandmail.com",
"score": 0.999897
}
},
"C": {
"threshold": 85,
"items_count": 365,
"min_item": {
"domain": "reshet.tv",
"score": 0.939022
}
},
"B": {
"threshold": 80,
"items_count": 2057,
"min_item": {
"domain": "makeagif.com",
"score": 0.973098
}
},
"D": {
"threshold": 95,
"items_count": 2696,
"min_item": {
"domain": "profiles.google.com",
"score": 0.029493
}
},
"F": {
"threshold": 100,
"items_count": 2562,
"min_item": null
},
"unscored_count": 1852,
"scored_count": 8148
},
"scoring_holdout1_model_id": null,
"scoring_holdout1_retries": 0,
"scoring_holdout1_status": null,
"scoring_holdout2_model_id": null,
"scoring_holdout2_retries": 0,
"scoring_holdout2_status": null,
"scoring_holdout3_model_id": null,
"scoring_holdout3_retries": 0,
"scoring_holdout3_status": null,
"scoring_holdout4_model_id": null,
"scoring_holdout4_retries": 0,
"scoring_holdout4_status": null,
"scoring_holdout5_model_id": null,
"scoring_holdout5_retries": 0,
"scoring_holdout5_status": null,
"scoring_items_count": 862,
"scoring_items_pending": true,
"scoring_model_id": "f3f3e5cd-d606-4033-93cd-10c1af2cc232",
"scoring_production_model_id": null,
"scoring_production_retries": 0,
"scoring_production_status": null,
"scoring_status": "complete",
"sfdc_company_list_name": null,
"sfdc_company_list_object_id": null,
"sfdc_create_accounts": false,
"sfdc_initial_pull_pending": null,
"sfdc_scoring_company_list_name": null,
"sfdc_scoring_company_list_object_id": null,
"sfdc_sync_state": "none",
"sfdc_synced_at": null,
"sfdc_train_pending": null,
"suggestions_count": 2955,
"tiers": [
{
"eid": "all",
"items_count": 10000,
"tal_eid": "TARGET_ACCOUNT_LIST_EID"
},
{
"items_count": 9998,
"eid": "untiered",
"name": null,
"tal_eid": "TARGET_ACCOUNT_LIST_EID"
},
{
"items_count": 2,
"eid": "TARGET_ACCOUNT_GROUP_EID",
"name": "UCLA",
"tal_eid": "TARGET_ACCOUNT_LIST_EID"
}
],
"updated_at": "2019-09-16T13:28:43.678412+00:00",
"updated_by_user_eid": null
}
]
}
You need to store the response as a JSON file.
Step 2: Import and Configure JSON Data in BigQuery
- First, click the “Create Table” option and then click “Create Table from” on BigQuery’s web console.
- Then, specify JSON as your source type, give your table a name, and choose a database.
- To specify schematics, provide a sample JSON schema or select “auto-detect” in the schema specifications.
- Adjust advanced settings like multiple API, the field delimiter, skip header rows, the amount of permissible errors, jagged rows, and other variables.

With the table first, you may now retrieve your JSON, choose the table’s schema, build the table (by using the commands) and add data in JSON format to it.
This process is a great way to replicate data from Adroll to BigQuery effectively. It is optimal for the following scenarios:
- APIs can be programmed as customized scripts that can be deployed with detailed instructions on completing each workflow stage.
- Data workflows can be automated with APIs, like Audience APIs, in this scenario. These scripts can be reused by anyone for repetitive processes.
Using the Adroll APIs might be cumbersome and not a wise choice in the following scenarios,:
- Using this method requires you to make API calls and code custom workflows. Hence it requires strong technical knowledge.
- Updating the existing API calls and managing workflows requires immense engineering bandwidth and hence can be a pain point for many users. Maintaining APIs is costly in terms of development, support, and updating.
When the frequency of replicating data from Adroll increases, this process becomes highly monotonous. It adds to your misery when you have to transform the raw data every single time. With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors. Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?
How about you focus on more productive tasks than repeatedly writing custom ETL scripts? This sounds good, right?

What Can You Achieve by Migrating Your Data from Adroll to BigQuery?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Adroll to BigQuery. Does your use case make the list?
- Know your customer: Get a unified view of your customer journey by combing data from all your channels and user touchpoints. Easily visualize each stage of your marketing & sales funnel and quickly derive actionable insights.
- Supercharge your ROAS: Find your high ROAS creatives on which you should be spending more money, thereby boosting your conversions. Identify the different creatives and copy that work best for your customer segment.
- Analyze Customer LTV: Get a competitive edge with near-real-time data from all your marketing channels and understand how different targeting, creatives, or products impact your customer LTV.
Learn more about AdRoll Shopify Integration
Summing It Up
If your team only needs Adroll data occasionally, using Adroll APIs works fine. But as data needs grow, a custom ETL solution becomes necessary. Hevo Data’s 150+ plug-and-play integrations can save your engineers time by automating tasks that are repetitive in nature.
Hevo also makes data cleaning and transformation easy, with pre-load options that take minutes. You can use a simple drag-and-drop interface or your own Python scripts.
Give Hevo a try with a 14-day free trial, and check the pricing to find the right plan for your business. Let us know how it goes with replicating Adroll to BigQuery in the comments!
FAQs
1. How do I migrate from Cloud SQL to BigQuery?
In Hevo, select Cloud SQL as your source and BigQuery as the destination. Hevo will take care of moving your data over.
2. How do I get Google Ads data into BigQuery?
Hevo has a Google Ads integration. Just connect it as the source and BigQuery as the destination, and Hevo will automatically load your Google Ads data into BigQuery.
3. What’s the difference between Cloud SQL and BigQuery?
Cloud SQL is like a regular database where you store and manage transactional data, perfect for everyday operations. BigQuery is designed to analyze huge amounts of data quickly, making it ideal for large-scale reporting and analytics.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link












