



Airflow has emerged as a common component in the Data Engineering Pipelines in recent times. Started in 2014 by Airbnb, Airflow was developed to orchestrate and schedule user tasks contained in workflows.
Airflow is highly configurable and allows users to add custom Airflow hooks/operators and other plugins to help them implement custom workflows for their own use cases.
The objective of this post is to help the readers familiarize themselves with Airflow hooks and to get them started on using Airflow hooks. By the end of this post, you will be able to.
- Work with Airflow UI.
- Use Airflow hooks and implement DAGs.
- Create a workflow that fetches data from PostgreSQL and saves it as a CSV file.
Table of Contents
Prerequisites for Setting Up Airflow Hooks
Users must have the following applications installed on their system as a precondition for setting up Airflow hooks:
- Python 3.6 or above.
- Apache Airflow installed and configured to use.
- A PostgreSQL database with version 9.6 or above.
What is Airflow?

Airflow is an open-source Workflow Management Platform for implementing Data Engineering Pipelines. It helps in programmatically authoring, scheduling, and monitoring user workflows. It’s frequently used to gather data from a variety of sources, transform it, and then push it to other sources.
Airflow represents your workflows as Directed Acyclic Graphs (DAG). The Airflow Scheduler performs tasks specified by your DAGs using a collection of workers.
Airflow’s intuitive user interface helps you to visualize your Data Pipelines running in different environments, keep a watch on them and debug issues when they happen.
What are Airflow Hooks?
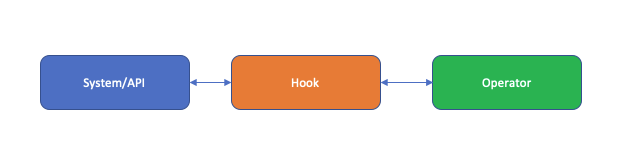
Airflow’s core functionality is managing workflows that involve fetching data, transforming it, and pushing it to other systems. Airflow hooks help in interfacing with external systems. It can help in connecting with external systems like S3, HDFC, MySQL, PostgreSQL, etc.
Airflow hooks help you to avoid spending time with the low-level API of the data sources. Airflow provides a number of built-in hooks that can connect with all the common data sources.
It also provides an interface for custom development of Airflow hooks in case you work with a database for which built-in hooks are not available.
How to run Airflow Hooks? Use These 5 Steps to Get Started
As mentioned earlier, Airflow provides multiple built-in Airflow hooks. For this tutorial, we will use the PostgreSQL hook provided by Airflow to extract the contents of a table into a CSV file. To do so, follow along with these steps:
Airflow Hooks Part 1: Prepare your PostgreSQL Environment
Step 1: You are first required to create a table in PostgreSQL and load some data. To do this, head to the psql shell and execute the command below.
CREATE TABLE customer(
id serial,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50)
);Here we are creating a customer table with four columns- id, first_name, last_name, and email.
Step 2: Now, create a CSV file using the format below:
serial,first_name,last_name,email
1,john,michael,john@gmail.com
2,mary,cooper,mcooper@gmail.com
3,sheldon,cooper,scopper@gmail.com
4,john,michael,john@gmail.com
5,mary,cooper,mcooper@gmail.com
6,sheldon,cooper,scopper@gmail.comStep 3: Save it as customers.csv and exit.
Step 4: Use the COPY command to insert the data into the customer table.
COPY customer FROM '/home/data/customer.csv' DELIMITER ',' CSV HEADER;Airflow Hooks Part 2: Start Airflow Webserver
You can use the command below to start the Airflow webserver.
Airflow webserver -p 8080After configuring the Airflow webserver, head to localhost:8080 to view your Airflow UI. You would be presented with a screen displaying your previous or newly run DAGs.
Airflow Hooks Part 3: Set up your PostgreSQL connection
Step 1: In the Airflow UI, head to the Admin tab and click on Connections to view all the connection identifiers already configured in your Airflow.
Airflow comes with a built-in connection identifier for PostgreSQL.
Step 2: Click on the postgres_default connection identifier and enter the details of your PostgreSQL connection.
Step 3: Click Save and your connection parameters will be saved.
Airflow Hooks Part 4: Implement your DAG using Airflow PostgreSQL Hook
To implement your DAG using PostgreSQL Airflow Hook, use the following step:
Copy the below snippet of code and save it as pg_extract.py.
| import logging from Airflow import DAG from datetime import datetime, timedelta from Airflow.providers.postgres.hooks.postgres import PostgresHook from Airflow.operators.python import PythonOperator # Change these to your identifiers, if needed. POSTGRES_CONN_ID = “postgres_default” def pg_extract(copy_sql): pg_hook = PostgresHook.get_hook(POSTGRES_CONN_ID) logging.info(“Exporting query to file”) pg_hook.copy_expert(copy_sql, filename=”/home/user/Airflow/data/customer.csv”) with DAG( dag_id=”pg_extract”, start_date=datetime.datetime(2022, 2, 2), schedule_interval=timedelta(days=1), catchup=False, ) as dag: t1 = PythonOperator( task_id=”pg_extract_task”, python_callable=pg_extract, op_kwargs={ “copy_sql”: “COPY (SELECT * FROM CUSTOMER WHERE first_name=’john’ ) TO STDOUT WITH CSV HEADER” } ) t1 |
For more clarification, have a look at the pg_extract function to understand how PostgreSQL Airflow hooks are used here. Using this Airflow hook, all of the boilerplate code to connect to PostgreSQL gets avoided. Only a Connection ID is required and no information of credentials is present in the code. The Connection Identifier is configured in the Connection section of the admin panel.
PostgreSQL Airflow hook exposes the copy_expert method that can take an SQL query and an output file to save the results. Here we have used the query to output the results as a CSV file.
With this, your DAG is configured to execute every day from a specific date.
Airflow Hooks Part 5: Run your DAG
After saving the python file in your DAG directory, the file has to be added to the Airflow index for it to be recognized as a DAG. The DAG directory is specified as dags_folder parameter in the Airflow.cfg file that is located in your installation directory. To add the file to the list of recognized DAGs, execute the command below.
Airflow db initNow, head to your Airflow UI and click on the name of the DAG.
You can then trigger the DAG using the ‘play’ button in the top right corner.
Once it is successfully executed, head to the directory configured for saving the file and you will be able to find the output CSV file.
That’s it. Airflow hooks are that easy to master. We have successfully used the PostgreSQL hook from Airflow to implement an extract job.
Limitations of Using Airflow Hooks
Airflow is capable of handling much more complex DAGs and task relationships. But its comprehensive feature set also means there is a steep learning curve in mastering Airflow. The lack of proper examples in the documentation does not help either. Here are some of the typical challenges that developers face while dealing with Airflow.
- Airflow workflows are based on hooks and operators. Even though there are many built-in and community-based hooks and operators available, support for SaaS offerings is limited in Airflow. If your team uses a lot of SaaS applications for running your business, developers will need to develop numerous Airflow hooks and plugins to deal with them.
- While Airflow has an intuitive UI, it is meant to monitor the jobs. The DAG definition is still based on code or configuration. On the other hand, ETL tools like Hevo Data can help you to implement ETL jobs in a few clicks without using code at all.
- Airflow is an on-premise installation-based solution. This means the developers have to spend time on managing the Airflow installation and maintaining them. Tools like Hevo are completely cloud-based and excuse developers from all the headaches involved in maintaining the infrastructure.
Conclusion
In summary, this blog presented a complete overview of developing and maintaining Airflow hooks, using one example of a PostgreSQL Airflow hook.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link


