



A relational database that supports procedural language allows you to assign a value to a local variable within stored procedures by using the SELECT statement. Teradata and Oracle databases, for example, support the SELECT INTO clause for assigning a value to a local variable.
In this article, we’ll look at how to use the Redshift SELECT INTO clause within Stored Procedures to assign a subquery value to a local variable.
In Redshift, the SELECT INTO statement retrieves data from one or more database tables and assigns the values to variables. To assign a previously declared variable within a stored procedure or a RECORD type variable, use the Redshift SELECT INTO.
Table of Contents
Introduction to Amazon Redshift
Amazon Redshift is a petabyte-scale data warehouse solution powered by Amazon Web Services. It is also used for large database migrations because it simplifies data management.
SELECT INTO Variable in Redshift
In Redshift, the SELECT INTO statement retrieves data from one or more database tables and assigns the values to variables. To assign a previously declared variable within a stored procedure or a RECORD type variable, use the Redshift SELECT INTO.
Redshift also selects and inserts rows from any query into a new table. You can choose between creating a temporary and a persistent table. This syntax is similar to the T-SQL SELECT INTO syntax used in Microsoft SQL Server.
Redshift SELECT INTO Syntax
Rows defined by any query are selected and inserted into a new table. You can choose between creating a temporary and a persistent table.
[ WITH with_subquery [, ...] ]
SELECT
[ TOP number ] [ ALL | DISTINCT ]
* | expression [ AS output_name ] [, ...]
INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table
[ FROM table_reference [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | { EXCEPT | MINUS } } [ ALL ] query ]
[ ORDER BY expression
[ ASC | DESC ]
[ LIMIT { number | ALL } ]
[ OFFSET start ]See below for more information on the parameters of this command.
- WITH: A WITH clause is an optional clause that comes before a query’s SELECT list. WITH specifies one or more common table expressions.
- SELECT: The SELECT list specifies the columns, functions, and expressions that the query should return. The query’s output is represented by the list.
- FROM: A query’s FROM clause lists the table references (tables, views, and subqueries) from which data is selected.
- WHERE: The WHERE clause includes conditions that either joins tables or apply predicates to table columns.
- GROUP BY: The GROUP BY clause specifies the query’s grouping columns.
- HAVING: The HAVING clause adds a condition to the intermediate grouped result set returned by a query.
- UNION, INTERSECT & EXCEPT: The set operators UNION, INTERSECT, and EXCEPT are used to compare and merge the results of two separate query expressions.
- ORDER BY: The ORDER BY clause sorts a query’s result set.
Redshift SELECT INTO Example
Create a NEW EVENT table by selecting all of the rows from the EVENT table:
select * into newevent from event;Enter the aggregate query result into a temporary table called PROFITS:
select username, lastname, sum(pricepaid-commission) as profit
into temp table profits
from sales, users
where sales.sellerid=users.userid
group by 1, 2
order by 3 desc;Another Example
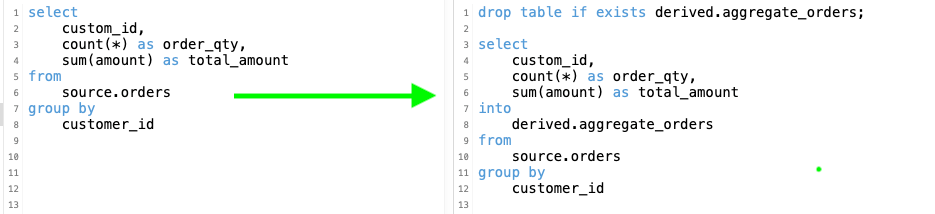
Conclusion
- This blog goes into great detail about the Redshift SELECT INTO statement.
- It also provides an overview of Amazon Redshift before delving into the Redshift SELECT INTO statement. Utilize Redshift’s capabilities to select data into variables, enabling dynamic and efficient data processing.
- The Redshift SELECT INTO command is simple to use and follows the PostgreSQL querying protocol. However, the user should be aware of some limitations. Most of the time, the query validation will not return an error. It may carry out its own automatic conversions.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



