



According to the World Economic Forum*, by 2025, the world is expected to generate 463 exabytes of data each day. Here are some key daily statistics:
- 500 million tweets are sent
- 294 billion emails are sent
- 4 petabytes of data is created on Facebook
- 4 terabytes of data is created from each connected car
- 65 billion messages are sent on WhatsApp
- 5 billion searches are made
If you’re working with big data, you know how important it is to have a reliable and flexible table format. That’s where Apache Iceberg comes in. Iceberg is a game-changer for managing large datasets, offering better performance, scalability, and simplicity compared to older formats like Hive.
In this blog, I’ll walk you through what Apache Iceberg Table Format is, why it’s become so popular, and how it can help you manage your data more efficiently, especially in modern data lakes and lakehouses. Let’s dive in and explore the key benefits of using Iceberg!
Table of Contents
What is Apache Iceberg?
Initially developed at Netflix to address challenges with massive tables, Iceberg was open-sourced in 2018 as an Apache Incubator project. Apache Iceberg is an open table format designed for managing petabyte-scale tables.
It serves as an abstraction layer between the physical data files (such as those written in Parquet or ORC) and their organization into a table structure. This format addresses challenges in data lakes, making data management more efficient and reliable, and becoming a promising replacement for the traditional Hive table format. With over 25 million terabytes of data stored in Hive, migrating to Iceberg is crucial for improved performance and cost efficiency.
Managing large datasets is now more efficient than ever. Hevo now supports Apache Iceberg as a destination, helping you easily build a scalable, high-performance data lakehouse.
Why Apache Iceberg?
- Optimized Performance – Smart metadata management ensures Hevo processes only the necessary files, reducing scan times.
- Schema and Partition Evolution – Make changes without breaking pipelines or requiring complex migrations.
- ACID Transactions and Time Travel – Query historical data and roll back to previous states seamlessly.
With Hevo and Iceberg, you get a flexible, efficient, and scalable approach to data management.
Get Started with Hevo for FreeWhat Is Table Format And How It Is Different From File Format?
A table format is a high-level abstraction that organizes and manages large datasets in a structured way, handling how data is stored, updated, and queried. It enables features like schema evolution, partitioning, and ACID (Atomicity, Consistency, Isolation, Durability) transactions, which help with version control and data consistency across large-scale operations.
On the other hand, a file format defines how the actual data is stored on disk. Examples of file formats include Parquet, ORC, and Avro. These formats focus on how the data is serialized and compressed for storage and efficient retrieval.
Read about the comparison between two famous table and file format tools- Apache Iceberg vs Parquet.
| Feature | Table Format | File Format |
| Schema Evolution | Supports schema changes without breaking compatibility | Limited or no schema change support |
| ACID Transactions | Supports full ACID compliance (atomic updates, consistency) | Does not inherently support ACID transactions |
| Partitioning | Advanced partitioning and indexing support | Basic partitioning (defined at write-time) |
| Query Optimization | Provides additional query optimizations | Optimizes data retrieval at storage level |
| Purpose | Manages table structure, transactions, and schema evolution | Organizes the way data is stored on disk |
| Use Cases | Ideal for large, dynamic datasets requiring updates and complex queries | Best for raw data storage with basic queries |
Getting started with Iceberg table format
Prerequisites
Before you begin, ensure you have the following installed on your machine:
- Java Development Kit (JDK) 8 or later
- Apache Spark 3.0 or later
- Python 3.6 or later
- Maven (for building Iceberg)
Installation guide
Step 1: Download Apache Spark
- Go to the Apache Spark download page.
- Choose the latest version and download it.
Step 2: Extract the Spark archive
tar -xvf spark-3.1.2-bin-hadoop3.2.tgzStep 3: Set environment variables
export SPARK_HOME=~/spark-3.1.2-bin-hadoop3.2
export PATH=$SPARK_HOME/bin:$PATHStep 4: Install PySpark
pip install pysparkStep 5: Clone Apache Iceberg repository
git clone https://github.com/iceberg.git
cd icebergStep 6: Build Iceberg using Maven
./gradlew buildStep 7: Create a configuration file for Spark (e.g., ‘spark-defaults.conf’)
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionsExtensions
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.spark_catalog.type=hadoop
spark.sql.catalog.spark_catalog.warehouse=/path/to/wStep 8: Start PySpark with Iceberg
pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.spark_catalog.type=hadoop \
--conf spark.sql.catalog.spark_catalog.warehouse=/path/to/warehouseCreating and Querying your First Iceberg Table
1. Initialize a SparkSession with Iceberg:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("IcebergExample") \
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.spark_catalog.type", "hadoop") \
.config("spark.sql.catalog.spark_catalog.warehouse", "/path/to/warehouse") \
.getOrCreate()2. Create a table:
spark.sql("""
CREATE TABLE spark_catalog.db.table (
id BIGINT,
data STRING,
category STRING
)
USING iceberg
""")3. Insert data into the table:
spark.sql("""
INSERT INTO spark_catalog.db.table VALUES
(1, 'data1', 'A'),
(2, 'data2', 'B'),
(3, 'data3', 'A')
""")4. Query the table:
spark.sql("SELECT * FROM spark_catalog.db.table").show()Features of Iceberg Table Format
1. Schema Evolution
Iceberg provides robust support for schema evolution, ensuring that changes to the table schema are applied without breaking compatibility. It ensures schema changes are isolated and do not cause unintended issues. Each field in the schema is uniquely identified by an ID, allowing field names to be changed without affecting how Iceberg reads data using these IDs.
Examples of modifying table schemas:
#Adding a new column
spark.sql("""
ALTER TABLE spark_catalog.db.table ADD Column new_col STRING
""")#Deleting an existing column
spark.sql("""
ALTER TABLE spark_catalog.db.table DROP COLUMN new_col
""")#Renaming an existing column
spark.sql("""
ALTER TABLE sprak_catalog.db.table RENAME COLUMN data TO new_data
""")#Changing an 'int' column to 'long'
spark.sql("""
ALTER TABLE spark_catalog.db.table ALTER COLUMN id TYPE BIGINT2. Hidden Partitioning and Partition Evolution
Iceberg’s hidden partitioning feature allows partition specification evolution without disrupting table integrity. This means you can adjust how data is partitioned—changing granularity or partition columns—without table breaks. Unlike rewriting files, this metadata operation lets old and new data coexist. Iceberg achieves this through split planning: executing queries separately for old and new specifications, then merging the results into a cohesive table view.
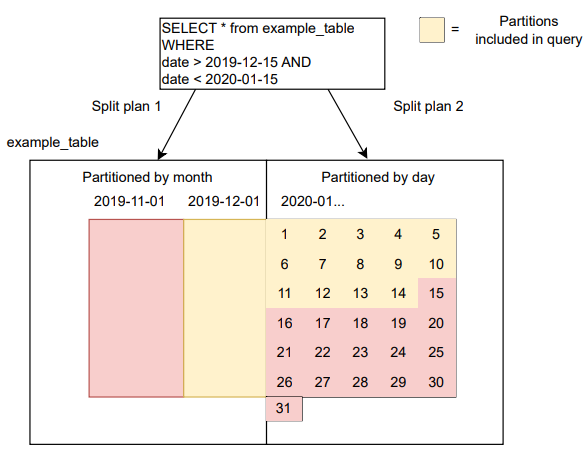
In this figure, the ‘example_table’ is initially partitioned by month(date) until 2020-01-01, after which it switches to day(date). The old data remains in the previous partition format, while the new data adopts the new format. When the query is executed, Iceberg performs split planning for each partition specification, filtering partitions under both specifications by applying the appropriate transform (month or day) to the date column.
3. Time Travel and Rollback
The time travel feature of Iceberg allows querying data snapshots at different timestamps and supports easy rollback to previous states, enhancing data auditing, debugging, and reliability. Snapshots capture the state of a table at a specific point in time. Time travel allows users to query historical data by referencing these snapshots.
Snapshot log data can be accessed using Spark:
#Specify the Iceberg table
iceberg_table = "spark_catalog.default.booking_table"#Load the snapshot log data
snapshot_log_df = spark.read.format("iceberg").load(f"{iceberg_table}.snapshots")The result will be something like this:

If you want to rollback your table to an earlier version:
#snapshot_id or timestamp to rollback to
rollback_snapshot_id = '1234567891'#Rollback the Iceberg table to the identified snapshot
spark.sql(f"ALTER TABLE {iceberg_table} RESTORE SNAPSHOT '{rollback_snapshot_id}'")#Querying historical data
snapshot_id = "1234567892"
spark.sql(f"SELECT * FROM {iceberg_table}.snapshots WHERE snapshot_id = '{snapshot_id}'")4. Manifest Files
Manifest files contain a list of paths to related data files. Each entry for a data file includes some metadata about the file, including statistics. This helps in efficient query planning and execution.
5. ACID Transactions
Iceberg ensures data consistency and supports ACID (Atomicity, Consistency, Isolation, and Durability) transactions, making it reliable for concurrent data operations.
Challenges and Considerations for Iceberg Table Format
Common Pitfalls
- Misconfigured environments: Evolving APIs of Iceberg and compatibility issues with existing systems may pose challenges during adoption.
- Improper schema management: Managing schema changes effectively is crucial; improper handling can lead to data integrity issues or performance degradation.
Best Practices
- Regularly update Iceberg versions
- Monitor and optimize query performance
For reliable best practices and guidelines, check the official Apache Iceberg documentation and community resources:

Real-world Applications and Brief Case Studies of Companies using Iceberg
Netflix and Adobe are notable companies that use Iceberg to manage their vast data lakes efficiently.
1. Iceberg at Netflix
Netflix created Iceberg in 2018 to address the performance issues and usability challenges of using Apache Hive tables.
Key Benefits Utilized by Netflix:
- Schema evolution: The support for schema evolution of Iceberg allows Netflix to modify table schemas without downtime, which is crucial for continuous data availability and evolving business requirements.
- Performance optimization: Efficient file pruning and metadata management, helped to improve query performance for Netflix’s large datasets.
- Transactional consistency: Netflix relies on Iceberg’s transactional guarantees to ensure data consistency across various data operations, and to maintain data integrity.
- Integration with existing workflows: Iceberg integrates seamlessly with Netflix’s existing data processing frameworks, to effectively support batch and streaming data workflows.
Partition Entropy (PE) / File Size Entropy (FSE): Netflix introduced a concept called Partition Entropy (PE) to optimize data processing further. This includes File Size Entropy (FSE), which uses Mean Squared Error (MSE) calculations to manage partition file sizes efficiently.
- Definition of FSE/MSE: FSE/MSE for a partition is calculated using:
MSE=1Ni=1N(min(Actuali, Target))2
Where N is the number of files in the partition, Target is the target file size, and Actuali is the size of each file.
- Implementation in workflow: During snapshot scans, Netflix updates the MSE’ for changed partitions using:
MSE’=1N(NMSE+i=1M(min(Actuali, Target))2)
Where M is the number of files added in the snapshot. A tolerance threshold T is applied, skipping further processing if MSE < T2, reducing full partition scans and merge operations.
Netflix integrates PE/FSE calculations seamlessly with the metadata management and optimization capabilities of Iceberg.
2. Iceberg at Adobe: A Case Study
Adobe, a global leader in digital media and marketing solutions, has embraced Apache Iceberg to streamline its data management processes. This case study highlights how Adobe integrated Iceberg into its data infrastructure and the benefits realized from this adoption.
The Challenge
Adobe faced significant challenges with its legacy data management systems, particularly with data consistency, schema evolution, and efficient querying across large datasets. Traditional file formats and table management systems struggled to meet Adobe’s growing data needs, leading to inefficiencies and increased operational overhead.
The Solution
To address these challenges, Adobe implemented Apache Iceberg to manage large analytic datasets. Iceberg provided a robust solution to the data management issues faced by Adobe with its schema evolution, partitioning, and time travel.
Key Benefits
- Improved data consistency and reliability: The support for ACID transactions ensured that data operations were consistent and reliable, significantly reducing data corruption issues.
- Efficient schema evolution: With Iceberg, Adobe could easily evolve its data schemas without downtime or complex migrations, allowing for more agile and responsive data management.
- Optimized query performance: The advanced partitioning and metadata management and optimized query performance, enabled faster and more efficient data retrieval.
- Enhanced data governance: The comprehensive metadata layer and time travel capabilities of Iceberg improved data governance, allowing Adobe to audit and revert data changes as needed.
The case study illustrates how innovative features provided by Apache Iceberg significantly enhance data consistency, performance, and governance. The case study can help other organizations facing similar challenges to explore the benefits of Iceberg and consider its adoption in their data infrastructure.


Conclusion
This article introduces Apache Iceberg, guiding readers through its installation and table format to build a solid understanding of efficient data management. It has significantly helped reduce complexities for Data Scientists and Engineers, by streamlining and accelerating the end-to-end data pipeline. The ongoing innovations and improvements in Iceberg, driven by an active and collaborative community, are continually refining its capabilities. Explore the role of an Iceberg catalog in organizing and tracking table metadata. Discover efficient ways to transfer data from Postgres to Iceberg for improved scalability.
Organizations like Adobe and many others are contributing to the growth and development of Iceberg. This collaborative effort within the larger Apache Open Source community is vital for tackling emerging challenges and introducing new features. As Iceberg continues to evolve, the community’s dedication and contributions ensure that it remains at the forefront of modern data management solutions, offering robust and scalable options for the future.
Follow the Iceberg Official Site for the latest news and more resources.
Schedule a demo with Hevo to automate data pipelines for efficient data movement.
Frequently Asked Questions
1. What is the format of Iceberg table data?
Apache Iceberg stores table data in columnar formats like Parquet, ORC, or Avro. These formats are optimized for big data processing, providing efficient storage and fast query performance.
2. What is the difference between Snowflake table and Iceberg table?
Snowflake Table: Data is managed and stored within the proprietary Snowflake environment, with storage and compute being tightly integrated.
Iceberg Table: Iceberg tables are open format and stored in external object storage (e.g., AWS S3, Azure Blob) while supporting different compute engines like Spark, Flink, Trino, and Presto.
3. What are the disadvantages of Apache Iceberg?
-complexity
-Lack of fully managed services
-Performance Tuning.
-Integration overhead
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





