

Businesses are increasingly investing in data lakehouses due to their reduced costs, streamlined workloads, support for real-time data processing, and better decision-making. The global data lakehouse market is estimated to be around USD 8.9 billion in 2023. Market research surveys1 predict a CAGR of 22.9% from 2024 to 2033, making the estimated market at around USD 66.4 billion by 2033.
Over the years, data landscapes have evolved from data warehouses to data lakes, and the recent progression has been to data lakehouses. A data lakehouse is a new data architecture that combines the best features of data lakes and data warehouses, offering unified and cost-effective data storage with support for ACID transactions and robust data analytics.
This blog provides a detailed overview of Apache Iceberg vs Delta Lake, two leading data lakehouse solutions. It focuses on their key features, benefits, and specific use cases to aid data engineers, architects, and IT decision-makers in making an informed choice.
Table of Contents
How Do Data Lakehouses Bridge Data Warehouses and Data Lakes?
Data warehouses have long been used in business intelligence and decision support, but they were often expensive and inefficient when dealing with unorganized and semi-structured data.
On the other hand, data lakes were created to store raw data in different forms efficiently and cheaply. They are primarily used in data science and machine learning scenarios. However, they lack several critical features that data warehouses provide, like ACID transactions, data quality control, consistency, and isolation. This makes it difficult for jobs that process data.
In the standard two-tier data architecture, data teams connect these systems to make business intelligence (BI) and machine learning (ML) work across the data in both. This creates duplicate data, extra infrastructure costs, security issues, and high operational costs.
A data lakehouse is a new way to handle data that combines the adaptability, low cost, and large size of data lakes with the analytical power, data management, and ACID transactions of data warehouses. The objective is to use the strengths of the data warehouse to produce insights quickly from processed merged data and of the data lake to ingest and store high-speed unstructured data with post-storage transformation and analytics capabilities. This lets all data be used for business intelligence (BI) and machine learning (ML).
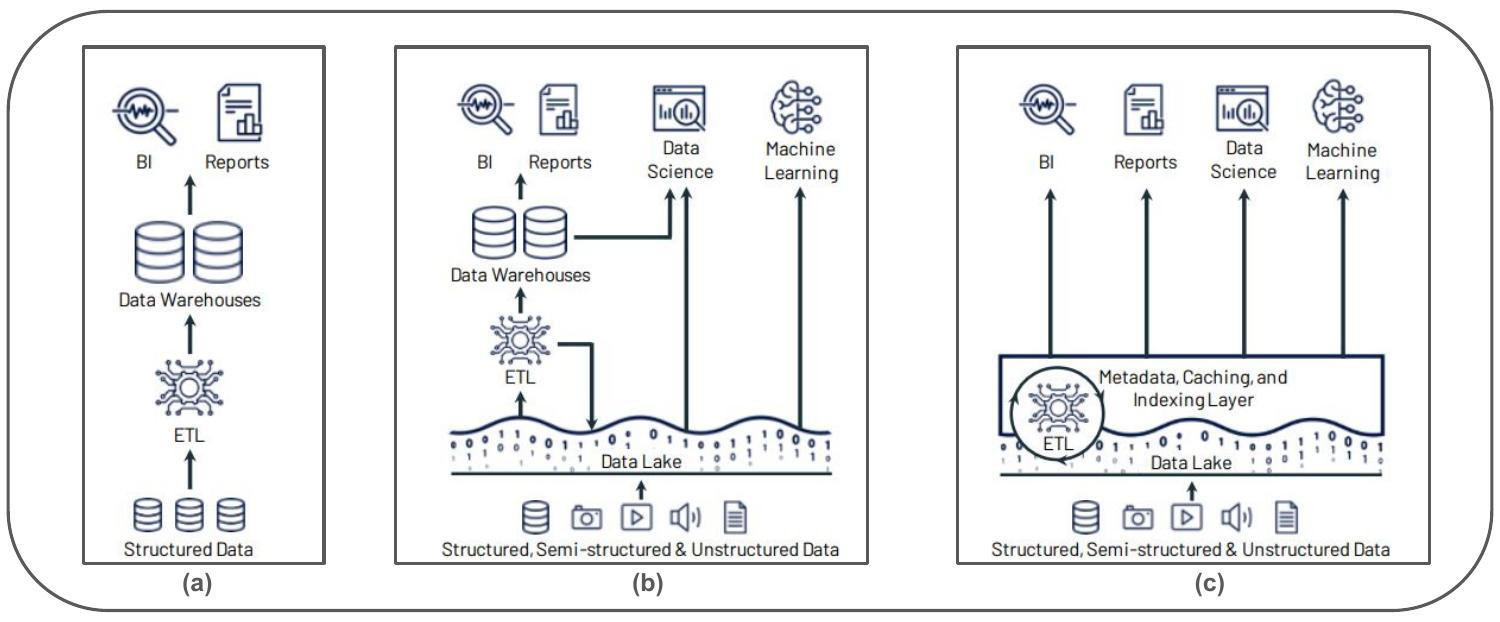
Some significant technological advances that made data lakehouse design possible are,
- Metadata Layers: Adding a metadata layer on top of open file formats (like Parquet) gives data lakehouses more control options like ACID-compliant transactions. These metadata layers also support streaming I/O, time travel to older versions, schema enforcement, and data validation.
- Low-Cost Object Storage: Storing data in a low-cost object store (like Amazon S3) similar to data lakes using a standard file format and with a transactional metadata layer on top of that, enables features like ACID transactions and versioning without compromising storage costs.
- Query Engine Optimizations: A new query engine design helps execute SQL queries quickly on data lakes. These engines include improvements like caching, better data layouts, extra data structures like statistics and indexes, and vectorized execution on current CPUs to make things run faster.
- Declarative DataFrame APIs: Integration with ML libraries through DataFrame APIs allows for better optimization opportunities and accelerates ML processes.
Managing large datasets is now more efficient than ever. Hevo now supports Apache Iceberg as a destination, helping you easily build a scalable, high-performance data lakehouse.
Why Apache Iceberg?
- Optimized Performance – Smart metadata management ensures Hevo processes only the necessary files, reducing scan times.
- Schema and Partition Evolution – Make changes without breaking pipelines or requiring complex migrations.
- ACID Transactions and Time Travel – Query historical data and roll back to previous states seamlessly.
With Hevo and Iceberg, you get a flexible, efficient, and scalable approach to data management. Sign up for a free trial today.
Get Started with Hevo for FreeWhat is the Apache Iceberg?

Apache Iceberg is a high-performance format for huge analytic tables. It brings the reliability and simplicity of SQL tables to big data while allowing engines like Spark, Trino, Flink, Presto, Hive, and Impala to work safely with the same tables simultaneously.
Iceberg was developed as an internal project at Netflix to handle its internal data infrastructure. As a leading provider of streaming data and content, Netflix dealt with large amounts of data and faced data lake challenges like ACID compliance, schema evolution over time, and reverting back or querying from older table versions.
These challenges in processing and storing big data cost-effectively led to the development of Iceberg, which improves older formats like Parquet and ORC and introduces features for better data lake management. Later realising its potential, Netflix open-sourced Apache Icebergader and contributed it to the Apache Software Foundation in 2019.
Iceberg supports schema evolution and versioning with the help of metadata data manifest, which decouples the table schema from its data files. This metadata-separate approach supports partitioning pruning, a key feature of Iceberg, where irrelevant partitions and files are automatically removed. It also supports time traveling to previous versions using table snapshots and version rollback to quickly correct problems by resetting tables to earlier states.
Basic Architecture of Apache Iceberg:
- Table Format: Metadata is stored in table format, and a manifest list and manifest files are used to track metadata, facilitating efficient handling of large datasets.
- Snapshot Management: Maintains a history of snapshots for time travel and rollback capabilities.
- Partitioning: Employs hidden partitioning to simplify partition management and enhance performance.
Key Features of Apache Iceberg:
- Schema Evolution: Columns can be added, dropped, or reordered without any extra overhead of dropping and recreating tables. Schema changes are so easy that no table or data is rewritten.
- Snapshot Isolation: The data consistency and transaction isolation are guaranteed by preventing interference between readers and writers in a multiuser environment. Ensures ACID compliance and data correctness
- Efficient Metadata Management: Data lineage and schema information are stored separately and utilized to manage large-scale tables efficiently, reducing overhead.
- Hidden partitioning and Partition Pruning: Data partitioning is handled without explicit user involvement. Irrelevant partitions and files are automatically removed during queries, optimizing performance.
- Data Compaction: Different compression strategies are supported for Improved storage efficiency and query response times.
What is Delta Lake?

Delta Lake is a scalable storage layer for data lakes that extends Apache Spark with file-based transaction logs for ACID transaction support and time travel support for querying historical data. It supports both stream and batch operations and incremental processing at scale.
Delta Lake was developed by Databricks and first released to customers in 2017. Later, they open-sourced the project in 2019, which is now governed by the Linux Foundation. It has played a pivotal role in initiating the data lakehouse movement, significantly enhancing the reliability and performance of data lakes.
Delta Lake’s robust data management ensures data lineage and versioning. Its core strength lies in its ability to log changes to a table’s data and metadata in JSON-formatted delta logs. Delta Lake records changes using JSON-based logs called Delta logs. These log files are then merged as a Parquet “checkpoint” file that saves the entire state of the table to prevent costly log file traversals. Delta Lakes’ auto-compaction feature helps optimize storage and query performance.
Basic Architecture of Delta Lake:
- Delta Logs: Records changes to a table’s data and metadata as JSON-formatted delta logs, ensuring comprehensive records of all data modifications.
- Merge-on-Write: Employs a merge-on-write strategy for updates, ensuring high performance and consistency.
- Parquet Checkpoint Files: Creates checkpoint files to summarize older delta logs, maintaining a permanent record of a table’s change history
Key Features of Delta Lake:
- ACID Transactions: Guarantees data integrity with robust transactional support.
- Schema Enforcement: The schema is verified automatically before a write operation to ensure schema compliance.
- Time Travel: The detailed delta logs enable querying of historical data and audit trail creation.
- Unified Batch and Streaming: Supports both batch and streaming data in a single pipeline.
- Real-time Analytics: The time versioning support along with batch and streaming support makes it the best option for real-time analytics
- Optimized Storage: Efficient data storage with Delta Engine and indexing.
What are the Key Comparisons for Apache Iceberg vs Delta Lake
 | ||
| Focus | Open-source and vendor-neutral | Closely associated with Databricks |
| Ideal for | Large datasets and Open environments | High-demand workloads, Time travel needs, real-time processing |
| Data Formats | Supports AVRO, ORC, Parquet(flexible) | Parquet |
| Cloud services | Independent. Integrates with various platform(Apache Spark, Flink, Hive) | Tight integration with Databricks and Azure |
| Transaction(ACID) Support | Yes | Yes |
| Metadata management | distributed approach with manifest files | centralized approach with the delta log. |
| Data Consistency | Uses a merge-on-read strategy | Uses a merge-on-write strategy |
| Implications for Read | Potentially slower reads due to on-the-fly merging | Faster reads due to pre-merged data |
| Implications for Write | More efficient writes with deferred merging | Immediate consistency with higher write overhead |
| Schema evolution | Yes- Saves schema changes as metadata | Yes- Schemas are stored in the delta log |
| Partition Evolution | Yes. Supports dynamic partitioning without table rewrites. | No. (recent versions have some support) |
| Batch and Streaming Support | Works with batch-processing engines | Supports both batch and streaming data |
| Data versioning | Yes | Yes |
| Time travel queries | Yes. Allows querying old data versions | Yes. Supports querying historical data |
| Performance | Optimized for scalable operations with advanced partitioning | High performance with Delta Engine and effective indexing |
| Cost Considerations | Fully open-source, potentially lower costs | May involve additional costs for enterprise features |
| Application | Suitable for scenarios where write operations are frequent, and it is acceptable to have slightly slower reads | Ideal for read-heavy workloads and scenarios requiring high query performance and consistency. |
| Industry Use cases | Transactional data lakes, data versioning, incremental processing | Real-time data processing, data warehousing, machine learning pipelines |
Performance and Scalability
While Apache Iceberg is optimized for scalable data lake operations with features like advanced partitioning and data compaction, Delta Lake offers high performance with the Delta Engine, auto compaction, and effective indexing, enabling faster query execution. Although Iceberg has comparable performance, it may fall behind Delta Lake in certain criteria. In particular, Delta Lake has proven to be faster than Iceberg in loading and querying tables. It is also faster when loading data from Parquet.
Data Consistency and Reliability
Both Apache Iceberg and Delta Lake ensure strong data consistency through ACID transactions and data versioning. Iceberg uses a merge-on-read strategy, while Delta Lake uses merge-on-write, each with different implications for performance and data management. Iceberg provides robust schema evolution support. Delta Lake also ensures schema compliance.
Integration and Compatibility
Apache Iceberg is very flexible with wide compatibility. It supports various data processing engines such as Apache Spark, Flink, and Hive, and supports multiple data formats including Avro, ORC, and Parquet. This broad compatibility makes Iceberg versatile for diverse data ecosystems. Delta Lake is deeply integrated with Apache Spark and the Databricks ecosystem. It supports only the Parquet format. This integration provides robust performance within the Databricks environment but limits flexibility in terms of format compatibility.
Governance and Security
Both Apache Iceberg and Delta Lake provide robust governance and security features. Iceberg offers comprehensive data versioning and auditability, ensuring better oversight and control over data changes. Delta Lake provides strong schema enforcement and the ability to perform historical data queries, which are essential for meeting compliance requirements and ensuring data governance.
Cost Considerations
Apache Iceberg is fully open source and open standard and can potentially lower costs depending on cloud storage and compute usage. It does not tie users to any specific vendor and hence has reduced the risk of vendor lock-in. Delta Lake, while offering powerful capabilities, is integrated with Databricks, which may involve additional costs for enterprise features.
Futureproofing
Being open source and compatible with wide technologies Apaches Iceberg positions it well for evolving with the industry trends. It is supported by a collaborative broader community . Delta Lake due to its strong tie to the Databricks ecosystem may pose a challenge in terms of reliance on a single provider and centralization
Why Choose Apache Iceberg?
Advantages of Apache Iceberg
- Open-source flexibility and lower cost.
- Advanced schema and partition management.
- Better integration with multiple data processing engines.
Specific Scenarios Where Iceberg Excels
- Organizations need flexible schema evolution.
- Enterprises using a mix of data processing engines.
- Cost-sensitive projects requiring open-source solutions.
Apache Iceberg Use Cases:
- Financial Services: Ideal for handling large-scale transactional data with ACID guarantees, making it suitable for financial applications.
- E-commerce Analytics: Can effectively manage vast amounts of user data, enabling advanced analytics and personalized recommendations.
Why Choose Delta Lake?
Advantages of Delta Lake
- Robust performance with Delta Engine.
- Seamless integration with Apache Spark.
- Unified batch and streaming data processing.
Specific Scenarios Where Delta Lake Excels
- Heavy Apache Spark users.
- Real-time data processing requirements.
- Enterprises leveraging Databricks for analytics.
Delta Lake Use Cases:
- Real-Time Analytics: Its time travel and versioning features make it perfect for real-time data processing and analytics.
- Data Lakes in Cloud Environments: With its high scalability and integration with cloud services, Delta Lake is well-suited for managing cloud-based data lakes.

Learn More About:
Avro vs Parquet: Detailed Comparison
Conclusion
Both Apache Iceberg and Delta Lake are solid solutions for data lakehouse systems, with their own advantages and disadvantages. Apache Iceberg is popular due to its open-source nature, broad compatibility, and community-driven development. Delta Lake excels at performance and integration within the Databricks ecosystem.
The choice between the two will be based on specific requirements such as openness, compatibility, performance, and cost. Assess the size of your project and its specific data processing requirements to discover which technology is most suited to your needs.
If a project prioritizes a community-driven, vendor-neutral standard for table metadata to avoid lock-in, Apache Iceberg is a suitable choice. Conversely, Delta Lake stands out for projects where high scalability and reliability are crucial.
To effectively integrate with Apache Iceberg and Delta Lake, you need clean and consistent data. Hevo is a no-code data pipeline platform that not only facilitates seamless integration but also enriches your data, ensuring it meets the highest standards for analysis. With Hevo, you can streamline your data management processes and unlock the full potential of your data lakehouse solutions. Sign up for Hevo’s 14-day free trial and experience seamless data migration.
Frequently Asked Questions
1. What is the primary difference between Apache Iceberg and Delta Lake?
Apache Iceberg and Delta Lake primarily differ in their flexibility and compatibility with data formats and tools. Iceberg is an open-source and open-standard tool compatible with broader platforms and data formats. At the same time, Delta Lake is closely associated with data bricks and parquet file format. The merge-on-read strategy is also used in Icebereg, while Delta Lake employs a merge-on-write approach.
2. What are the limitations or challenges of using Apache Iceberg and Delta Lake?
a. Apache Iceberg can be complex to implement and manage, particularly for organizations without extensive big data expertise. In specific scenarios, performance may not always match that of Delta Lake.
b. Delta Lake may involve additional costs for enterprise features and can lead to vendor lock-in. Its relia
3. Who uses Apache Iceberg?
Apache Iceberg is widely adopted by organizations seeking a high-performance, open-source table format for managing large-scale datasets.
4. Is Apache Parquet human-readable? Why use Parquet for data lake?
Apache Parquet is not human-readable. It is a columnar storage file format optimized for efficiency in terms of storage and performance, making it suitable for large-scale data processing. Parquet is widely chosen for data lakes due to its support for schema evolution and compatibility with major big data frameworks like Apache Spark, Hive, and Dril.
5. Is Delta Lake part of Databricks?
Delta Lake, originally developed by Databricks, is now an open-source project under the Linux Foundation, yet it retains strong integration with Databricks.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




